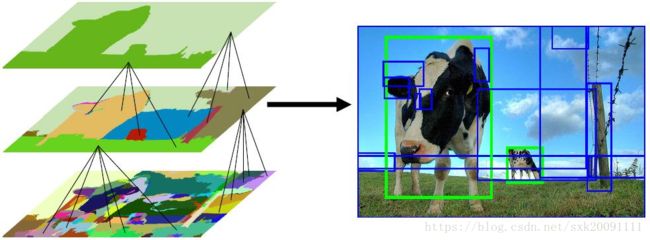
Selective Search实现过程分析
Selective Search是以图像分割为基础,依据图像的色彩纹, 纹理,和尺寸的相似度,输出所有目标可能的位置,为后续的目标检测识别提供基础。
整个算法包含以下几个部分:
1.图像分割
通过图像分割给出了所有可能的分割小区域,每个区域的像素都有对应的区域标签属性。
2.提取区域
(1)将每一个分割子区域所对应的外包围矩形构建出来,通过如下的方式:
for y, i in enumerate(img):
for x, (r, g, b, l) in enumerate(i):
# initialize a new region
if l not in R:
R[l] = {
"min_x": 0xffff, "min_y": 0xffff,
"max_x": 0, "max_y": 0, "labels": [l]}
# bounding box
if R[l]["min_x"] > x:
R[l]["min_x"] = x
if R[l]["min_y"] > y:
R[l]["min_y"] = y
if R[l]["max_x"] < x:
R[l]["max_x"] = x
if R[l]["max_y"] < y:
R[l]["max_y"] = y
这里就是遍历轮廓区域内所有的像素找到最大坐标值和最小坐标值
(2)计算图像的纹理,这里的纹理可以采用LBP的纹理特征:

LBP代码:http://www.cse.oulu.fi/CMV/Downloads/LBPMatlab
(3) 计算纹理直方图
(4) 计算颜色的直方图统计
4.构造邻居组(区域外包围矩形框有重合的就是相邻的)
相邻有四种情况:
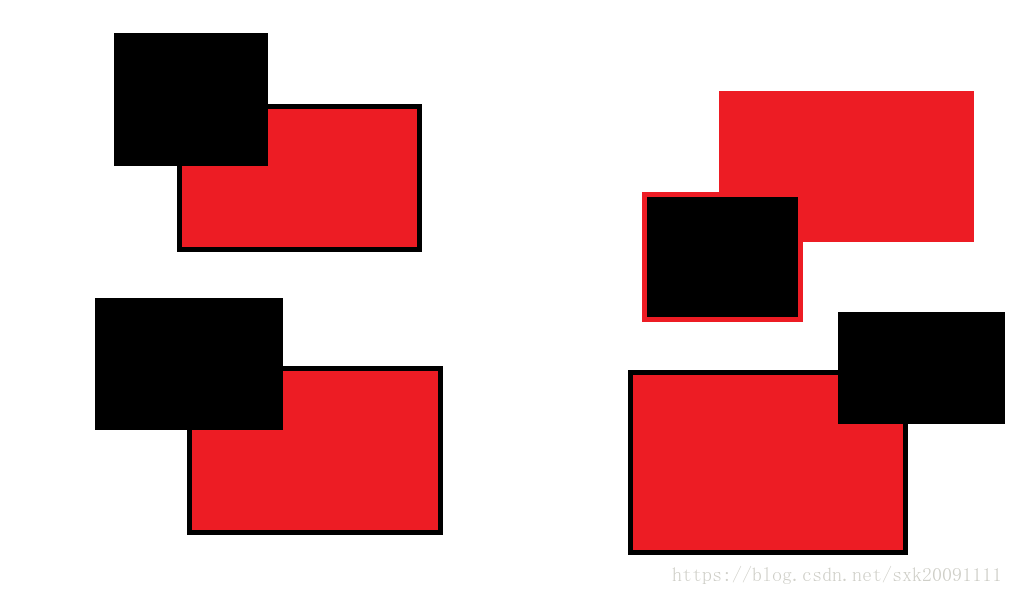
if (a["min_x"] < b["min_x"] < a["max_x"]
and a["min_y"] < b["min_y"] < a["max_y"]) or (
a["min_x"] < b["max_x"] < a["max_x"]
and a["min_y"] < b["max_y"] < a["max_y"]) or (
a["min_x"] < b["min_x"] < a["max_x"]
and a["min_y"] < b["max_y"] < a["max_y"]) or (
a["min_x"] < b["max_x"] < a["max_x"]
and a["min_y"] < b["min_y"] < a["max_y"]):
5.计算邻居组集合中的每一对的相似度距离:
相似度距离包含四种距离
(1) 颜色相似度计算:
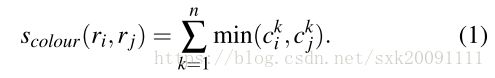
S_c= sum([min(a, b) for a, b in zip(r1["hist_c"], r2["hist_c"])])
(2)纹理相似度计算:
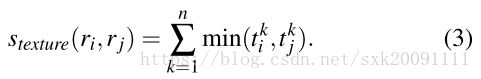
S_t= sum([min(a, b) for a, b in zip(r1["hist_t"], r2["hist_t"])])
(3)计算区域相对于图像的尺寸,目的是让尺寸较小的优先合并
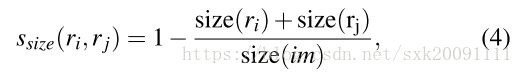
S_s = 1.0 - (r1["size"] + r2["size"]) / imsize
(4) 计算两个区域交叉的尺寸相对于图像的尺寸。目的是让相交区域大的优先合并
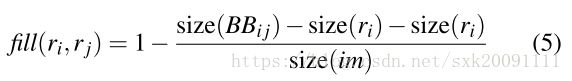
bbsize = (
(max(r1["max_x"], r2["max_x"]) - min(r1["min_x"], r2["min_x"]))
* (max(r1["max_y"], r2["max_y"]) - min(r1["min_y"], r2["min_y"]))
S_f = 1.0 - (bbsize - r1["size"] - r2["size"]) / imsize
将前面几个距离加权求和
D= a1 * S_c + a2 * S_t + a3 * S_s + a4 * S_f
6 .合并区域
(1)找到集合里面相识度最大的那一对
(2)将这一对的外包围区域进行合并,包括构建新的外包围矩形框,同时计算根据以下公式更新颜色直方图统计和纹理直方图统计,这样构建新的区域rt。
new_size = r1["size"] + r2["size"]
rt["hist_c"] = r1["hist_c"] * r1["size"] + r2["hist_c"] * r2["size"]) / new_size
rt["hist_t"] = r1["hist_t"] * r1["size"] + r2["hist_t"] * r2["size"]) / new_size
(3) 将集合中的r1, r2从集合中去掉
key_to_delete = []
for k, v in list(S.items()):
if (i in k) or (j in k):
key_to_delete.append(k)
for k in key_to_delete:
del S[k]
(4) 将新的rt与之前的r1, r2的邻居构成新的pair放到集合中去,并计算相应的相似度距离
for k in [a for a in key_to_delete if a != (i, j)]:
n = k[1] if k[0] in (i, j) else k[0]
S[(t, n)] = _calc_sim(R[t], R[n], imsize)
(5)重复(1)到(4)的步骤,直到集合中不存在任何元素为止。
最后输出所有的矩形框结果。
代码:https://github.com/AlpacaDB/selectivesearch