或许是迄今为止第一篇讲解 fps 计算原理的文章吧 | 开发者说·DTalk
本文原作者: simowce,原文发布于微信公众号: 简静慢
https://mp.weixin.qq.com/s/sZ-v3hV7IkBjwFSYzAM3iw
前言
fps,是 frames per second 的简称,也就是我们常说的 "帧率"。在游戏领域中,fps 作为衡量游戏性能的基础指标,对于游戏开发和手机 vendor 厂商都是非常重要的数据,而计算游戏的 fps 也成为日常测试的基本需求。目前市面上有很多工具都能够计算 fps,那么这些工具计算 fps 的方法是什么?原理是什么呢?本文将针对这些问题,深入源码进行分析,力求找到一个详尽的答案 (源码分析基于 Android 10)。
计算方法
目前绝大部分帧率统计软件,在网上能找到的各种统计 fps 的脚本,使用的信息来源有两种: 一种是基于 dumpsys SurfaceFlinger --latency Layer-name (注意是 Layer 名字,不是包名,不是 Activity 名字,至于为什么,下面会解答);另一种是基于 dumpsys gfxinfo。其实这两种深究到原理基本上是一致的,本篇文章专注于分析第一种,市面上大部分帧率统计软件用的也是第一种,只不过部分软件为了避免被人反编译看到,将这个计算逻辑封装成 so 库,增加反编译的难度。然而经过验证,这些软件最后都是通过调用上面的命令来计算的 fps 的。
但是这个命令为什么能够计算 fps 呢?先来看这个命令的输出,以王者荣耀为例 (王者荣耀这种游戏类的都是以 SurfaceView 作为控件,因此其 Layer 名字都以 SurfaceView - 打头):
> adb shell dumpsys SurfaceFlinger --latency "SurfaceView - com.tencent.tmgp.sgame/com.tencent.tmgp.sgame.SGameActivity#0"
16666666
59069638658663 59069678041684 59069654158298
59069653090955 59069695022100 59069670894236
59069671034444 59069711403455 59069687949861
59069688421840 59069728057361 59069704415121
59069705420850 59069744773350 59069720767830
59069719818975 59069761378975 59069737416007
59069736702673 59069778060955 59069754568663
59069753361528 59069794716007 59069770761632
59069768766371 59069811380486 59069787649600
......
输出的这一堆数字究竟是什么意思?首先,第一行的数字是当前的 VSYNC 间隔,单位是纳秒。例如现在的屏幕是 60Hz 的,因此就是 16.6ms,然后下面的一堆数字,总共有 127 行 (为什么是 127 行,下面也会说明),每一行有 3 个数字,每个数字都是时间戳,单位是纳秒,具体的意义后文会说明。而在计算 fps 的时候,使用的是第二个时间戳。原因同样会在后文进行解答。
fence 简析
后面的原理分析涉及到 fence,但是 fence 囊括的内容众多,因此这里只是对 fence 做一个简单地描述。如果大家感兴趣,后面我会专门给 fence 写一篇详细的说明文章。
fence 是什么
首先得先说明一下 App 绘制的内容是怎么显示到屏幕的:
App 需要显示的内容要绘制在 Buffer 里,而这个 Buffer 是从 BufferQueue 通过 dequeueBuffer() 申请的。申请到 Buffer 以后,App 将内容填充到 Buffer 以后,需要通过 queueBuffer() 将 Buffer 还回去交给 SurfaceFlinger 去进行合成和显示。然后,SurfaceFlinger 要开始合成的时候,需要调用 acquireBuffer() 从 BufferQueue 里面拿一个 Buffer 去合成,合成完以后通过 releaseBuffer() 将 Buffer 还给 BufferQueue,如下图:

BufferQueue
在上面的流程中,其实有一个问题,就是在 App 绘制完通过 queueBuffer() 将 Buffer 还回去的时候,此时仅仅只是 CPU 侧的完成,GPU 侧实际上并没有真正完成。因此如果此时拿这个 Buffer 去进行合成/显示的话,就会有问题 (Buffer 可能还没有完全地绘制完)。
