

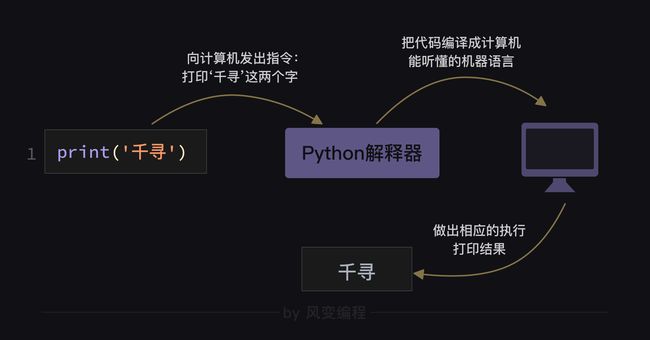
在Python的道路上,我们不仅要学习代码知识,还要建立自己的编程思维,逐步掌握与计算机沟通的方式,真正地实现“人机合作”。
思维1:条条大路通罗马;
#python基础语法要点
1.在print()函数内不仅能使用单引号,还能使用双引号,两者的效果没什么区别,都能让你打印出一行文本;
相应地,在括号内没有引号的情况下,我们应该往括号内放入计算机能够“理解”的内容,如:数字或数学运算。
在print内部使用三引号'''(连续输入三个单引号)来实现自动换行
print(520)
print('千寻')
print('let\'s go')


2.Python的运算符在写法上,与我们平时使用的运算符稍微有点区别。

3.浮点数的英文名是float-保持小数形式的3.8,与整数(int)和字符串(str)不同,浮点数没有简写。字符串类型,无法与整数类型666拼接。
word = '3.8'
number = 1
sentence = '人工智障说:3.8+1等于'
print(sentence+str(int(float(word)+number)))
4.for与else的平级问题


5.**偏移量,切片 **是左闭右开;包含左边的数字,不包括右边;
偏移量取到的是列表中的元素,而切片则是截取了列表的某部分;
list2 = [5,6,7,8,9]
print(list2[:])
print(list2[2:])
print(list2[:2])
print(list2[1:3])
print(list2[2:4])
bash:74$ python ~/classroom/apps-1-id-5c3d88f08939b4000100e7cf/74/main.py
[5, 6, 7, 8, 9]
[7, 8, 9]
[5, 6]
[6, 7]
[7, 8]
6.append后的括号里只能接受一个参数,但却给了两个,也就是4和5。所以,用append()给列表增加元素,每次只能增加一个元素。
删除del(语法是:del 列表名[元素的索引])
students = ['小明','小红','小刚']
students.append('小美')
print(students)
bash:97$ python ~/classroom/apps-1-id-5c3d88f08939b4000100e7cf/97/main.py
['小明', '小红', '小刚', '小美']
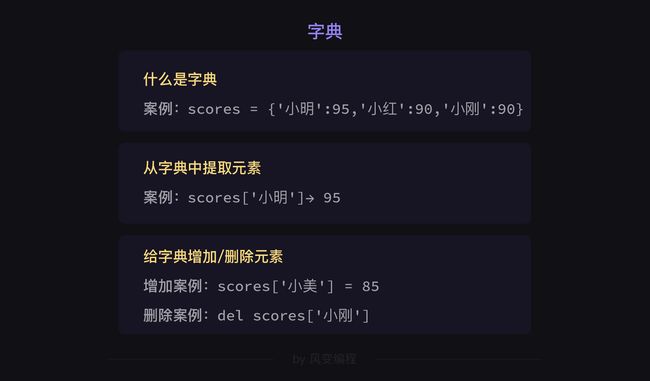
7.列表与字典不同,字典不能同append添加元素;
和列表一样,元组是可迭代对象,这意味着我们可以用for循环来遍历它
A.一个很重要的不同点是列表中的元素是有自己明确的“位置”的,所以即使看似相同的元素,只要在列表所处的位置不同,它们就是两个不同的列表。我们来看看代码:
students1 = ['小明','小红','小刚']
students2 = ['小刚','小明','小红']
print(students1 == students2)
scores1 = {'小明':95,'小红':90,'小刚':100}
scores2 = {'小刚':100,'小明':95,'小红':90}
print(scores1 == scores2)
False
True
8.for循环和whlie循环最大的区别在于【循环的工作量是否确定】,for循环就像空房间依次办理业务,直到把【所有工作做完】才下班。但while循环就像哨卡放行,【满足条件就一直工作】,直到不满足条件就关闭哨卡。
# 适合用for...in...循环
for i in '神雕侠侣':
print(i)
# 适合用while循环
password = ''
while password != '816':
password = input('请尝试输入密码:')

