Home Credit Default Risk(2) —初步探索
上篇中已经给出了application_{train|test}.csv数据表字段的基本含义,本篇对其进行基本的数据分析,包活异常数据处理,特征变换等,最后给出仅考虑此数据文件,应用logistic回归和random forest两种模型分别训练模型的方式。
加载数据并初步预览
# 导入需要的依赖包
import os
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
import numpy as np
from sklearn.preprocessing import LabelEncoder, MinMaxScaler, Imputer
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
dir_path = 'XXX/dataset'#替换为数据文件所在目录
print(os.listdir(dir_path))
结果如下:
[‘application_test.csv’, ‘application_train.csv’, ‘bureau.csv’, ‘bureau_balance.csv’, ‘credit_card_balance.csv’, ‘HomeCredit_columns_description.csv’, ‘installments_payments.csv’, ‘POS_CASH_balance.csv’, ‘previous_application.csv’, ‘sample_submission.csv’]
# 加载训练数据和测试数据
application_train_file = dir_path + '/application_train.csv'
application_test_file = dir_path + '/application_test.csv'
app_train = pd.read_csv(application_train_file)
app_test = pd.read_csv(application_test_file)
# 初步预览
print('Training data shape: ', app_train.shape)
app_train.head()
结果如下:
Training data shape: (307511, 122)
| SK_ID_CURR | TARGET | NAME_CONTRACT_TYPE | CODE_GENDER | FLAG_OWN_CAR | FLAG_OWN_REALTY | CNT_CHILDREN | AMT_INCOME_TOTAL | AMT_CREDIT | AMT_ANNUITY | ... | FLAG_DOCUMENT_18 | FLAG_DOCUMENT_19 | FLAG_DOCUMENT_20 | FLAG_DOCUMENT_21 | AMT_REQ_CREDIT_BUREAU_HOUR | AMT_REQ_CREDIT_BUREAU_DAY | AMT_REQ_CREDIT_BUREAU_WEEK | AMT_REQ_CREDIT_BUREAU_MON | AMT_REQ_CREDIT_BUREAU_QRT | AMT_REQ_CREDIT_BUREAU_YEAR | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 100002 | 1 | Cash loans | M | N | Y | 0 | 202500.0 | 406597.5 | 24700.5 | ... | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 1 | 100003 | 0 | Cash loans | F | N | N | 0 | 270000.0 | 1293502.5 | 35698.5 | ... | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 100004 | 0 | Revolving loans | M | Y | Y | 0 | 67500.0 | 135000.0 | 6750.0 | ... | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 100006 | 0 | Cash loans | F | N | Y | 0 | 135000.0 | 312682.5 | 29686.5 | ... | 0 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 100007 | 0 | Cash loans | M | N | Y | 0 | 121500.0 | 513000.0 | 21865.5 | ... | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
5 rows × 122 columns
1.根据TARGET在不同分类下的数量绘制整体风险直方图
# 1.根据TARGET在不同分类下的数量绘制整体风险直方图
app_train.TARGET.value_counts().plot(kind='bar')
plt.title("是否有偿还风险(1-有风险,0- 无风险)")
plt.ylabel("人数")
plt.show()

2.检查缺失数据整体情况(对于缺失值的处理可以舍弃,补中位数,补均值,RF预测,XGBoost预测等)
# 2.检查缺失数据整体情况
def examine_missing_data(df):
missing = df.isnull().sum().sort_values(ascending=False)
missing_percent = (100 * df.isnull().sum() / len(df)).sort_values(ascending=False)
missing_table = pd.concat([missing, missing_percent], axis=1)
missing_table = missing_table.rename(columns={0: '缺失值数量', 1: '缺失值占比(%)'})
missing_table = missing_table[missing_table.iloc[:, 1] != 0]
print("数据总共有%d个特征,其中存在缺失值的特征数为%d" % (df.shape[1], missing_table.shape[0]))
return missing_table
missing_values = examine_missing_data(app_train)
missing_values.head(10)
结果如下:
数据总共有122个特征,其中存在缺失值的特征数为67
| 缺失值数量 | 缺失值占比(%) | |
|---|---|---|
| COMMONAREA_MEDI | 214865 | 69.872297 |
| COMMONAREA_AVG | 214865 | 69.872297 |
| COMMONAREA_MODE | 214865 | 69.872297 |
| NONLIVINGAPARTMENTS_MODE | 213514 | 69.432963 |
| NONLIVINGAPARTMENTS_MEDI | 213514 | 69.432963 |
| NONLIVINGAPARTMENTS_AVG | 213514 | 69.432963 |
| FONDKAPREMONT_MODE | 210295 | 68.386172 |
| LIVINGAPARTMENTS_MEDI | 210199 | 68.354953 |
| LIVINGAPARTMENTS_MODE | 210199 | 68.354953 |
| LIVINGAPARTMENTS_AVG | 210199 | 68.354953 |
3. 查看特征类型(非数值类型需要LabelEncoder或者one-hot Encoder编码成数值型)
对于离散型非数值特征,例如工作性质(工人,教师,商人,医生)需要编码成计算机能识别的数值类型,通常有两种方式,label encoder简单的说就是编码成连续连续的数值,例如(工人— 0,教师 — 1,商人— 2,医生—4)。而one-hot(独热)编码,直观来说就是有多少个状态就有多少比特,而且只有一个比特为1,其他全为0的一种码制,例如(工人—1000,教师—0100,商人—0010,医生—0001)。可以看出one-hot编码长度就是该特征可以取到的所有的状态的数量,对于状态数很多的情况下,可能会导致维数灾难,可以结合PCA算法优化。对于状态数只有二个的情况,LabelEncoder的0,1二值就足够表示,不需要one-hot来扩充编码位数了。
# 3.查看特征类型(非数值类型需要LabelEncoder或者one-hot编码成数值型)
print(app_train.dtypes.value_counts())
结果如下:
float64 65
int64 41
object 16
dtype: int64
可以看出有16个非数值型(object)特征。
# 统计非数值型数据的unique数
print(app_train.select_dtypes(include='object').apply(func=pd.Series.nunique, axis=0))
NAME_CONTRACT_TYPE 2
CODE_GENDER 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAME_FAMILY_STATUS 6
NAME_HOUSING_TYPE 6
OCCUPATION_TYPE 18
WEEKDAY_APPR_PROCESS_START 7
ORGANIZATION_TYPE 58
FONDKAPREMONT_MODE 4
HOUSETYPE_MODE 3
WALLSMATERIAL_MODE 7
EMERGENCYSTATE_MODE 2
dtype: int64
# 可以看出ORGANIZATION_TYPE的类别特别多,有58个,
print(app_train['ORGANIZATION_TYPE'].unique())
['Business Entity Type 3' 'School' 'Government' 'Religion' 'Other' 'XNA'
'Electricity' 'Medicine' 'Business Entity Type 2' 'Self-employed'
'Transport: type 2' 'Construction' 'Housing' 'Kindergarten'
'Trade: type 7' 'Industry: type 11' 'Military' 'Services'
'Security Ministries' 'Transport: type 4' 'Industry: type 1' 'Emergency'
'Security' 'Trade: type 2' 'University' 'Transport: type 3' 'Police'
'Business Entity Type 1' 'Postal' 'Industry: type 4' 'Agriculture'
'Restaurant' 'Culture' 'Hotel' 'Industry: type 7' 'Trade: type 3'
'Industry: type 3' 'Bank' 'Industry: type 9' 'Insurance' 'Trade: type 6'
'Industry: type 2' 'Transport: type 1' 'Industry: type 12' 'Mobile'
'Trade: type 1' 'Industry: type 5' 'Industry: type 10' 'Legal Services'
'Advertising' 'Trade: type 5' 'Cleaning' 'Industry: type 13'
'Trade: type 4' 'Telecom' 'Industry: type 8' 'Realtor' 'Industry: type 6']
# 由于类别在后面会Encoder成多个特征,冗余的类别会导致特征数量过多,这里先简单的使用正则化根据大类合并
def organization_type_convert(df):
df['ORGANIZATION_TYPE'].replace(
regex=[r'Business Entity[\s\S]*', r'Transport[\s\S]*', r'Industry[\s\S]*', r'Trade[\s\S]*'],
value=['Business Entity', 'Transport', 'Industry', 'Trade'],
inplace=True)
organization_type_convert(app_train)
organization_type_convert(app_test)
#观察ORGANIZATION_TYPE的类别显著减少
print(app_train['ORGANIZATION_TYPE'].unique())
['Business Entity' 'School' 'Government' 'Religion' 'Other' 'XNA'
'Electricity' 'Medicine' 'Self-employed' 'Transport' 'Construction'
'Housing' 'Kindergarten' 'Trade' 'Industry' 'Military' 'Services'
'Security Ministries' 'Emergency' 'Security' 'University' 'Police'
'Postal' 'Agriculture' 'Restaurant' 'Culture' 'Hotel' 'Bank' 'Insurance'
'Mobile' 'Legal Services' 'Advertising' 'Cleaning' 'Telecom' 'Realtor']
# 对非数值型数据且unique数小于等于2的用 LabelEncoder进行编码转换
def label_encode_unique_under_two(train, test):
label_encoder = LabelEncoder()
for col in train:
if train[col].dtype == 'object' and len(train[col].unique()) <= 2:
label_encoder.fit(train[col])
train[col] = label_encoder.transform(train[col])
test[col] = label_encoder.transform(test[col])
return train, test
# 对非数值型数据且unique数大于2的用 one-hot进行编码转换
def onehot_encode_unique_over_two(train, test):
train = pd.get_dummies(train)
test = pd.get_dummies(test)
return train, test
app_train, app_test = label_encode_unique_under_two(app_train, app_test)
app_train, app_test = onehot_encode_unique_over_two(app_train, app_test)
print(app_train.shape)
print(app_test.shape)
(307511, 220)
(48744, 216)
# 4.对齐训练和测试数据的列数(训练数据只应该比测试数据多出TARGET一列)
train_target = app_train['TARGET']
app_train, app_test = app_train.align(other=app_test, join='inner', axis=1)
app_train['TARGET'] = train_target
print(app_train.shape)
print(app_test.shape)
(307511, 217)
(48744, 216)
# 5.异常数据检测
def plot_day_employ(train):
print(train['DAYS_EMPLOYED'].describe())
train['DAYS_EMPLOYED'].plot.hist(title='从业时间分布直方图(以天为单位)')
plt.xlabel('从业时间')
plt.ylabel('人数')
plt.show()
plot_day_employ(app_train)
count 307511.000000
mean 63815.045904
std 141275.766519
min -17912.000000
25% -2760.000000
50% -1213.000000
75% -289.000000
max 365243.000000
Name: DAYS_EMPLOYED, dtype: float64

# 由于从业时间记录的是距离申请当日的天数,应该为负值,所以上图中右边区域的数据显然是异常的
anoms = app_train[app_train['DAYS_EMPLOYED'] > 300000]
anoms_one = app_train[app_train['DAYS_EMPLOYED'] == 365243]
non_anoms = app_train[app_train['DAYS_EMPLOYED'] != 365243]
print(anoms.shape)
print(anoms_one.shape)
(55374, 217)
(55374, 217)
# 可以看出异常数据均为一个恒定值365243,推测有可能是人为批量修改数据导致的
print('异常数据的偿还风险均值为%0.2f%%' % (100 * anoms['TARGET'].mean()))
print('正常数据的偿还风险均值为%0.2f%%' % (100 * non_anoms['TARGET'].mean()))
异常数据的偿还风险均值为5.40%
正常数据的偿还风险均值为8.66%
# 可以看出异常数据的偿还风险更低,所以不能简单的将异常数据删除,
# 这里将从业时间拆成两个特征,正常从业时间和异常从业时间,处理方式如下
app_train['DAYS_EMPLOYED_ANOM'] = app_train['DAYS_EMPLOYED'] == 365243
app_train['DAYS_EMPLOYED'].replace({365243: np.nan}, inplace=True)
