基于C++的K-近邻分类算法实现
一、 算法简介
1. 简介
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
2. 原理举例
右图中,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角
形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
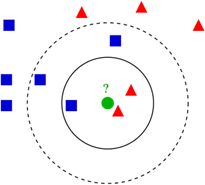
KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。更有用的方法是将不同距离的邻居对该样本产生的影响给予不同的权值(weight),如权值与距离成反比。
3. 算法过程
1. 准备数据,对数据进行预处理
2. 选用合适的数据结构存储训练数据和测试元组
3. 设定参数,如k
4.维护一个大小为k的的按距离由大到小的优先级队列,用于存储最近邻训练元组。随机从训练元组中选取k个元组作为初始的最近邻元组,分别计算测试元组到这k个元组的距离,将训练元组标号和距离存入优先级队列
5. 遍历训练元组集,计算当前训练元组与测试元组的距离,将所得距离L 与优先级队列中的最大距离Lmax
6. 进行比较。若L>=Lmax,则舍弃该元组,遍历下一个元组。若L < Lmax,删除优先级队列中最大距离的元组,将当前训练元组存入优先级队列。
7. 遍历完毕,计算优先级队列中k 个元组的多数类,并将其作为测试元组的类别。
8. 测试元组集测试完毕后计算误差率,继续设定不同的k值重新进行训练,最后取误差率最小的k 值
4. 常见问题
1) k值设定为多大?
k太小,分类结果易受噪声点影响;k太大,近邻中又可能包含太多的其它类别的点。(对距离加权,可以降低k值设定的影响)
k值通常是采用交叉检验来确定(以k=1为基准)
经验规则:k一般低于训练样本数的平方根。本次实验采用的就是k=训练样本数的平方根.
2) 类别如何判定最合适?
共有两种类别判定方法:
l 投票决定:少数服从多数,近邻中哪个类别的点最多就分为该类。
l 加权投票法:根据距离的远近,对近邻的投票进行加权,距离越近则权重越大(权重为距离平方的倒数)
投票法没有考虑近邻的距离的远近,距离更近的近邻也许更应该决定最终的分类,所以加权投票法更恰当一些。本次实验采用的是加权投票法
二、 算法实现
1. 训练数据
本次数据采用的是“泰坦尼克号“损失报告中的遇难者相关统计,1000个数据,每个样本共有4个变量。
变量说明:
l 乘客属性:0 = 乘员组, 1 = 首先, 2 = 第二, 3 = 第三
l 年龄: 1 = 成人, 0 = 孩子
l 性别: 1 = 男性, 0 = 女性
l 幸存与否:1 = 是, 0 = 没有
1) 训练数据——data.txt
l 文件内容:
n=1000,d=4
3 1 0 0
2 1 0 1
3 1 1 0
2 1 1 0
3 1 1 0
0 1 1 0
3 1 0 1
0 1 1 0
…
l 数据说明:
第一行表示共1000个数据,维度为4
以下为1000个数据
2. 测试数据
测试数据——testdata.txt
l 文件内容:
n=100,d=3
0 1 1
1 1 1
0 1 1
0 1 1
2 1 1
2 1 1
…
l 数据说明:
第一行表示共100个数据,维度为3(幸存与否这个特征为待分类特征没有录入,程序执行后进行对比即可)
以下为100个数据
3. 输出结果
输出数据——result.txt
l 文件内容:
0
0
1
0
…
l 数据说明:
该文本文件为测试数据的分类结果,0和1为两类(死亡与幸存),与真实结果对比即可
4. 程序运行截图
输出依次为输入的测试数据的三个特征和程序分类的结果。
5. 结果分析:
将得到的result.txt文件中的数据导入EXCEL分析,与真实情况对比,程序结果有74分类正确,正确率为74%。
6. C++源码
#include
#include
#include
#include
#include
using namespace std;
int N1=0;//训练数据个数,初始化为0
int N2=0;//测试数据个数
int M=0;//数据维数
int K=0;//K的取值
int T=2;//类别数目
struct point_distence//保存测试点到各个点的距离
{
int kind;//点的类别
float distence;//离该点距离
};
//动态创建二维数组
float **array(int m,int n)
{
int i;
float **p;
p=(float **)malloc(m*sizeof(float *));
p[0]=(float *)malloc(m*n*sizeof(float));
for(i=1;ip_distence[j+1].distence)
{
flag=0;
temp=p_distence[j];
p_distence[j]=p_distence[j+1];
p_distence[j+1]=temp;
}
}
if(flag)
break;
}
}
void classifi(float *k_distence,point_distence *distence)
{
for(int j=0;jtemp)
{
temp=k_distence[i];
j=i;
}
/* cout<<"-------------"<