一、卷积神经网络简介
卷积神经网络(Convolutional Neural Network,CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。 它包括卷积层(convolutional layer)和池化层(pooling layer)。
一般地,CNN的基本结构包括两层,其一为特征提取层,每个神经元的输入与前一层的局部接受域相连,并提取该局部的特征。一旦该局部特征被提取后,它与其它特征间的位置关系也随之确定下来;其二是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。此外,由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数。卷积神经网络中的每一个卷积层都紧跟着一个用来求局部平均与二次提取的计算层,这种特有的两次特征提取结构减小了特征分辨率。
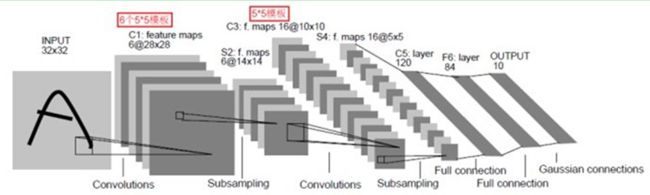
这是一个最典型的卷积网络,由卷积层、池化层、全连接层组成。其中卷积层与池化层配合,组成多个卷积组,逐层提取特征,最终通过若干个全连接层完成分类。
卷积层完成的操作,可以认为是受局部感受野概念的启发,而池化层,主要是为了降低数据维度。
综合起来说,CNN通过卷积来模拟特征区分,并且通过卷积的权值共享及池化,来降低网络参数的数量级,最后通过传统神经网络完成分类等任务。
二、卷积神经网络常用结构
1、卷积层
CNN最重要的部分就是卷积核。又称为过滤器或内核。
---恢复内容结束---
一、卷积神经网络简介
卷积神经网络(Convolutional Neural Network,CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。 它包括卷积层(convolutional layer)和池化层(pooling layer)。
一般地,CNN的基本结构包括两层,其一为特征提取层,每个神经元的输入与前一层的局部接受域相连,并提取该局部的特征。一旦该局部特征被提取后,它与其它特征间的位置关系也随之确定下来;其二是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。此外,由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数。卷积神经网络中的每一个卷积层都紧跟着一个用来求局部平均与二次提取的计算层,这种特有的两次特征提取结构减小了特征分辨率。
这是一个最典型的卷积网络,由卷积层、池化层、全连接层组成。其中卷积层与池化层配合,组成多个卷积组,逐层提取特征,最终通过若干个全连接层完成分类。
卷积层完成的操作,可以认为是受局部感受野概念的启发,而池化层,主要是为了降低数据维度。
综合起来说,CNN通过卷积来模拟特征区分,并且通过卷积的权值共享及池化,来降低网络参数的数量级,最后通过传统神经网络完成分类等任务。
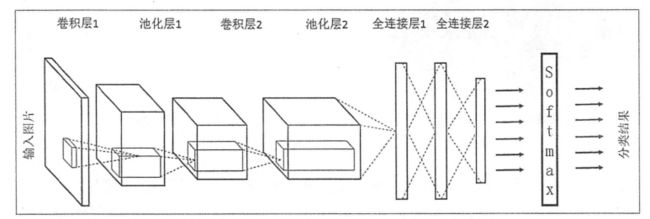
二、卷积神经网络常用结构
1、卷积层
CNN最重要的部分就是卷积核。又称为过滤器或内核。
CNN最重要的部分就是卷积核。又称为过滤器或内核。
共享每一个卷积层中过滤器的参数可以巨幅减少神经网络中的参数。
f(X.W+b)
为了避免尺寸变化,可以在当前层矩阵的边界中加入全0填充。
TensorFlow对卷积神经网络提供了非常好的支持,下面的程序实现了一个卷积层的前向传播过程。
# -*- coding:utf-8 -*- import tensorflow as tf import numpy as np #通过tf.get_variable的方式创建过滤器的权重和偏置。 x = np.random.randn(4,5) filter_weight = tf.get_variable("weight",[5,5,3,16],initializer=tf.truncated_normal_initializer(stddev=0.1)) #和卷积层的权重类似,当前层不同位置的偏置项也是共享的。 biases = tf.get_variable("biases",shape=[16],initializer=tf.constant_initializer(0.1)) #tf.nn.conv2d 提供了一个非常方便的函数来实现卷积层前向传播算法。 conv=tf.nn.conv2d(x,filter_weight,strides=[1,1,1,1],padding="SAME") # tf.nn.bias_add函数给每个节点增加偏执项 bias = tf.nn.bias_add(conv,biases) #通过relu激活函数去线性化 active_conv = tf.nn.relu(bias)
2池化层
池化层可以非常有效的缩小矩阵的尺寸, 从而减少后面全连接层的参数。使用池化层可以有效的加快计算速度,也可以防止过拟合。
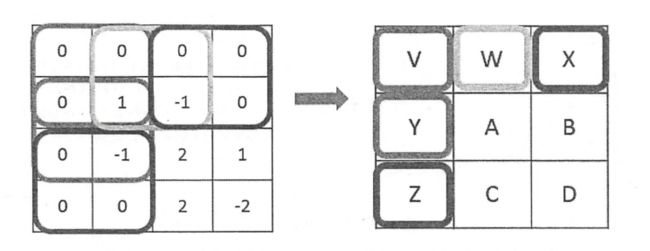
池化层的过滤器不是加权求和,而是采用最大值或平均值运算。
池化层过滤器的移动和填充方式与卷积层的类似,唯一的区别是卷积层的过滤器是横跨整个深度的,而池化层使用的过滤器只影响一个深度上的节点。
3 经典的卷积神经网络
3.1 LeNet-5模型
模型总共七层,模型的结构如下
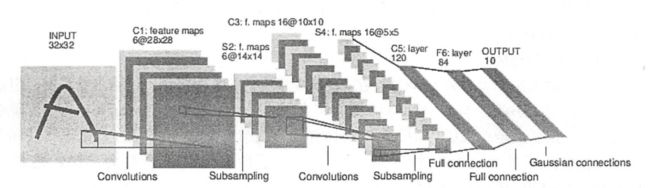
用TF来实现
