tensorflow学习笔记——卷积神经网络的简单应用
数据集下载
本文用卷积神经网络实现MNIST数据集分类。可在这个网站下载MNIST数据集。下载后的数据如下图所示:
本文使用的网络包括2个卷积层和两个全连接层。卷积核大小为5×5,第一个卷积层有32个卷积核,第二个卷积层有64个卷积核。第一个全连接层有1024个节点,第二个全连接层有10个节点。
使用的激活函数为ReLU激活函数,优化器为Adam,ReLU+Adam也是我在论文里见的最多的搭配,最后一层我们还使用了softmax激活函数,这是多分类问题中最常用到的,最后使用交叉熵损失函数,softmax+交叉熵损失函数也是多分类问题最常用的搭配。
ReLU激活函数
公式:

图像:
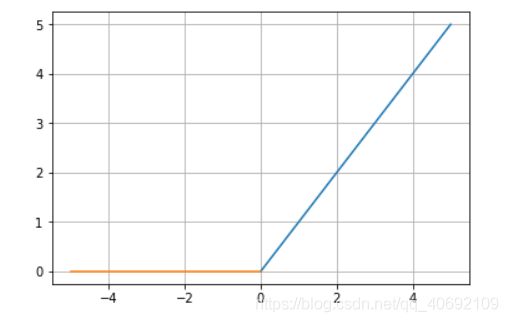
ReLU函数在x<0时,输出始终为0。由于x>0时,ReLU函数的导数为1,所以ReLU函数能够在x>0时保持梯度不断衰减,从而缓解梯度消失的问题,还能加快收敛速度,还能是神经网络具有稀疏性表达能力,因此它应该是目前使用最广泛的激活函数。
softmax激活函数
公式:
![]()
n为输出层参数总数。
此函数一般只用于网络的最后一层,用来将多个输出全部转化到0-1范围内,且和为1,通常是用来做多分类问题,即将输出转化为目标对应每个分类的概率。
交叉熵代价函数
![C=-\frac{1}{n}\sum_{i}^{n}[ylna+(1-y)ln(1-a)]](http://img.e-com-net.com/image/info8/5b478e88c7284f209eeea62505cfdfb8.gif)
- 其中,C表示代价函数,x表示样本,y表示实际值,a表示对应的输出值,n代表样本总数。
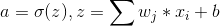
 是激活函数
是激活函数
权值w和偏置值b的梯度如下:


如果使用sigmoid激活函数,即有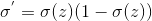 ,带入化简得:
,带入化简得:
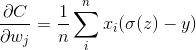

可以看出,w和b的梯度和预测值与真实值之差成正比,即预测值与真实值差距越大,w和b的大小调整得越快,训练收敛得就越快。和激活函数的梯度无关。(注意这里是在只有一个softmax激活函数的情况下无关)
Adam优化器
优点:
Adam 算法很容易实现,并且有很高的计算效率和较低的内存需求。Adam 算法梯度的对角缩放(diagonal rescaling)具有不变性,因此很适合求解带有大规模数据或参数的问题。该算法同样适用于解决大噪声和稀疏梯度的非稳态(non-stationary)问题。超参数可以很直观地解释,并只需要少量调整。
缺点:
不过Adam算法并不能保证找到极值点。其次,Adam算法在收敛到一个次优解时,观察到一些小批次样本贡献了大幅且有效的信息梯度,指数平均后减小了它们的影响,导致模型收敛性差。
代码实现
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
#载入数据
mnist = input_data.read_data_sets("E:/mnist",one_hot=True)
#每个批次大小
batch_size = 200
#计算一共有多少个批次
n_batch = mnist.train.num_examples//batch_size #整除
def weight_variable(shape):
initial = tf.truncated_normal(shape,stddev = 0.1)#用截断正态分布初始化
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1,shape=shape)
return tf.Variable(initial)
def conv2d(x,W):
return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding='SAME')
#步长4个值分别表示图片步长(一个批次多张图片),向右移动步长,向下移动步长,层数移动步长,SAME表示边缘补0
def max_pool(x):
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
x = tf.placeholder(tf.float32,[None,784])
y = tf.placeholder(tf.float32,[None,10])
#第一维:每个批次图片数,第二三维:图像宽高,第四维:图像层数
x_image = tf.reshape(x,[-1,28,28,1])
#第一层卷积
W_conv1 = weight_variable([5,5,1,32])#5×5的卷积核,图像层数为1,卷积核32个
b_conv1 = bias_variable([32])
conv1 = tf.nn.relu(conv2d(x_image,W_conv1)+b_conv1)
pool1 = max_pool(conv1)
#第二层卷积
W_conv2 = weight_variable([5,5,32,64])#5×5的卷积核,图像层数为32,卷积核64个
b_conv2 = bias_variable([64])
conv2 = tf.nn.relu(conv2d(pool1,W_conv2)+b_conv2)
pool2 = max_pool(conv2)
pool2_flat = tf.reshape(pool2,[-1,7*7*64])#将64张7×7的图片拉平
# 第一层全连接
W_fc1 = weight_variable([7*7*64,1024])
b_fc1 = bias_variable([1024])
fc1 = tf.nn.relu(tf.matmul(pool2_flat,W_fc1)+b_fc1)
keep_prob = tf.placeholder(tf.float32)
fc1_drop = tf.nn.dropout(fc1,keep_prob)
#第二层全连接
W_fc2 = weight_variable([1024,10])
b_fc2 = bias_variable([10])
#求损失函数
prediction = tf.nn.softmax(tf.matmul(fc1_drop,W_fc2)+b_fc2)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=y,logits=prediction))
#训练
train_step = tf.train.AdamOptimizer(1e-4).minimize(loss)
#求准确率
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))#equl判断是否相等,argmax返回张量最大值的索引
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32)) #将布尔型转换为浮点型
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(21):
for batch in range(n_batch):
batch_xs,batch_ys = mnist.train.next_batch(batch_size)
sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys,keep_prob:0.7})
acc = sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels,keep_prob:1.0})
print("Iter " + str(epoch) + " Accuracy" + str(acc)) 运行结果如下:
