3. 数据集
为产生一个多传感器的SAR-Opt匹配对数据集,需要相当多有着空间线性关系的的遥感数据,而为了采取一个尽量自动化的方式做到这一点,我们利用了用了一个遥感云平台 Google Earth Engine ( Gorelick et al., 2017 ),下面,我们将详细描述这个数据集生成过程的每一个步骤。
3.1 在 Google Earth Engine 上做的数据准备
从我们制作数据集的角度来看,Google Earth Engine 具有两方面的优势:一方面,它提供了很大覆盖范围的数据目录,包括好几PB的遥感影像,其中包括所有可用的哨兵卫星数据还有其他的开源地理数据,另一方面,GEE里有一个功能很强大的编程接口,允许我们在Google的计算机中心做一些数据准备和分析工作。因此,我们使用它来挑选、准备并且下载哨兵一号和哨兵二号的影像,这些图像我们随后会制作成匹配对。基于GEE的图像下载还有准备的工作流程我们展示在了Fig.1中。
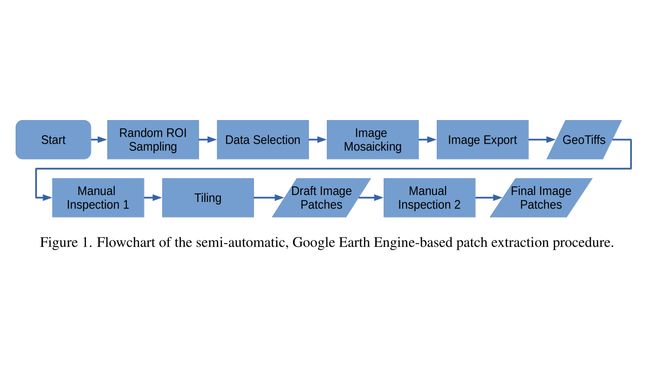
细节上,它包括以下几步:
3.1.1. 随机ROI采样
为了生成一个尽可能和我们的星球看起来比较相似的数据集,我们想采样这样一些区域,它们看起来就像是产生自全世界,为了实现这一任务,我们使用了GEE中提供的ee.FeatureCollection.randomPoints()函数从一个均匀的空间区域随机取样。介于很多遥感观测都把注意力放在城市区域而且城区也确实比农村包含有更复杂的可视信息,我们特地通过在地表泛泛地选100个点再从城区专门选50个点,人为选定了一些城市区域。陆地和城区都是公共区域数据服务所提供的,标尺是1:50米。如果两个点落在一个相当接近的地方,我们就去掉其中的一个,保证没有重叠部分。
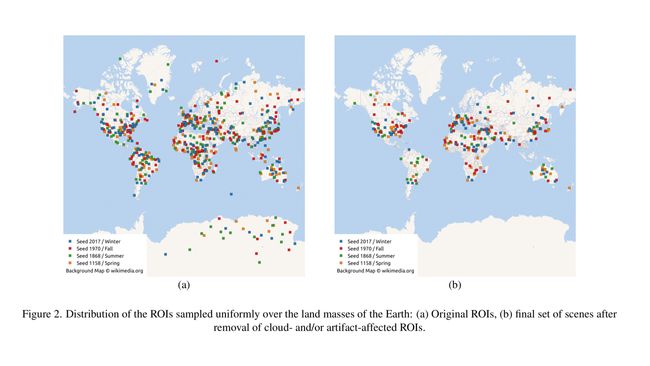
采样来自于四个不同的种子值,分别是 1158, 1868, 1970, 2017 ,结果就是 Fig.2a 所展示的那样的随机ROI采样结果。
3.1.2 数据选择
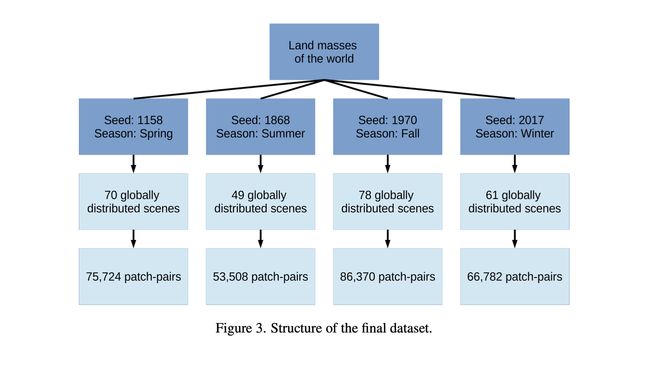
在第二步,我们使用了GEE的工具去过滤图像,来挑选出适合我们场景的哨兵一号和哨兵二号的图像数据。我们想要只使用最近的2017年的数据,所以我们就把这一年分成了四个气象季节:冬季(2016.12.1-2017.2.28)、春季(2017.3.1-2017.5.30)、夏季(2017.6.1-2017.8.31),还有秋季(2017.9.1-2017.11.30)。每一个季节都与四个随机ROI之一联系在一起,这样,提供给我们顶级的数据集结构( Fig.3 ):我们把最后的数据集划分成四个界限相对明显的组ROI,这样命名:ROIs1158 spring、ROIs1868 summer、ROIs1970 fal、ROIs2017 winter。