#mnsit_inference # -*- coding:utf-8 -*- import tensorflow as tf #定义神经网络的参数 INPUT_NODE = 784 OUTPUT_NODE = 10 IMAGE_SIZE = 28 NUM_CHANNELS = 1 NUM_LABELS = 10 #第一层conv参数 CONV1_DEEP = 32 CONV1_SIZE = 5 #第二层卷积层参数 CONV2_DEEP = 64 CONV2_SIZE = 5 #全连接层节点个数 FC_SIZE = 512 #定义神经网络的前向传播过程.这里添加了一个新的参数train ,用于区分训练过程和测试过程。在这个过程中将用到dropout方法。dropout方法只在训练中使用。 def inference(input_tensor,train,regularizer): #第一层卷积层 with tf.variable_scope("layer1_conv1"): conv1_weights = tf.get_variable("wight",[CONV1_SIZE,CONV1_SIZE,NUM_CHANNELS,CONV1_DEEP],initializer=tf.truncated_normal_initializer(stddev=0.1)) conv1_biases = tf.get_variable("bias",shape=[CONV1_DEEP],initializer=tf.constant_initializer(0.0)) #使用边长为5,深度为32 的过滤器,过滤器的移动步长为1,填充为全0 conv1 = tf.nn.conv2d(input_tensor,conv1_weights,strides=[1,1,1,1],padding="SAME") relu1 = tf.nn.relu(tf.nn.bias_add(conv1,conv1_biases)) #第二层pooling with tf.variable_scope("layer2_pool1"): pool1 = tf.nn.max_pool(relu1,ksize=[1,2,2,1],strides=[1,2,2,1],padding="SAME") #第三层,卷积层 with tf.variable_scope("layer3_conv2"): conv2_weights = tf.get_variable("weight",[CONV2_SIZE,CONV2_SIZE,CONV1_DEEP,CONV2_DEEP],initializer=tf.truncated_normal_initializer(stddev=0.1)) conv2_biases = tf.get_variable('bias',[CONV2_DEEP],initializer=tf.constant_initializer(0.0)) #使用边长为5,深度为64 的过滤器,过滤器的移动步长为1,填充为全0 conv2 = tf.nn.conv2d(pool1,conv2_weights,strides=[1,1,1,1],padding="SAME") relu2 = tf.nn.relu(tf.nn.bias_add(conv2,conv2_biases)) #第四层,池化层 with tf.variable_scope("layer4_pool2"): pool2=tf.nn.max_pool(relu2,[1,2,2,1],[1,2,2,1],padding="SAME") #第四层的输出为7*7*64,然而第五层全连接层需要的输入格式为向量,所以这里需要将7*7*64拉伸为一个向量。pool2.get_shape。因为每层网络的输入输出都是一batch #矩阵所以这里的维度也包含batch中数据的个数。 pool_shape = pool2.get_shape().as_list() nodes = pool_shape[1]*pool_shape[2]*pool_shape[3] reshaped = tf.reshape(pool2,[pool_shape[0],nodes]) with tf.variable_scope("layer5_fc1"): fc1_weights = tf.get_variable('weight',[nodes,FC_SIZE],initializer=tf.truncated_normal_initializer(stddev=0.1)) fc1_biases = tf.get_variable("bias",[FC_SIZE],initializer=tf.constant_initializer(0.1)) #只有全连接层的权重需要加入正则化 if regularizer != None: tf.add_to_collection("losses",regularizer(fc1_weights)) fc1 = tf.nn.relu(tf.matmul(reshaped,fc1_weights)+fc1_biases) if train: #利用dropout减少过拟合 fc1 = tf.nn.dropout(fc1,0.5) #声明第六层-全连接层。输入为512的向量,输出为10的向量 with tf.variable_scope("layer6_fc2"): fc2_weights = tf.get_variable('weight',[FC_SIZE,OUTPUT_NODE],initializer=tf.truncated_normal_initializer(stddev=0.1)) fc2_biases = tf.get_variable('biases',[OUTPUT_NODE],initializer=tf.constant_initializer(0.1)) if regularizer != None: tf.add_to_collection('losses',regularizer(fc2_weights)) logit = tf.matmul(fc1,fc2_weights)+ fc2_biases return logit