9.在Python中已经设定好什么数据为真,什么为假。假的是有限的,那么除了假的,就都是真的。请看下图:

bool()函数来查看一个数据会被判断为真还是假:
10.语句

if...break的意思是如果满足了某一个条件,就提前结束循环。记住,这个只能在循环内部使用。不是判断,是配合循坏使用的;
pass来占据一个位置表示“什么都不做”,以上的代码执行起来会报错:(请你先体验一下报错,然后把pass语句加上。)
11.整数8与字符串'8'的打印结果是一样的,所以选两种类型码都OK。但这种“都OK”的情况仅限于整数,对文字是行不通的;
print('我的幸运数字是%d' % 8) #8以整数展示
print('我的幸运数字是%s' % 8) #8以字符串展示
#整数8与字符串'8'打印出来的结果是一样的
12.函数
【不定长参数】就能派上用场,即不确定传递参数的数量。
它的格式比较特殊,是一个星号*加上参数名,来看下面的例子。
def menu(*barbeque):
print(barbeque)
menu('烤鸡翅','烤茄子','烤玉米')
#这几个值都会传递给参数barbeque
def menu(appetizer,course,*barbeque,dessert='绿豆沙'):
print('一份开胃菜:'+appetizer)
print('一份主菜:'+course)
print('一份甜品:'+dessert)
for i in barbeque:
print('一份烤串:'+i)
menu('话梅花生','牛肉拉面','烤鸡翅','烤茄子','烤玉米')
一份开胃菜:话梅花生
一份主菜:牛肉拉面
一份甜品:绿豆沙
一份烤串:烤鸡翅
一份烤串:烤茄子
一份烤串:烤玉米

13.变量结构域
x=99 #全局变量x
def num():
x=88 #局部变量x
print(x)
num()
#打印局部变量x
print(x)
#打印全局变量x
两种编程思维——面向对象与面向过程
在这里,我们直接面对的是机器人,而非炒菜的过程,所以这里机器人就是我们面对的对象,这种解决问题的方法就叫做【面向对象】编程。
面向过程编程,看重的是解决问题的过程。
既然【类】是一个函数包,所以一个类中可以放置一堆函数,就像这样:(如前文所说,以下例子会用中文取名)
class 类A():
def 函数1():
print('报道!我是类A的第一个方法!')
def 函数2():
print('报道!我是类A的第二个方法!')
def 函数3():
print('报道!我是类A的第三个方法!')



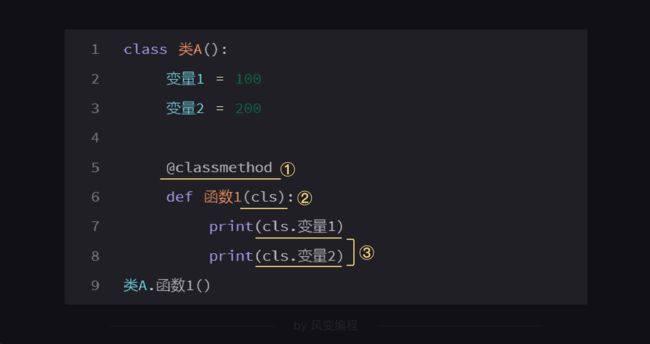
① 第一个格式@classmethod的中文意思就是“类方法”,@classmethod声明了函数1是类方法,这样才能允许函数1使用类属性中的数据。
② 第二个格式cls的意思是class的缩写。如果类方法函数1想使用类属性(也就是类中的变量),就要写上cls为函数1的第一个参数,也就是把这个类作为参数传给自己,这样就能被允许使用类中的数据。
③ 第三个格式是cls.变量。类方法想使用类属性的时候,需要在这些变量名称前加上cls.。
这就好比类方法和类之间的约法三章,所以但凡有任何格式错误都会报错。
如果缺①,即缺了“@classmethod”,类方法就不能直接利用类中的属性,于是报错。(请运行代码,报错后,修改格式到正确的样式就能运行通过)
另外,当类中的函数【不需要】用到类中的变量时,就不要用@classmethod、cls、cls.三处格式,否则就是占着茅坑不拉屎,终端也会给你报错。(没错,就是这么傲娇~)
*类方法和函数类似,也可以传递参数。我们把上面的函数"收编",
class 加100类():
def 加100函数(参数):
总和 = 参数 + 100
print('计算结果如下:')
print(总和)
参数 = 1
加100类.加100函数(参数)