而后,对于每一个ROI,我们给哨兵二号做了过滤,得到了云层覆盖的最大值不超过1%的数据,哨兵一号图像的过滤结果则是得到了IW工作模式和VV极化方式。如果去云的光学数据或者是VV-IW的SAR图像中任意一个没有处在可用状态,这个ROI就被丢弃。如此一来,ROI的数量就从600个急剧减少到429个。举个例子,所有被抛洒在南极洲的ROI都被不可避免地砍掉了,因为哨兵二号的观测范围只能覆盖到南纬56°到北纬83°。
3.1.3 图像镶嵌
通过持续地挑选图像数据,我们使用GEE内置的ee.ImageCollection.mosaic()函数和ee.Image.clip()函数去为每一个ROI创建单独的图像并修剪ROI的大小。简而言之,ee.ImageCollection.mosaic()函数就是用来拼接那些部分重叠的图像。在 2.2 部分中重点提了一下。我们只选择了哨兵二号的4、3、2波段去创造RGB图像。
3.1.4 图像导出
最后,我们使用GEE的Export.image.toDrive函数导出了前几步创建的图像,数据格式是 GeoTiffs ,分辨率是10米。下载好的 GeoTiffs 然后再做预处理来应付更进一步的应用,具体一点是把灰度值控制在 ±2.5σ 的范围内。把他们的区间限制在[0; 1]内用来表征一个相对大的范围。这些校正分别应用在所有的波段上。
3.1.5 一轮人工审查
我们接着在视觉上把所有个下载好的图像看了一遍,用来找出那些严重的问题。它们可以大体上被归类为以下的几种之一:
1) 大块的无数据区域:不幸的是,ee.ImageCollection.mosaic()函数即使没有找到对应整个ROI的数据适合的信息去也并不会返回任何error信息。当在一个给定的时间区间没有明显的无云颗粒可用时,哨兵二号大量出现这种问题。
2) 严重的云覆盖:来自于每一个哨兵二号的颗粒的云覆盖后设数据信息都仅仅是一个全球共享的参数。如此一来,就可能发生这样的情况:整个颗粒中仅仅包括了一堆云,但是覆盖了ROI的部分就是那些有云的颗粒。
3) 严重的颜色扭曲:偶尔,我们观察哨兵二号的图像其中有一些非常别扭的颜色。我们想做一个容纳那些比较自然的RGB图像的数据集,因此我们就把那些哨兵二号中带有太奇怪颜色的图像去掉了。
在第一轮人工审查之后,只有 258 个ROI被留下了( cf. Fig. 2b )。
3.1.6 分块
考虑到我们的目标是一个包含了能够被用于机器学习模型的数据集指向多种不同的数据融合任务,我们最终选择了256*256像素的块。使用了128的步长(跨度?stride),我们减去了那些处在相邻块之间的重叠部分,当把独立块的数字进行最大化,只有50%能提供可用的场景。在这一步之后,SEN-1-2的数据对的数量就停留在了 298,790 。
3.1.7 第二遍的人工审查
为了删掉仍有少量云雾或者其他问题的图像块,我们又一次肉眼审查了所有的块。在这一步,又人工删掉了 16,406 对儿图像块。留下了最后 282,384 个质量得到良好控制的图像块对。其中的一些我们都放在 Fig.4中了。

3.2 数据集可得性
SEN1-2数据集已经在CCBY开源可用协议之下分享出来了,可以通过慕尼黑科技大学(the Technical University of Munich)的图书馆的一个链接进行下载,链接在此: 数据集下载 。当这个数据集被用作科研目的时,请务必引用这篇文章。