#mnsit_train # -*- coding:utf-8 -*- import os import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data #加载mnsit_inference.py中定义的变量和函数 from integerad_mnist import mnsit_inference import numpy as np #配置神经网络的参数 BATCH_SIZE = 100 LR_BASE = 0.8 LR_DECAY = 0.99 REGULARAZTION_RATE = 0.0001 TRANING_STEPS = 30000 MOVING_AVERAGE_DECAY = 0.99 #模型保存的文件名和路径 MODEL_SAVE_PATH = "path/to/model/" MODEL_SAVE_NAME = "model.ckpt" INPUT_SHAPE = [BATCH_SIZE,mnsit_inference.IMAGE_SIZE,mnsit_inference.IMAGE_SIZE,mnsit_inference.NUM_CHANNELS] def train(mnsit): #定义输入和输出的placeholder x = tf.placeholder(tf.float32,shape=INPUT_SHAPE,name="x_input") y_ = tf.placeholder(tf.float32,shape=[None,mnsit_inference.OUTPUT_NODE],name="y_input") regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE) #直接使用mnsit_inference中定义的前向传播过程 y = mnsit_inference.inference(x,True,regularizer) global_step = tf.Variable(0,trainable=False) variable_average = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY,global_step) variable_average_op = variable_average.apply(tf.trainable_variables()) cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=tf.argmax(y_,1),logits=y) cross_entropy_mean = tf.reduce_mean(cross_entropy) loss = cross_entropy_mean + tf.add_n(tf.get_collection("losses")) learning_rate = tf.train.exponential_decay(LR_BASE,global_step,mnsit.train.num_examples/BATCH_SIZE,LR_DECAY) train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss,global_step=global_step) with tf.control_dependencies([train_step,variable_average_op]): train_op = tf.no_op("train") #初始化TF的持久化类 saver = tf.train.Saver() with tf.Session() as sess: tf.initialize_all_variables().run() for i in range(TRANING_STEPS): xs,ys = mnsit.train.next_batch(BATCH_SIZE) reshaped_xs = np.reshape(xs,INPUT_SHAPE) _,loss_value,step = sess.run([train_op,cross_entropy_mean,global_step],feed_dict={x:reshaped_xs,y_:ys}) #每1000轮保存一次模型 if i % 1000 == 0: print("After {0} training steps,loss on training batch is {1}".format(step,loss_value)) saver.save(sess,os.path.join(MODEL_SAVE_PATH,MODEL_SAVE_NAME),global_step=global_step) def main(argv = None): mnsit = input_data.read_data_sets("mnist_set",one_hot=True) train(mnsit) if __name__ == '__main__': tf.app.run()
3.2 Inception-V3 模型
