一、前言
http_load是一款测试web服务器性能的开源工具,从下面的网址可以下载到最新版本的http_load:
http://www.acme.com/software/http_load/ (页面实在太简陋……)
十分令人欣慰的是,这个软件一直在保持着更新(不像webbench,已经是十年的老古董了。webbench的源码分析请参考:http://www.cnblogs.com/xuning/p/3888699.html ),并且更新频率还蛮高的样子。我在下载了2014年8月2号的版本后,紧接着8月14号再查看,就又有了一个新的版本。这篇文章分析的http load版本是“http_load 02aug2014”,好在每个版本之间差别非常小,本文还是具有较好的通用性的。
二、使用方法
下载并解压缩之后,进入工具的根目录直接make,就可以得到可执行的工具。其使用方法如下图所示:

图中所示的url.txt内容是若干url链接,每行一个,比如:http://127.0.0.1:80/index.html。
详细说明一下使用格式:
./http_load [-checksum] [-throttle] [-proxy host:port] [-verbose] [timeout secs] [-sip sip_file]
-parallel N | -rate N [-jitter]
-fetches N | -seconds N
url_file
选项与参数:
-fetches:总计要访问url的次数,无论成功失败都记为一次,到达数量后程序退出。
-rate:每秒访问的次数(即访问频率),控制性能测试的速度。
-seconds:工具运行的时间,到达seconds设置的时间后程序退出。
-parallel:最大并发访问的数目,控制性能测试的速度。
-verbose:使用该选项后,每60秒会在屏幕上打印一次当前测试的进度信息。
-jitter:该选项必须与-rate同时使用,表示实际的访问频率会在rate设置的值上下随机波动10%的幅度。
-checksum:由于要访问某个url很多次,为了保证每次访问时收到的服务器回包内容都一样,可以采用checksum检查,不一致会在屏幕上输出错误信息。
-cipher:使用SSL层的时候会用到此参数(url是https开头),使用特定的密码集。
-timeout:设置超时时间,以秒为单位,默认为60秒。每超过一次则记为一次超时的连接
-proxy:设置web代理,格式为-proxy host:port
-throttle:限流模式,限制每秒收到的数据量,单位bytes/sec。该模式下默认限制为3360bytes/sec。
-sip:指定一个source ip文件,该文件每一行都是ip+port的形式。
需要特别说明的是,-parallel参数和-rate参数中必须有一个,用于指定发请求包的方式;-fetches和-seconds两个参数必须有一个,用于指定程序的终止条件。
三、与webbench的对比
webbench是另外一款网页性能测试工具,它的源码分析可以参考如下连接:
http://www.cnblogs.com/xuning/p/3888699.html
webbench采用多进程发包,最多支持3万并发量,而http_load采用单一进程并行复用方式发包。由于只有一个进程,http_load对于机器资源消耗较小,性能要求不高,但它的劣势就是最大并发量比webbench要少许多,只能达到千的量级。在很多场景中,几千的量级也已经绰绰有余了,因此具体工具的选用还要看实际情况。
我们分别使用webbench和http_load对同一个URL进行压力访问,结果如下。
[horstxu@vps ~/webbench-1.5]$ ./webbench -t 30 -c 1000 http://127.0.0.1:8080/user.png Webbench - Simple Web Benchmark 1.5 Copyright (c) Radim Kolar 1997-2004, GPL Open Source Software. Benchmarking: GET http://127.0.0.1:8080/user.png 1000 clients, running 30 sec. Speed=180340 pages/min, 5268934 bytes/sec. Requests: 90170 susceed, 0 failed. [horstxu@vps ~/http_load-02aug2014]$ ./http_load -parallel 1000 -fetches 90000 url.txt 90000 fetches, 830 max parallel, 1.2933e+08 bytes, in 30.5439 seconds 1437 mean bytes/connection 2946.58 fetches/sec, 4.23424e+06 bytes/sec msecs/connect: 0.772754 mean, 215 max, 0.025 min msecs/first-response: 17.2259 mean, 288.007 max, 1.735 min HTTP response codes: code 200 – 90000
如果进行一下换算,webbench测得的页面RPS为180340 pages/min = 3006rps,这与http_load的测试结果2946fetches/sec结果是很接近的,并且,http_load统计数据更加全面,数据校验也更加完善。对于每秒流量数据,webbench的结果是5268934bytes/sec,http_load是4234240bytes/sec。这其中的差别在于,http_load在统计时剔除了http报文的头部(head),而webbench是没有剔除头部的。接下来我们来领略一下http_load的实现原理。
四、工作流程
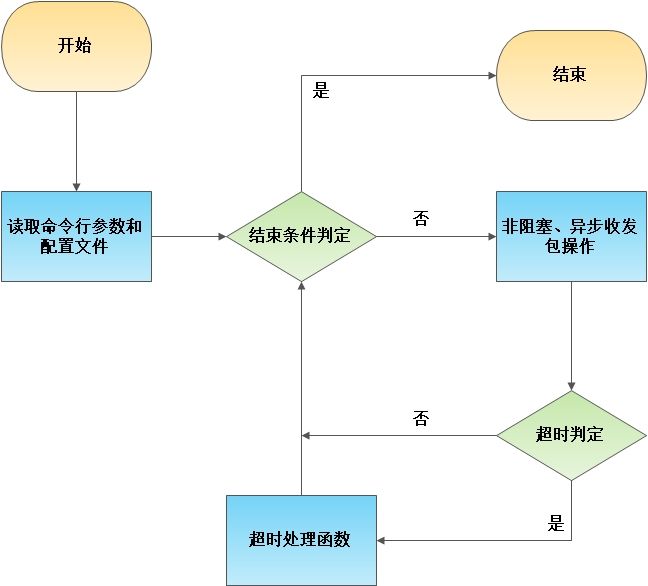
程序的工作流程可以用下面这幅图来表示,执行时程序主要环节位于流程图中的循环内。http_load为单一进程的程序,因此进程内的所有调用都是非阻塞方式进行, 保证程序的流畅度。程序的执行过程主体在一个大循环当中,不间断进行结束条件的判定和超时判定。时间管理方式是使用拉链式哈希表,超时情况下即运行超时处理函数。
五、原理分析
5.1 程序执行过程解析
如果使用简化的代码来描述上一节所述的流程图,可以参考下图。流程图中的循环也就是主函数中的for循环。在主循环内主要做4件事情。首先,检测当前程序是否满足终止条件,如果满足,则调用结束函数退出程序,否则进行下一步。然后,采用select监听描述符状态,一旦出现可读或可写状态的描述符,则采用handle_connect与handle_read两函数分别进行处理。需要提醒的是,源程序在处理读取socket缓冲区这一段为了完美剔除掉http请求报文的头部,耗费了大量的代码。再然后,循环尾部执行超时检测,检查当前时间有没有超过在哈希表中注册的每一个时间戳,如果超过,则要执行其对应的超时处理函数。具体的时间戳管理方法见下文。源码中共有5种时间戳需要注册,分别对应着5个超时处理函数,请参考图中的超时处理函数集合。