看的明白吗?①是调用类方法评级,②是在评级内部调用了类方法计算平均分,③④是类方法计算平均分的过程,最后返回的值重新赋值给了评级中的类属性平均分。
这里有个小点要注意,def 评级(cls)中的平均分和def 计算平均分(cls)的平均分,是两个不同的变量,因为它们在不同的函数下工作,作用域不同。(可以回顾第10关“变量的作用域”相关知识)
类与对象:

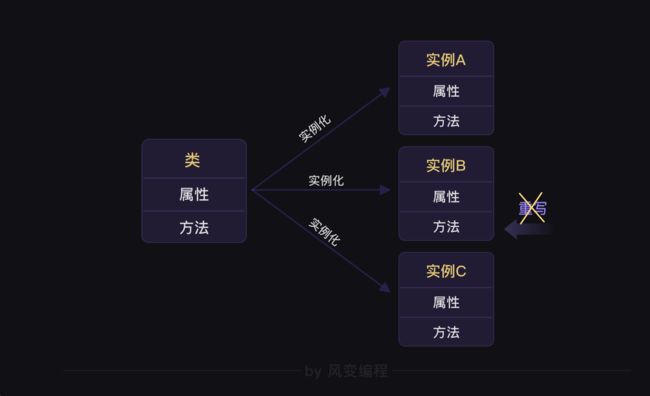
1.可以把 【类】实例化为多个【实例对象】,然后让每个【实例对象】各就各位。
# 把成绩单()类实例化为成绩单1、成绩单2、成绩单3三个【实例对象】。(15-17行代码是关键)
class 成绩单():
def 录入成绩单(self):
self.学生姓名 = input('请输入学生姓名:')
self.语文_成绩 = int(input('请输入语文成绩:'))
self.数学_成绩 = int(input('请输入数学成绩:'))
def 打印成绩单(self):
print(self.学生姓名 + '的成绩单如下:')
print('语文成绩:'+ str(self.语文_成绩))
print('数学成绩:'+ str(self.数学_成绩))
成绩单1 = 成绩单() # 实例化,得到实例对象“成绩单1”
成绩单2 = 成绩单() # 实例化,得到实例对象“成绩单2”
成绩单3 = 成绩单() # 实例化,得到实例对象“成绩单2”
print('现在开始录入三份成绩单:')
成绩单1.录入成绩单()
成绩单2.录入成绩单()
成绩单3.录入成绩单()
print('现在开始打印三份成绩单:')
成绩单1.打印成绩单()
成绩单2.打印成绩单()
成绩单3.打印成绩单()
2.类实例化与直接使用类要注意,当类需要被实例化后再使用时,和直接使用类的格式是不同的。

如何使用【实例】,使用【实例】和直接使用【类】有什么区别?
通过对比可以看到,实例化后再使用的格式,①是空着的,意思是这里不再需要@classmethod的声明,并且在第②处,把cls替换成了self。