LeNet-5模型中,卷积层是通过串联的方式连接在一起的,而Inception-v3中的inception结构与之完全不同,它是通过并联的方式结合在一起的。如下图所示;
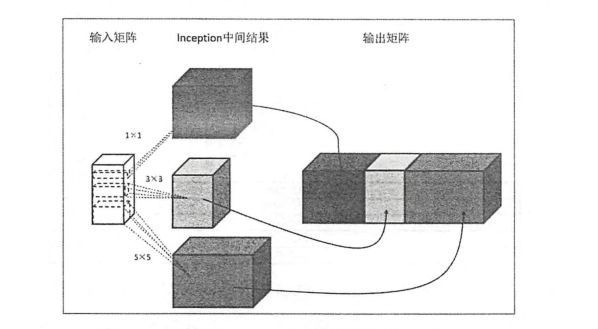
整体的inception-v3模型架构图
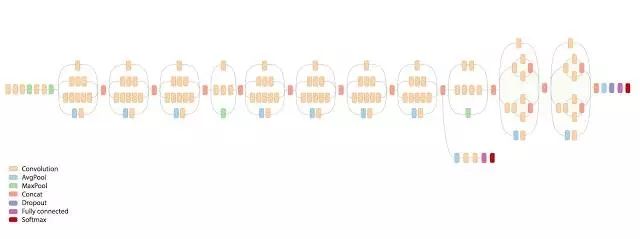
Inception-v3模型总共有46层,由11个inception模块组成。Inception-v3模型中有96个卷积层。如果还按照之前的代码,一个卷积5行代码,96个需要480行代码,代码可读性差,可以用TonserFlow=Slim来实现。一行即可实现一个conv层。
比较一下原始的tf和slim
import tensorflow as tf import numpy as np import tensorflow.contrib.slim as slim #通过tf.get_variable的方式创建过滤器的权重和偏置。 x = np.random.randn(4,5) filter_weight = tf.get_variable("weight",[5,5,3,16],initializer=tf.truncated_normal_initializer(stddev=0.1)) biases = tf.get_variable("biases",shape=[16],initializer=tf.constant_initializer(0.1)) conv=tf.nn.conv2d(x,filter_weight,strides=[1,1,1,1],padding="SAME") bias = tf.nn.bias_add(conv,biases) active_conv = tf.nn.relu(bias) #使用TensorFlow-Slim实现卷积层。slim.conv2d函数有三个必填的参数,第一个为输入节点的矩阵,第二个为当前卷积层过滤器的深度,第三个为过滤器的尺寸 #可选参数有步长,填充0,激活函数和变量的命名空间 net = slim.conv2d(x,16,[5,5])
代码实现一个inception模块。
import tensorflow as tf import numpy as np import tensorflow.contrib.slim as slim #slim.arg_scope函数用来设置默认的参数取值,第一个参数是函数名列表。 with slim.arg_scope([slim.conv2d,slim.max_pool2d,slim.avg_pool2d],stride = 1,padding = "SAME"): #.......此处省略了前面的网络结构, net = "上一层网络的输出" #为一个inception模块声明一个统一的变量命名空间 with tf.variable_scope("Mixed_7c"): #给inception的每一条分支声明一个变量命名空间 with tf.get_variable('branch_0'): branch_0 = slim.conv2d(net,320,[1,1],scope="Conv2d_0a-1X1") #第二条路径本身也是一个inception with tf.get_variable("branch_1"): branch_1 = slim.conv2d(net,384,[1,1],scope="Conv2d_0a-1X1") #tf.concat可以将多个矩阵进行拼接,第二个参数指定拼接的维度,这里的“3”代表深度。 branch_1 = tf.concat([slim.conv2d(branch_1,[1,3],scope="Conv2d_0b-1X3"),slim.conv2d(branch_1,[3,1],scope="Conv2d_0c-3X1")],3) with tf.get_variable("branch_2"): branch_2 = slim.conv2d(net,448,[1,1],scope="Conv2d_0a-1X1") branch_2 = slim.conv2d(branch_2,384,[3,3],scope="Conv2d_0b-3X3") branch_2 = tf.concat([slim.conv2d(branch_2,[1,3],scope="Conv2d_0c-1X3"),slim.conv2d(branch_2,[3,1],scope="Conv2d_0c-3X1")],3) #第四条inception路径 with tf.get_variable("branch_3"): branch_3 = slim.avg_pool2d(net,[3,3],scope="avg_pool-0a-3X3") #tf.concat可以将多个矩阵进行拼接,第二个参数指定拼接的维度,这里的“3”代表深度。 branch_3 = slim.conv2d(branch_3,192,[1,1],scope="Conv2d_0a-1X1") #当前inception模块的最后输出由上面的四个结果拼接得到 net_output = tf.concat([branch_0,branch_1,branch_2,branch_3],3)
5、卷积神经网络的迁移学习
5.1什么是迁移学习?
所谓的迁移学习,就是将一个问题上训练好的模型通过简单的调整使其适用于一个新的问题。
瓶颈层:
在最后一层全连接层之间的网络层称之为瓶颈层。
一般来说,在数据量足够的情况下,迁移学习的效果不如完全重新学习。
5.2 TensorFlow 实现迁移学习