5.2 三个重要的结构体
下图中详细描述了三个源码中最为重要的结构体。首先,程序采用全局变量connections数组控制每一个TCP连接,connections数组中每个元素都是一个指向connection结构体的指针。connection结构体包含了用于记录测试数据的变量,连接状态的控制变量,以及最开始从文件中读取的连接配置信息。第二个结构体为url结构体,在http_load当中,想要请求的url存储在文件内,可以大于一个。这些URL的信息会被读取至由指向url结构体的指针组成的urls数组。请求会随机发向这些数组。相比webbench,http_load的一个优势是它的数据校验环节。每一个url会配有返回请求的checksum值,用于校验每次请求同一个url返回的内容是否一致。第三个结构体是时间管理方法中组成拉链式哈希表的每一个节点。它包含了指向超时处理函数的指针,以及记录超时时间的变量。

5.3 时间戳管理方法
http_load中最为巧妙的就是它的时间管理方法。在该工具中,有很多需要定时触发的地方,比如每隔一段时间输出一份测试进度汇报;链接超过一定时间未响应则记为超时,输出超时错误信息;设定发送频率,每隔一段时间发出一个请求等等。这些时间戳和其超时触发的函数以Timer结构体的形式,全部注册于拉链法构成的哈希表中。每个链表都是以时间戳顺序从早到晚依次排列。这样,在每一个for循环执行超时检测的部分,我们可以很方便地判断出当前时间是否已经超过了时间戳的时间,如果超过,则执行超时处理函数。同时,这样的数据结构也提高了插入新时间戳的效率。

六、结语
http_load与webbench都是很常用的压测工具,如果配合使用,结果做对比,既是对测得结果的校验,也能帮助熟悉两种工具的优劣。http_load的设计思路也可以使用到业务测试工具中来,帮助开发出更高效的压测工具。