入选AAAI 2020,全新视频语义分割和光流联合学习算法问世
隔离疫情不隔离学习,读论文也是很好的在家“充电”方式之一。
今日,第34届人工智能顶级会议AAAI 2020正式开幕(2月7日-2月12日在美国纽约举办)。AAAI(Association for the Advance of Artificial Intelligence——美国人工智能协会)是人工智能领域的主要学术组织之一,其年会每年都吸引了大量来自学术界和产业界的研究员、开发者投稿,参会。
商汤科技研究团队发表论文《Every Frame Counts: Joint Learning of Video Segmentation and Optical Flow》,创新性地将视频语义分割和光流方法融合,极大提升了视频分割的准确率和效率,该论文也被AAAI 2020录用。这种方法在自动驾驶、机器人、人体姿态识别、AR特效等诸多场景均有广泛应用前景。
那么这篇论文到底有哪些创新呢?下面一一解读。
▎打破现有方法局限
现有的视频语义分割方法,是利用前后帧的语义信息预测运动轨迹来分割,这种方法面临两大挑战:
准确率低。视频标注不如图像标注那样每一帧都会标注,一个视频片段往往只标注一帧,现有方法难以利用全部的数据,导致分割的准确率较低。
效率低。由于对前后帧之间进行信息交互往往为模型引入额外的模块,导致视频分割效率低。
商汤在研究中改进了这些不足,提出了一个光流和语义分割联合学习的框架。
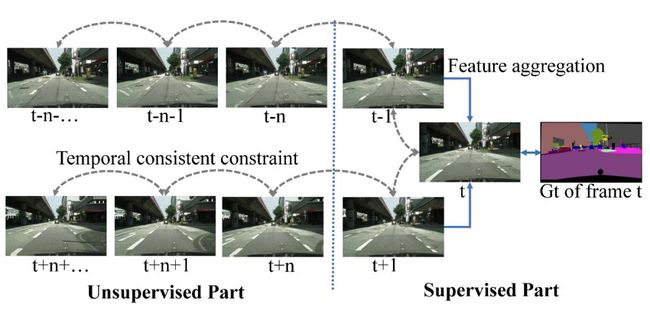
图1:现有方法和商汤算法比较
现有方法往往使用Feature aggregation将多帧信息融合到一起,然而这种方案仅仅利用了标注帧附近的少数帧(t, t-1, t+1)而且极大增加了网络的计算时间。
本文的方法使用Temporal consistent constraint(时序一致性约束)为多帧的特征之间添加隐式约束,在不增加耗时的前提下利用更多数据学习到更鲁棒的特征。
本文提出的联合学习框架(如图2),输入图片经过共享编码器后分为两个分支,上半部分是光流分支,下半部分是分割分支,以及时序一致性模块(黄色)和遮挡估计模块(灰色)。

图2:光流和语义分割联合学习框架
▎语义分割和光流相辅相成
本论文的语义分割和光流是相辅相成的,语义分割为光流和遮挡估计提供了更丰富的语义信息,而非遮挡的光流保证了语义分割的像素级别的时序一致性。
值得一提的是,通过光流施加的约束并没有显式的特征融合,而是隐式约束。在训练网络模型时需要分割和光流,但实际测试、应用的时候只需要分割。
这种方法可帮助利用数据集中的全部数据并学到更鲁棒的分割特征以提高分割准确率,并且不会在测试阶段增加额外的计算量。
但是,使用光流方法也会产生新的问题:遮挡。如下图,行人过马路时把后面的树挡住。那么如何更准确预估遮挡部分背景呢?

图3:遮挡和遮挡估计示意图
本文使用无监督的方式学习遮挡区域,通过反向光流推测出可能无法对齐的像素位置O(即遮挡区域),模型根据此学习得到O_{est};两帧的分割结果通过光流warp不一致的区域设为O_{seg},O_{seg}应包括遮挡区域和光流估计错误的区域,因此O_{error} = O_{seg}-O_{est}应为光流估计的重点区域。
在计算光流估计的损失函数时,作者不考虑遮挡区域(O_{est})的损失,而加大重点区域(O_{error})的权重。
▎多个数据集测试结果排名前列
这种方法的效果到底如何呢?
作者分别在Cityscapes、CamVid和KITTI数据集上进行了测试,均排名前列。在不使用额外数据集的情况下,均排名第一,具体如下表:

表1:Cityscapes数据集上的分割结果:本文算法排名第二,排名第一的方法VPLR生成了额外的数据

表2:CamVid数据集上的分割结果:本文算法排名第一
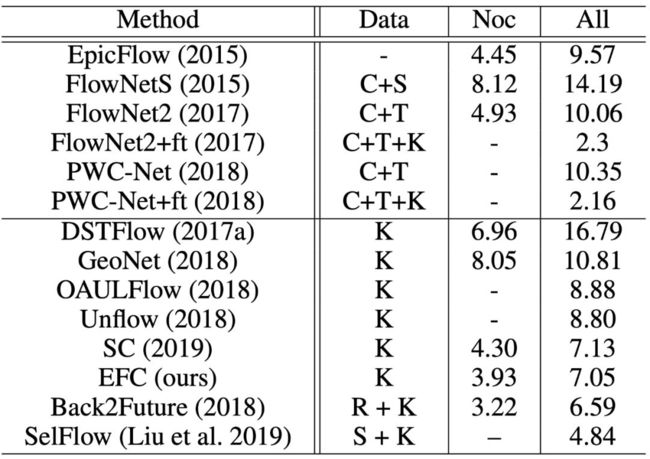
表3:KITTI数据集上的光流估计结果:本文算法排名第三,排名第一和第二均使用了额外数据集
再来看下可视化效果对比。

图4:CityScapes验证集图片可视化结果。从上至下分别为原图,本文算法分割结果,PSPNet分割结果和GT(标准结果)
从图4可以看出,本文算法对移动目标(汽车,自行车)和出现频次较少目标(横向卡车)分割效果较好。
以图中第二列的卡车识别为例,本文算法能更完整的识别卡车形状,且图中颜色较少(一种颜色代表一种物体),基本能准确识别卡车。而PSPNet分割方法识别的卡车颜色较多,即识别成多种物体,对卡车的识别不够准确。
而且,实验结果的视频中PSPNet分割方法对移动的卡车识别结果为多种颜色,即识别成了多种物体。相比之下,本文算法更稳定。
本文的光流估计效果也领先行业。图五是KITTI数据集上光流估计结果,从上至下分别为原图,本文算法估计结果,GeoNet估计结果和GT。可以看出本文算法对移动目标的边缘估计更为准确。

图5:KITTI 数据集光流估计可视化结果
GeoNet估计的实验结果,在左一列识别汽车位置偏离标准结果,在左二、三列识别汽车较模糊,与标准结果相差较大。相比之下,本文算法更接近标准结果。
论文作者:Mingyu Ding, Zhe Wang, Bolei Zhou, Jianping Shi, Zhiwu Lu, Ping Luo
论文地址:https://arxiv.org/pdf/1911.12739.pdf
![]()

“哪吒头”—玩转小潮流