JHK数据科学系列课程的课程笔记,这是前两门课《数据科学家的工具箱》和《R语言编程》
数据科学家的工具箱
目标
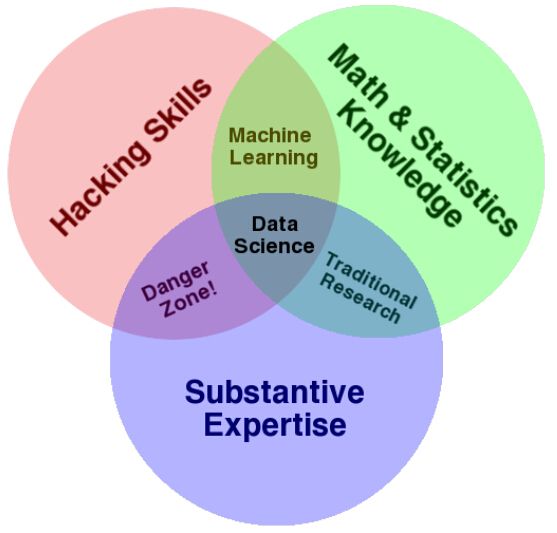
Types of Questions
descriptive analyses
Describe a set of data
exploratory analysis
Find relationships you didn't know about
inferential analysis
use a relatively small sample of data to say something about a bigger population
predictive analysis
To use the data on some objects to predict values for another object
casual analysis
To find out what happens to one variable when you make another variable change
mechanistic analysis
Understand the exact changes in variables that lead to changes in other variables for individual objects
The data is the second most important thing,the most important thing in data science is the question
R语言
方法
参数匹配
位置匹配
名称匹配
部分匹配
给定参数后匹配的顺序:
- Check for exact match for a named argument
- Check for a partial match
- Check for a positional match
Lazy Evaluation
传递给方法的参数,只有在用的时候才去求值。
"..."变长参数
-
在不想拷贝原始方法的全部参数的时候,用于扩展方法
myplot <- function(x, y, type = "l", ...) {
plot(x, y, type = type, ...)
} -
传递额外的参数
mean
function(x, ...)
UseMethod("mean") -
在预先不知道参数数目的时候使用
args(paste)
function(..., sep = " ", collapse = NULL)
paste("a", "b", sep = ":")
[1] "a:b"
编码标准
- Always use text files / text editor
- Indent your code
- Limit the width of your code (80 columns?)
- Limit the length of individual functions
Lexical Scoping
这部分很重要,详细参考课件Scoping Rules
Loop Function
apply
用来对一个数组使用同一个方法(或者通常使用匿名方法)求值。
- 通常用来对矩阵的行或者列使用一个函数
- 可以生成数组,例如求一个矩阵数组的平均值
- 并不比使用循环快,但是一行就能完成
apply(X, MARGIN, FUN, ...)
lapply
遍历一个list,并对每一个元素都调用一个方法
sapply
和lapply一样,但是尝试简化结果(如果可能的话)
- 如果结果是个list,其中的元素都是长度为1,那么返回一个vector
- 如果结果是个list,其中的元素都是长度是长度相等(>1)的向量,那么返回一个matrix
- 如果不行的话,返回一个list
tapply
对一个向量的子集使用一个方法,不清楚为什么叫做tapply
tapply(X, INDEX, FUN = NULL, ..., simplify = TRUE)
根据index参数指定的不同的级别,对X中的每种级别使用FUN求值。
> x <- c(rnorm(10), runif(10), rnorm(10, 1))
> f <- gl(3, 10)
> f
[1] 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3 3
[24] 3 3 3 3 3 3 3
Levels: 1 2 3
> tapply(x, f, mean)
1 2 3
0.1144464 0.5163468 1.2463678
mapply
lapply的多变量版本
split
split接收一个向量或者其他对象,并按照一个factor或者一系列的factor把他们分组。
> str(split)
function(x, f, drop = FALSE, ...)
x is a vector (or list) or data frame
f is a factor (or coerced to one) or a list of factors
drop indicates whether empty factors levels should be dropped
split经常与lapply同时使用。
> lapply(split(x, f), mean)
$‘1‘
[1] 0.1144464
$‘2‘
[1] 0.5163468
$‘3‘
[1] 1.246368
Debugging
- traceback: 打印方法的调用堆栈
- debug: 标记一个函数为“debug”模式,可以一次执行一行
- browser: 暂停函数的执行,进入debug模式
- trace: 允许在函数中指定位置插入调试代码
- recover: allows you to modify the error behavior so that you can browse the function call stack
生成随机数
概率函数
形如: [dpqr]distribution_abbreviation()
其中第一个字母表示所指分布的某一方面:
d=密度函数(density)
p=分布函数(distribution function)
q=分位数函数(quantile function)
r=生成随机数
set.seed() 函数设置随机数种子确保复现性(reproducibility)
随机采样
sample函数从一个对象几何中随机抽取
Profiling
profiling是使用系统的方法来检查程序的不同部分花费了多少时间,在优化代码时特别有用
优化的一般原则
- 首先设计,然后优化
- 记住,早期的优化是万恶之源
- 测量(收集数据),不要猜测
使用system.time()
输入任意的R表达式,返回其执行所需时间(秒)
返回proc_time类的一个对象
user time: time charged to the CPU(s) for this expression
elapsed time: "wall clock" time
## Elapsed time > user time
system.time(readLines("http://www.jhsph.edu"))
user system elapsed
0.004 0.002 0.431
## Elapsed time < user time
hilbert <- function(n) {
i <- 1:n
1/ outer(i - 1, i, "+”)
}
x <- hilbert(1000)
system.time(svd(x))
user system elapsed
1.605 0.094 0.742
- 通常情况下,user time and elapsed time are relatively close, for straight computing tasks
- Elapsed time 可能会大于user time,如果CPU在等待任务上花费了较多时间的话
- Elapsed time 可能会小于user time,如果你的机器拥有并能够使用多个处理器(核心)的话
- Multi-threaded BLAS libraries (vecLib/Accelerate, ATLAS, ACML, MKL)
- Parallel processing via the parallelpackage
The R Profiler
- Rprof()函数在R中开始profile
- summaryRprof()函数总结Rprof()函数的输出
- 注意:Rprof()的默认采样间隔是0.02秒,以0.02秒的间隔跟踪函数调用堆栈
example:
## lm(y ~ x)
sample.interval=10000
"list" "eval" "eval" "model.frame.default" "model.frame" "eval" "eval" "lm"
"list" "eval" "eval" "model.frame.default" "model.frame" "eval" "eval" "lm"
"list" "eval" "eval" "model.frame.default" "model.frame" "eval" "eval" "lm"
"list" "eval" "eval" "model.frame.default" "model.frame" "eval" "eval" "lm"
"na.omit" "model.frame.default" "model.frame" "eval" "eval" "lm"
"na.omit" "model.frame.default" "model.frame" "eval" "eval" "lm"
"na.omit" "model.frame.default" "model.frame" "eval" "eval" "lm"
"na.omit" "model.frame.default" "model.frame" "eval" "eval" "lm"
"na.omit" "model.frame.default" "model.frame" "eval" "eval" "lm"
"na.omit" "model.frame.default" "model.frame" "eval" "eval" "lm"
"na.omit" "model.frame.default" "model.frame" "eval" "eval" "lm"
"lm.fit" "lm"
"lm.fit" "lm"
"lm.fit" "lm"
summaryRprof有两种方式归一化数据:
- "by.total" 每个方法中花费的时间除以整个运行的时间
- "by.self" 一样的作用,但是首先减去花费在方法调用上的时间