事实上,由于 CPU 和 GPU 之前是异步的,因此我们在代码里面执行一系列的 OpenGL 函数调用的时候,看上去函数已经返回了,实际上,只是把这个命令放在本地的 command buffer 里。具体什么时候这条 GL command 被真正执行完毕 CPU 是不知道的,除非使用 glFinish() 等待这些命令完全执行完,但是这样会带来很严重的性能问题,因为这样会使得 CPU 和 GPU 的并行性完全丧失,CPU 会在 GPU 完成之前一直处于空等的状态。因此,如果能够有一种机制,在不需要对 Buffer 进行读写的时候,大家各干各的;当需要对 Buffer 进行读写的时候,可以知道此时 Buffer 在 GPU 的状态,必要的时候等一下,就不会有上面的问题了。
fence 就是这样的同步机制,如它直译过来的意思一样——"栅栏",用来把东西拦住。那么 fence 是要拦住什么东西呢?就是前面提到的 Buffer 了。Buffer 在整个绘制、合成、显示的过程中,一直在 CPU,GPU 和 HWC 之前传递,某一方要使用 Buffer 之前,需要检查之前的使用者是否已经移交了 Buffer 的 "使用权"。而这里的 "使用权",就是 fence。当 fence 释放 (即 signal) 的时候,说明 Buffer 的上一个使用者已经交出了使用权,对于 Buffer 进行操作是安全的。
fence in Code
在 Android 源码里面,fence 的实现总共分为四部分:
fence driver
同步的核心实现
libsync
位于 system/core/libsync,libsync 的主要作用是对 driver 接口的封装
Fence 类
这个 Fence 类位于 frameworks/native/libs/ui/Fence.cpp,主要是对 libsync 进行 C++ 封装,方便 framework 调用
FenceTime 类
这个 FenceTime 是一个工具类,是对 Fence 的进一步封装,提供两个主要的接口——isValid() 和 getSignalTime(),主要作用是针对需要多次查询 fence 的释放时间的场景 (通过调用 Fence::getSignalTime() 来查询 fence 的释放时间)。通过对 Fence 进行包裹,当第一次调用 FenceTime::getSignalTime() 的时候,如果 fence 已经释放,那么会将这个 fence 的释放时间缓存起来,然后下次再调用 FenceTime::getSignal() 的时间,就能将缓存起来的释放时间直接返回,从而减少对 Fence::getSignalTime() 不必要的调用 (因为 fence 释放的时间不会改变)。
fence in Android
在 Android 里面,总共有三类 fence —— acquire fence,release fence 和 present fence。其中,acquire fence 和 release fence 隶属于 Layer,present fence 隶属于帧 (即 Layers):
acquire fence
前面提到,App 将 Buffer 通过 queueBuffer() 还给 BufferQueue 的时候,此时该 Buffer 的 GPU 侧其实是还没有完成的,此时会带上一个 fence,这个 fence 就是 acquire fence。当 SurfaceFlinger/ HWC 要读取 Buffer 以进行合成操作的时候,需要等 acquire fence 释放之后才行。
release fence
当 App 通过 dequeueBuffer() 从 BufferQueue 申请 Buffer,要对 Buffer 进行绘制的时候,需要保证 HWC 已经不再需要这个 Buffer 了,即需要等 release fence signal 才能对 Buffer 进行写操作。
present fence
present fence 在 HWC1 的时候称为 retire fence,在 HWC2 中改名为 present fence。当前帧成功显示到屏幕的时候,present fence 就会 signal。
原理分析
简单版
现在来看一下通过 dumpsys SurfaceFlinger --latency Layer-name 计算 Layer fps 的原理。dumpsys 的调用流程就不赘述了,最终会走到 SurfaceFlinger::doDump():
status_t SurfaceFlinger::doDump(int fd, const DumpArgs& args,
bool asProto) NO_THREAD_SAFETY_ANALYSIS {
...
static const std::unordered_map dumpers = {
......