# 直接使用类
class 成绩单():
@classmethod
def 录入成绩单(cls):
cls.学生姓名 = input('请输入学生姓名:')
cls.语文_成绩 = int(input('请输入语文成绩:'))
cls.数学_成绩 = int(input('请输入数学成绩:'))
@classmethod
def 打印成绩单(cls):
print(cls.学生姓名 + '的成绩单如下:')
print('语文成绩:'+ str(cls.语文_成绩))
print('数学成绩:'+ str(cls.数学_成绩))
成绩单.录入成绩单()
成绩单.打印成绩单()
# 实例化之后
class 成绩单(): # ①不用再写@classmethod
def 录入成绩单(self): # ②cls变成self
self.学生姓名 = input('请输入学生姓名:') # ③cls.变成self.
self.语文_成绩 = int(input('请输入语文成绩:'))
self.数学_成绩 = int(input('请输入数学成绩:'))
def 打印成绩单(self):
print(self.学生姓名 + '的成绩单如下:')
print('语文成绩:'+ str(self.语文_成绩))
print('数学成绩:'+ str(self.数学_成绩))
成绩单1 = 成绩单() # ④创建实例对象:成绩单1
成绩单1.录入成绩单() # ⑤实例化后使用
成绩单1.打印成绩单()
另外提一下,cls代表“类”的意思,self代表“实例”的意思,这样写是编码规范(程序员们的共识),但不是强制要求。理论上只要写个变量名占位,写什么都行,比如把self写成bbb:
另外,当类支持实例化的时候,就不能再直接使用类方法了,如果运行以下代码将会报错:(报错后请点击跳过按钮)
#实例化后,直接使用类方法会报错
智能机器人.自报三围()
自报三围() missing 1 required positional argument: 'self'
我们都是把类实例化后再调用。(哪怕取一个和类名相同的实例名称也可以)
# 注意:【下方取了一个和类名相同的实例名】
class 成绩单():
def 录入成绩单(self):
self.学生姓名 = input('请输入学生姓名:')
self.语文_成绩 = int(input('请输入语文成绩:'))
self.数学_成绩 = int(input('请输入数学成绩:'))
def 打印成绩单(self):
print(self.学生姓名 + '的成绩单如下:')
print('语文成绩:'+ str(self.语文_成绩))
print('数学成绩:'+ str(self.数学_成绩))
成绩单 = 成绩单() # 【请注意这里取了一个和类名相同的实例名】
成绩单.录入成绩单()
成绩单.打印成绩单()
我们知道了如何用类生成多个实例对象,那实例的属性和方法,与类的属性和方法有什么关系呢?
类和实例的关系,就像母体和复制品的关系一样。当一个类实例化为多个实例后,实例将原封不动的获得类属性,也就是实例属性和类属性完全相等。

可以修改实例属性,但这不会影响到其他实例,也不会影响到类。因为每个实例都是独立的个体。

和类属性一样,我们可以重写类方法,这会导致所有实例方法自动被重写。

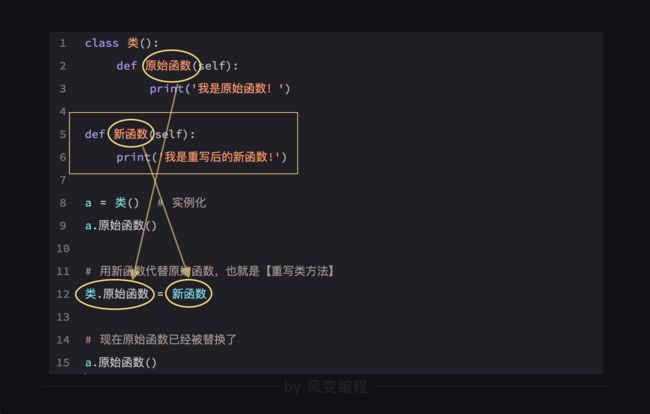
**要注意的是,这里的赋值是在替换方法,并不是调用函数,所以【不要加上括号】—— 写成类.原始函数() = 新函数()是错误的。
我们可以通过重写类方法,让实例方法发生变化,但我们不能重写实例方法,模板给的技能不是说换就能换的。
初始化函数后,我们可以直接把需要录入的信息作为参数传递给成绩单1、成绩单2、成绩单3这三个实例对象。
class 成绩单():
def __init__(self,学生姓名,语文_成绩,数学_成绩):
self.学生姓名 = 学生姓名
self.语文_成绩 = 语文_成绩
self.数学_成绩 = 数学_成绩
def 打印成绩单(self):
print(self.学生姓名 + '的成绩单如下:')
print('语文成绩:'+ str(self.语文_成绩))
print('数学成绩:'+ str(self.数学_成绩))
成绩单1 = 成绩单('张三',99,88)
成绩单2 = 成绩单('李四',64,73)
成绩单3 = 成绩单('王五',33,22)
成绩单1.打印成绩单()
成绩单2.打印成绩单()
成绩单3.打印成绩单()
实例:通过初始化函数传递参数,从而控制了三三乘法表、五五乘法表这些实例的打印行数,这里的数据流转图如下!