app_test['DAYS_EMPLOYED_ANOM'] = app_test['DAYS_EMPLOYED'] == 365243
app_test['DAYS_EMPLOYED'].replace({365243: np.nan}, inplace=True)
plot_day_employ(app_train)
count 252137.000000
mean -2384.169325
std 2338.360162
min -17912.000000
25% -3175.000000
50% -1648.000000
75% -767.000000
max 0.000000
Name: DAYS_EMPLOYED, dtype: float64

# 6.将年龄和从业天数都转化为正值,且以年为单位
app_train['DAYS_BIRTH'] = app_train['DAYS_BIRTH'].abs() / 365
app_train['DAYS_EMPLOYED'] = app_train['DAYS_EMPLOYED'].abs() / 365
app_test['DAYS_BIRTH'] = app_test['DAYS_BIRTH'].abs() / 365
app_test['DAYS_EMPLOYED'] = app_test['DAYS_EMPLOYED'].abs() / 365
app_train.rename(columns={'DAYS_BIRTH': 'YEARS_BIRTH', 'DAYS_EMPLOYED': 'YEARS_EMPLOYED'}, inplace=True)
app_test.rename(columns={'DAYS_BIRTH': 'YEARS_BIRTH', 'DAYS_EMPLOYED': 'YEARS_EMPLOYED'}, inplace=True)
print(app_train['YEARS_BIRTH'].describe())
count 307511.000000
mean 43.936973
std 11.956133
min 20.517808
25% 34.008219
50% 43.150685
75% 53.923288
max 69.120548
Name: YEARS_BIRTH, dtype: float64
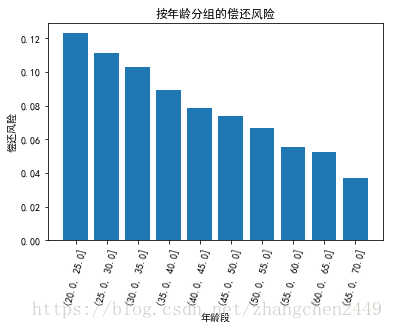
# 7. 将离散的年龄数据转为年龄区间
age_data = app_train.loc[:,['TARGET', 'YEARS_BIRTH']]
age_data.loc[:, 'YEARS_BINNED'] = pd.cut(age_data.loc[:,'YEARS_BIRTH'], bins=np.linspace(20, 70, num=11))
age_group = age_data.groupby('YEARS_BINNED').mean()
print(age_group.index)
CategoricalIndex([(20.0, 25.0], (25.0, 30.0], (30.0, 35.0], (35.0, 40.0],
(40.0, 45.0], (45.0, 50.0], (50.0, 55.0], (55.0, 60.0],
(60.0, 65.0], (65.0, 70.0]],
categories=[(20.0, 25.0], (25.0, 30.0], (30.0, 35.0], (35.0, 40.0], (40.0, 45.0], (45.0, 50.0], (50.0, 55.0], (55.0, 60.0], ...], ordered=True, name='YEARS_BINNED', dtype='category')
plt.bar(age_group.index.astype(str), age_group['TARGET'])
plt.title('按年龄分组的偿还风险')
plt.xticks(rotation=75)
plt.xlabel('年龄段')
plt.ylabel('偿还风险')
plt.show()
# 8.这里简单的根据相关系数矩阵找到和TARGET最相关的特征(也可以在Random forest算法中学习出来,后面会介绍)
correlations = app_train.corr()['TARGET'].sort_values(ascending=False)
print('最正相关的十个特征为:\n', correlations.head(10))
print('最负相关的十个特征为:\n', correlations.tail(10))
最正相关的十个特征为:
TARGET 1.000000
REGION_RATING_CLIENT_W_CITY 0.060893
REGION_RATING_CLIENT 0.058899
NAME_INCOME_TYPE_Working 0.057481
DAYS_LAST_PHONE_CHANGE 0.055218
CODE_GENDER_M 0.054713
DAYS_ID_PUBLISH 0.051457
REG_CITY_NOT_WORK_CITY 0.050994
NAME_EDUCATION_TYPE_Secondary / secondary special 0.049824
FLAG_EMP_PHONE 0.045982
Name: TARGET, dtype: float64
最负相关的十个特征为:
DAYS_EMPLOYED_ANOM -0.045987
ORGANIZATION_TYPE_XNA -0.045987
NAME_INCOME_TYPE_Pensioner -0.046209
CODE_GENDER_F -0.054704
NAME_EDUCATION_TYPE_Higher education -0.056593
YEARS_EMPLOYED -0.074958
YEARS_BIRTH -0.078239
EXT_SOURCE_1 -0.155317
EXT_SOURCE_2 -0.160472
EXT_SOURCE_3 -0.178919
Name: TARGET, dtype: float64
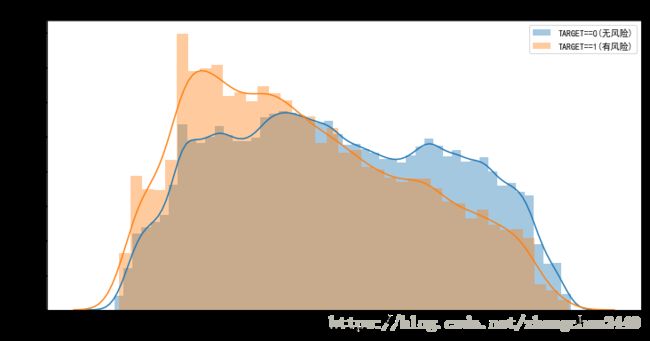
# 从而可以看出来EXT_SOURCE_3是和TARGET最相关的特征(绝对值最大),这里可以绘制出KDE曲线
def plot_kde_curve(var_name, df):
"""
绘制变量和目标关联关系的核密度曲线
:param var_name: 变量名称
:param df: DataFrame
:return:
"""
# 计算皮尔逊相关系数
corr = df.loc[:,'TARGET'].corr(df.loc[:,var_name], method='pearson')
# 分别计算target=0和target=1时variable的中位数
avg_paid = df.loc[df['TARGET'] == 0, var_name].median()
avg_not_paid = df.loc[df['TARGET'] == 1, var_name].median()
print('%s 和TARGET的相关系数为 %0.4f' % (var_name, corr))
print('无偿还风险的变量中位数为 %0.4f' % avg_paid)
print('有偿还风险的变量中位数系数为 %0.4f ' % avg_not_paid)
plt.figure(figsize=(12, 6))
# 绘制KDE曲线(distplot默认绘制直方图和核密度曲线)
sns.distplot(df.loc[df['TARGET'] == 0, var_name], label='TARGET==0(无风险)')
sns.distplot(df.loc[df['TARGET'] == 1, var_name], label='TARGET==1(有风险)')
plt.xlabel(var_name)
plt.ylabel('核密度估计')
plt.title('%s 分布' % var_name)
plt.legend()
plt.show()
plot_kde_curve('YEARS_BIRTH', app_train)
YEARS_BIRTH 和TARGET的相关系数为 -0.0782
无偿还风险的变量中位数为 43.4986
有偿还风险的变量中位数系数为 39.1288
# 8.基准模型-LR
def base_lr_train(train_data, test_data):
target = train_data['TARGET']
train = train_data.drop(columns=['TARGET'])
test = test_data.copy()
# 用中位数填充缺失值
imputer = Imputer(strategy='median')
imputer.fit(train)
train = imputer.transform(train)
test = imputer.transform(test)
# 归一化到[0,1]区间
scaler = MinMaxScaler(feature_range=(0, 1))
scaler.fit(train)
train = scaler.transform(train)
test = scaler.transform(test)
print('Training data shape', train.shape)
print('Test data shape', test.shape)
# 使用Logistic回归建模
log_reg = LogisticRegression(C=0.001)
log_reg.fit(train, target)
log_reg_predict_not_paid = log_reg.predict_proba(test)[:, 1]
submit = test_data[['SK_ID_CURR']]
submit.loc[:, 'TARGET'] = log_reg_predict_not_paid
print(submit.head(5))
submit.to_csv(dir_path + '/result/log_reg_baseline.csv', index=False)
base_lr_train(app_train, app_test)
# 9.随机森林模型-RF
def base_rf_train(train_data, test_data):
target = train_data['TARGET']
train = train_data.drop(columns=['TARGET'])
test = test_data.copy()
# 用中位数填充缺失值
imputer = Imputer(strategy='median')
imputer.fit(train)
train = imputer.transform(train)
test = imputer.transform(test)
# 归一化到[0,1]区间
scaler = MinMaxScaler(feature_range=(0, 1))
scaler.fit(train)
train = scaler.transform(train)
test = scaler.transform(test)
print('Training data shape', train.shape)
print('Test data shape', test.shape)
random_forest = RandomForestClassifier(n_estimators=100,random_state=42,verbose=1,n_jobs=-1)
random_forest.fit(train,target)
random_forest_predict_not_paid = random_forest.predict_proba(test)[:, 1]
submit = test_data[['SK_ID_CURR']]
submit.loc[:, 'TARGET'] = random_forest_predict_not_paid
print(submit.head(5))
submit.to_csv(dir_path + '/result/random_forest_baseline.csv', index=False)
random_forest.max_features
base_rf_train(app_train, app_test)