{"--latency"s, argsDumper(&SurfaceFlinger::dumpStatsLocked)},
......
};
从这里可以看到,我们在执行 dumpsys SurfaceFlinger 后面加的那些 --xxx 参数最终都会在这里被解析,这里咱们是 --latency,因此看 SurfaceFlinger::dumpStatsLocked:
void SurfaceFlinger::dumpStatsLocked(const DumpArgs& args, std::string& result) const {
StringAppendF(&result, "%" PRId64 "\n", getVsyncPeriod());
if (args.size() > 1) {
const auto name = String8(args[1]);
mCurrentState.traverseInZOrder([&](Layer* layer) {
if (name == layer->getName()) {
layer->dumpFrameStats(result);
}
});
} else {
mAnimFrameTracker.dumpStats(result);
}
}
从这里就能够看到,这里先会打印当前的 VSYNC 间隔,然后遍历当前的 Layer,然后逐个比较 Layer 的名字,如果跟传进来的参数一致的话,那么就会开始 dump layer 的信息;否则命令就结束了。因此,很多人会遇到这个问题:
❔ 为什么执行了这个命令却只打印出一个数字?
✔ 其实这个时候您应该去检查您的 Layer 参数是否正确。
接下来 layer->dumpFrameStats() 会去调 FrameTrack::dumpStats():
void FrameTracker::dumpStats(std::string& result) const {
Mutex::Autolock lock(mMutex);
processFencesLocked();
const size_t o = mOffset;
for (size_t i = 1; i < NUM_FRAME_RECORDS; i++) {
const size_t index = (o+i) % NUM_FRAME_RECORDS;
base::StringAppendF(&result, "%" PRId64 "\t%" PRId64 "\t%" PRId64 "\n",
mFrameRecords[index].desiredPresentTime,
mFrameRecords[index].actualPresentTime,
mFrameRecords[index].frameReadyTime);
}
result.append("\n");
}
NUM_FRAME_RECORDS 被定义为 128,因此输出的数组有 127 个。每组分别有三个数字—— desiredPresentTime,actualPresentTime,frameReadyTime,每个数字的意义分别是:
desiredPresentTime
下一个 HW-VSYNC 的时间戳
actualPresentTime
retire fence signal 的时间戳
frameReadyTime
acquire fence signal 的时间戳
结合前面对 present fence 的描述就可以看出 dumpsys SurfaceFlinger --latency 计算 fps 的原理:
从 dumpsys SurfaceFlinger --latency 获取到最新 127 帧的 present fence 的 signal time,结合前面对于 present fence 的说明,当某帧 present fence 被 signal 的时候,说明这一帧已经被显示到屏幕上了。因此,我们可以通过判断一秒内有多少个 present fence signal 了,来反推出一秒内有多少帧被刷到屏幕上,从而计算出 fps。
复杂版
我们已经知道了 fps 计算的原理了,但是呢,小朋友,你是否有很多问号?
这个 actualPresentTime 是从哪来的?
假设要统计 fps 的 Layer 没有更新,但是别的 Layer 更新了,这种情况下 present fence 也会正常 signal,那这样计算出来的 fps 是不是不准啊?
为了解答这些问题,我们还得接着看。
前面已经提到计算 fps 的时候使用的是第二个数值,因此后面的文章着重分析这个 actualPresentTime。那么 actualPresentTime 是在哪里赋值的呢?实际赋值的位置是在 FrameTracker::dumpStats() 调用的一个子函数——processFencesLocked():
void FrameTracker::processFencesLocked() const {
FrameRecord* records = const_cast(mFrameRecords);
int& numFences = const_cast(mNumFences);
for (int i = 1; i < NUM_FRAME_RECORDS && numFences > 0; i++) {
size_t idx = (mOffset+NUM_FRAME_RECORDS-i) % NUM_FRAME_RECORDS;
...
const std::shared_ptr& pfence =
records[idx].actualPresentFence;
if (pfence != nullptr) {
// actualPresentTime 是在这里赋值的
records[idx].actualPresentTime = pfence->getSignalTime();
if (records[idx].actualPresentTime < INT64_MAX) {
records[idx].actualPresentFence = nullptr;
numFences--;
updated = true;
}
}
......
其中,FrameRecord 的完整定义如下:
struct FrameRecord {
FrameRecord() :
desiredPresentTime(0),
frameReadyTime(0),
actualPresentTime(0) {}
nsecs_t desiredPresentTime;
nsecs_t frameReadyTime;
nsecs_t actualPresentTime;
std::shared_ptr frameReadyFence;
std::shared_ptr actualPresentFence;
};
从上面的代码可以看出,actualPresentTime 是调用 actualPresentFence 的 getSignalTime() 赋值的。而 actualPresentFence 是通过 setActualPresentFence() 赋值的:
void FrameTracker::setActualPresentFence(
std::shared_ptr&& readyFence) {
Mutex::Autolock lock(mMutex);
mFrameRecords[mOffset].actualPresentFence = std::move(readyFence);
mNumFences++;
}
setActualPresentFence() 又是经过下面的调用流程最终被调用的:
SurfaceFlinger::postComposition()
\_ BufferLayer::onPostCompostion()
这里重点看一下 SurfaceFlinger::postComposition():
void SurfaceFlinger::postComposition()
{
......
mDrawingState.traverseInZOrder([&](Layer* layer) {
bool frameLatched =
layer->onPostComposition(displayDevice->getId(), glCompositionDoneFenceTime,
presentFenceTime, compositorTiming);
......
回忆一下我们前面的问题:
❔ 假设要统计 fps 的 Layer 没有更新,但是别的 Layer 更新了,这种情况下 present fence 也会正常 signal,那这样计算出来的 fps 是不是不准啊?
答案就在 mDrawingState,在 Surfacelinger 中有两个用来记录当前系统中 Layers 状态的全局变量:
mDrawingState
mDrawingState 代表的是上次 "drawing" 时候的状态
mCurrentState
mCurrentState 代表的是当前的状态因此,如果当前 Layer 没有更新,那么是不会被记录到 mDrawingState 里的,因此这一次的 present fence 也就不会被记录到该 Layer 的 FrameTracker 里的 actualPresentTime 了。
再说回来,SurfaceFlinger::postComposition() 是 SurfaceFlinger 合成的最后阶段。presentFenceTime 就是前面的 readyFence 参数了,它是在这里被赋值的:
mPreviousPresentFences[0] = mActiveVsyncSource
? getHwComposer().getPresentFence(*mActiveVsyncSource->getId())
: Fence::NO_FENCE;
auto presentFenceTime = std::make_shared(mPreviousPresentFences[0]);
而 getPresentFence() 这个函数,就把这个流程转移到了 HWC 了:
sp HWComposer::getPresentFence(DisplayId displayId) const {
RETURN_IF_INVALID_DISPLAY(displayId, Fence::NO_FENCE);
return mDisplayData.at(displayId).lastPresentFence;
}
至此,我们一路辗转,终于找到了这个 present fence 的真身,只不过这里它还蒙着一层面纱,我们需要在看一下这个 lastPresentFence 是在哪里赋值的,这里按照不同的合成方式位置有所不同:
DEVICE 合成
DEVICE 合成的 lastPresentFence 是在 HWComposer::prepare() 里赋值:
status_t HWComposer::prepare(DisplayId displayId, const compositionengine::Output& output) {
......
if (!displayData.hasClientComposition) {
sp outPresentFence;
uint32_t state = UINT32_MAX;
error = hwcDisplay->presentOrValidate(&numTypes, &numRequests, &outPresentFence , &state);
if (error != HWC2::Error::HasChanges) {
RETURN_IF_HWC_ERROR_FOR("presentOrValidate", error, displayId, UNKNOWN_ERROR);
}
if (state == 1) { //Present Succeeded.
......
displayData.lastPresentFence = outPresentFence;
经常看 systrace 的同学对这个函数绝对不会陌生,就是 systrace 里面 SurfaceFlinger 的那个 prepare():
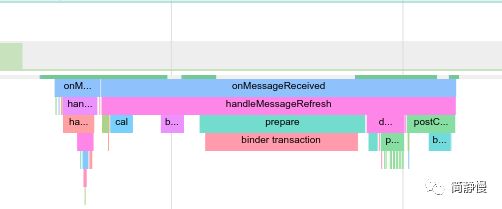
Systrace 中的 prepare
这个函数非常重要,它通过一系列的调用:
HWComposer::prepare()
\_ Display::presentOrValidate()
\_ Composer::presentOrValidateDisplay()
\_ CommandWriter::presentOrvalidateDisplay()
最终通过 HwBinder 通知 HWC 的 Server 端开始进行 DEVICE 合成,Server 端在收到 Client 端的请求以后,会返回给 Client 端一个 present fence (时刻记住,fence 用于跨环境的同步,例如这里就是 Surfacelinger 和 HWC 之间的同步)。然后当下一个 HW-VSYNC 来的时候,会将合成好的内容显示到屏幕上并且将该 present fence signal,标志着这一帧已经显示在屏幕上了。
GPU 合成
GPU 合成的 lastPresentFence 是在 presentAndGetPresentFences() 里赋值:
status_t HWComposer::presentAndGetReleaseFences(DisplayId displayId) {
......
displayData.lastPresentFence = Fence::NO_FENCE;
auto error = hwcDisplay->present(&displayData.lastPresentFence);
后面的流程就跟 DEVICE 合成类似了,Display::present() 最终也会经过一系列的调用,通过 HwBinder 通知 HWC 的 Server 端,调用 presentDisplay() 将合成好的内容显示到屏幕上。
总结
说了这么多,一句话总结计算一个 App 的 fps 的原理就是:
统计在一秒内该 App 往屏幕刷了多少帧,而在 Android 的世界里,每一帧显示到屏幕的标志是: present fence signal 了,因此计算 App 的 fps 就可以转换为: 一秒内 App 的 Layer 有多少个有效 present fence signal 了 (这里有效 present fence 是指,在本次 VSYNC 中该 Layer 有更新的 present fence)。
长按右侧二维码
查看更多开发者精彩分享

"开发者说·DTalk" 面向中国开发者们征集 Google  移动应用 (apps & games) 相关的产品/技术内容。欢迎大家前来分享您对移动应用的行业洞察或见解、移动开发过程中的心得或新发现、以及应用出海的实战经验总结和相关产品的使用反馈等。我们由衷地希望可以给这些出众的中国开发者们提供更好展现自己、充分发挥自己特长的平台。我们将通过大家的技术内容着重选出优秀案例进行谷歌开发技术专家 (GDE) 的推荐。
移动应用 (apps & games) 相关的产品/技术内容。欢迎大家前来分享您对移动应用的行业洞察或见解、移动开发过程中的心得或新发现、以及应用出海的实战经验总结和相关产品的使用反馈等。我们由衷地希望可以给这些出众的中国开发者们提供更好展现自己、充分发挥自己特长的平台。我们将通过大家的技术内容着重选出优秀案例进行谷歌开发技术专家 (GDE) 的推荐。
 点击屏末 | 阅读原文 | 即刻报名参与 "开发者说·DTalk"
点击屏末 | 阅读原文 | 即刻报名参与 "开发者说·DTalk"