“类的继承”
1.类的继承很大程度也是为了避免重复性劳动。比如说当我们要写一个新的类,如果新的类有许多代码都和旧类相同,又有一部分不同的时候,就可以用“继承”的方式避免重复写代码。


顾名思义,“多重继承”就是一个子类从【多个父类】中继承类方法。格式是class 子类(父类1,父类2,……)。
2.子类除了可以定制新的类方法,还能直接覆盖父类的方法(可类比富二代男主推翻了老爹管理公司的做派),只要使用相同的类方法名称就能做到这一点。
class 基础机器人():
def __init__(self,参数):
self.姓名 = 参数
def 自报姓名(self):
print('我是' + self.姓名 + '!')
def 卖萌(self):
print('主人,求抱抱!')
class 高级机器人(基础机器人):
def 卖萌(self): # 这里使用了相同的类方法名称“卖萌”,这样可以让子类方法覆盖父类方法
print('主人,每次想到怎么欺负你的时候,就感觉自己全身biubiubiu散发着智慧的光芒!')
鲁宾 = 基础机器人('鲁宾')
鲁宾.自报姓名()
鲁宾.卖萌() # 调用父类方法
安迪 = 高级机器人('安迪')
安迪.自报姓名()
安迪.卖萌() # 父类方法被子类中的同名方法覆盖
bash:164$ python ~/classroom/apps-1-id-5c3d88f18939b4000100e7dc/164/main.py
我是鲁宾!
主人,求抱抱!
我是安迪!
主人,每次想到怎么欺负你的时候,就感觉自己全身biubiubiu散发着智慧的光芒!
多重继承
像这样,子类从【一个父类】继承类方法,我们叫做“单继承”。还有一种更复杂的继承情况,叫“多重继承”。

顾名思义,“多重继承”就是一个子类从【多个父类】中继承类方法。格式是class 子类(父类1,父类2,……)。
多重继承有利有弊。过度使用继承容易把事情搞复杂,就像一个人有很多爸爸必定会带来诸多麻烦。
class 基础机器人():
def 卖萌(self):
print('主人,求抱抱!')
# 注:因为多重继承要求父类是平等的关系,所以这里的“高级机器人”没有继承“基础机器人”
class 高级机器人():
def 高级卖萌(self):
print('主人,每次想到怎么欺负你的时候,就感觉自己全身biubiubiu散发着智慧的光芒!')
class 超级机器人(基础机器人,高级机器人):
def 超级卖萌(self):
print('pika, qiu!')
print(''' へ /|
/\7 ∠_/
/ │ / /
│ Z_,< / /`ヽ
│ ヽ / 〉
Y ` / /
イ● 、 ● ⊂⊃〈 /
() へ | \〈
>ー、_ ィ │//
/へ / ノ<|\\
ヽ_ノ (_/ │//
7 |/
>―r ̄ ̄`ー―_''')
皮卡 = 超级机器人()
皮卡.卖萌()
皮卡.高级卖萌()
皮卡.超级卖萌()

15 字符与编码:
中国科学家自力更生,重写了一张编码表,也就是GB2312,它用2个字节,也就是16个比特位,来表示绝大部分(65535个)常用汉字。后来,为了能显示更多的中文,又出台了GBK标准。

为了沟通的便利,Unicode(万国码)应运而生,这套编码表将世界上所有的符号都纳入其中。每个符号都有一个独一无二的编码,现在Unicode可以容纳100多万个符号,所有语言都可以互通,一个网页上也可以显示多国语言。
看起来皆大欢喜。但是!问题又来了,自从英文世界吃上了Unicode这口大锅饭,为迁就一些占用字节比较多的语言,英文也要跟着占两个字节。比如要存储A,原本00010001就可以了,现在偏得用两个字节:00000000 00010001才行,这样对计算机空间存储是种极大的浪费!
基于这个痛点,科学家们又提出了天才的想法:UTF-8(8-bit Unicode Transformation Format)。它是一种针对Unicode的可变长度字符编码,它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度,而当字符在ASCII码的范围时,就用一个字节表示,所以UTF-8还可以兼容ASCII编码。

Unicode与UTF-8这种暧昧的关系一言以蔽之:Unicode是内存编码的规范,而UTF-8是如何保存和传输Unicode的手段。
0,计算机是有自己的工作区的,这个工作区被称为“内存”。数据在内存当中处理时,使用的格式是Unicode,统一标准。
1,数据在硬盘上存储,或者是在网络上传输时,用的是UTF-8,因为节省空间。但你不必操心如何转换UTF-8和Unicode,当我们点击保存的时候,程序已经“默默地”帮我们做好了编码工作。
encode()和decode()
【编码】encode();反之,就是【解码】decode()。
print('吴枫'.encode('utf-8'))
print('吴枫'.encode('gbk'))
print(b'\xe5\x90\xb4\xe6\x9e\xab'.decode('utf-8'))
print(b'\xce\xe2\xb7\xe3'.decode('gbk'))
将人类语言编码后得到的结果,有一个相同之处,就是最前面都有一个字母b,比如b'\xce\xe2\xb7\xe3',这代表它是bytes(字节)类型的数据。
\x是分隔符,用来分隔一个字节和另一个字节。
分隔符还挺常见的,我们在上网的时候,不是会有网址嘛?你经常会看到网址里面有好多的%,它们也是分隔符,替换了Python中的\x。比如像下面这个:
%=\x
https://www.baidu.com/s?wd=%E5%90%B4%E6%9E%AB
【文件读写】,是分为【读】和【写】两部分的
文件的地址有两种:相对路径和绝对路径,拖到终端获取的地址是绝对路径。这两种地址,Mac和Windows电脑还有点傲娇地不太一样,下面我就帮大家捋一捋。

假如现在这个txt文件,是放在test文件夹下面一个叫做word的文件夹里,绝对路径和相对路径就变成:
open('/Users/Ted/Desktop/test/word/abc.txt'')
open('word/abc.txt')
Windows系统里,常用\来表示绝对路径,/来表示相对路径,
但是呢,别忘了\在Python中是转义字符,所以时常会有冲突。为了避坑,Windows的绝对路径通常要稍作处理,写成以下两种格式;
open('C:\\Users\\Ted\\Desktop\\test\\abc.txt')
#将'\'替换成'\\'
open(r'C:\Users\Ted\Desktop\test\abc.txt')
#在路径前加上字母r
file1 = open('/Users/Ted/Desktop/test/abc.txt','r',encoding='utf-8')
除了'r',其他还有'w'(写入),'a'(追加)等模式,我们稍后会涉及到。
'w'写入模式会给你暴力清空掉文件,然后再给你写入。如果你只想增加东西,而不想完全覆盖掉原文件的话,就要使用'a'模式,表示append,你学过,它是追加的意思。
#文件读写必须先读,后打印;
f = open('./1.txt', 'a',encoding='utf-8')
f.write('难忘的经')
print(f)
<_io.TextIOWrapper name='./1.txt' mode='a' encoding='utf-8'>
------------------------------------------------------
f1 = open('./1.txt','a',encoding='utf-8')
#以追加的方式打开一个文件,尽管并不存在这个文件,但这行代码已经创建了一个txt文件了
f1.write('难念的经')
#写入'难念的经'的字符串
f1.close()
#关闭文件
f2 = open('./1.txt','r',encoding='utf-8')
#以读的方式打开这个文件
content = f2.read()
#把读取到的内容放在变量content里面
print(content)
#打印变量content
f2.close()
#关闭文件
难念的经

'wb'的模式,它的意思是以二进制的方式打开一个文件用于写入。因为图片和音频是以二进制的形式保存的,所以使用wb模式就好了,这在今天的课后作业我们会用到。
为了避免打开文件后忘记关闭,占用资源或当不能确定关闭文件的恰当时机的时候,我们可以用到关键字with,之前的例子可以写成这样:
# 普通写法
file1 = open('abc.txt','a')
file1.write('张无忌')
file1.close()
# 使用with关键字的写法
with open('abc.txt','a') as file1:
#with open('文件地址','读写模式') as 变量名:
#格式:冒号不能丢
file1.write('张无忌')
#格式:对文件的操作要缩进
#格式:无需用close()关闭
#图片,音视频读写:
with open('photo2.png','rb') as file: # 以“rb”模式打开图片
data = file.read()
with open('photo3.png','wb') as newfile: # 以“wb”模式写入
newfile.write(data)
程序模块



import story
if __name__ == '__main__':
print(story.sentence)
story.mountain()
print(story.Temple.sentence)
story.Temple.reading()
A = story.Story()
print(A.sentence)
A.reading()
print()
- f name == 'main',我先给大家讲解一个概念“程序的入口”。
对于Python和其他许多编程语言来说,程序都要有一个运行入口。
在Python中,当我们在运行某一个py文件,就能启动程序 ——— 这个py文件就是程序的运行入口。

自学模块


学习模块的核心是搞清楚模块的功能,也就是模块中的函数和类方法有什么作用,以及具体使用案例长什么样。
import random # 调用random模块
print(dir(random))
#这就像是查户口一样,可以把模块中的函数(函数和类方法)一览无余地暴露出来。对于查到的结果“__xx__”结构的,它们是系统相关的函数,我们不用理会,直接看全英文的函数名即可。
学习csv模块

import csv
# dir()函数会得到一个列表,用for循环一行行打印列表比较直观
for i in dir(csv):
print(i)


学完了模块,所有的基础知识你也学习完毕了。从今天起,你已经不再是一个麻瓜了。
之于编程的魔法世界,你已经能看明白这个世界的构造,懂得学习的方法和进阶的路径,我们称之为初窥门径。
再往后你需要的只是想明白自己想去这个世界的哪个地方——是网络爬虫,是数据分析,还是图像识别?然后,去付出时间和努力。
这是我们当下的仰望星空,但并非终点。如果你肯把头抬得更高,你还能看到另一片更广阔的天地,是开源精神培育的热土。
这就是开源精神,这就是黑客文化,整个互联网世界最为宝贵的财富,没有之一。
项目实战
编程是一个开源的世界,每时每刻都有新的知识产生,要想进步,就要学会学习。
而且我也没有办法每个知识点都教给大家,为了解决这种无力感,能想到的办法就是:提高大家学习知识的能力。
所以在学习模块的时候,希望大家能把注意力分一点到另一条隐形的主线【学习方法】上。


版本1.0,主要是根据需求,自己寻找和学习相关的模块,然后给自己发一封最简单的邮件。
版本2.0呢,还是给自己发邮件,但邮件应该更完整,包括邮件头(就是发件人、邮件标题等),和正文内容。
版本3.0呢,主要是从单一收件人,变成多收件人,也就是群发一封完整的邮件。
三个版本的难度稍有递进,接下来就是闯关时间了。
编程世界中,我们不需要什么知识都一把抓,而是遇到问题之后,产生了某种需求,才会去找对应的解决方案。
这个方案可能是某个模块,也可能是某个函数~
就像在第一个PK小游戏项目中,我们想:要是能够随机生成某个区间内的数字,替代固定的血量值,可能会好一点。于是我们就学习并引入了random模块。
其实,只要搜索关键词“发送邮件 python”,就能找到解决方案。

搜索后你看到这样的页面,不用逐一点进去看就能知道:1.Python可以解决这个问题;2.方法是smtplib,email这两个模块。
而且还会知道:smtplib是用来发送邮件用的,email是用来构建邮件内容的。这两个都是Python内置模块。
一般,提供的关键字越多,搜索引擎返回的结果越精确。我们可以使用+号或者空格连接关键词,也可使用之前学习的and和or来连接,其含义和之前学习的一样,分别表示“并且”和“或者”。
重新搜索一次,关键词换成 “smtplib 教程” ,你就能看到好多好多中国人编写的内容。在可读性上,是要比官方文档好一些的,但缺点在于良莠不齐。你可以自行挑选适合自己的去阅读。
上一关我们总结了模块三问:函数;属性或方法;格式。今天学习的两个模块比较简单,我们就不一一回答了,我们直接带着两个问题去学。

import smtplib
server = smtplib.SMTP()
server.connect(host, port)
server.login(username, password)
server.sendmail(sender, to_addr, msg.as_string())
server.quit()
SMTP (Simple Mail Transfer Protocol)翻译过来是“简单邮件传输协议”的意思,SMTP 协议是由源服务器到目的地服务器传送邮件的一组规则。
可以简单理解为:我们需要通过SMTP指定一个服务器,这样才能把邮件送到另一个服务器。
server = smtplib.SMTP()
server.connect(host, port)
第四行代码,就是干这个工作的,连接(connect)指定的服务器。
host是指定连接的邮箱服务器,你可以指定服务器的域名。通过搜索“xx邮箱服务器地址”,就可以找到。
port 是“端口”的意思。端口属于计算机网络知识里的内容,你可以自行搜索了解,现在我们只要知道它是一个【整数】即可。
我们需要指定SMTP服务使用的端口号,一般情况下SMTP默认端口号为25。
如果25行不通,你可以通过搜索或者去邮箱设置里面查看端口。比如,如果我打算用自己的企业邮箱来发邮件,登录邮箱后,在【设置-选项-POP和IMAP】里面可以看到这些信息:

