HTTP请求的过程&HTTP/1.0和HTTP/1.1的区别&HTTP怎么处理长连接
此文转载纯属方便重看,详细请看原文:http://www.cnblogs.com/GumpYan/p/5821193.html
1.HTTP简介
web浏览器和服务器之类的交互过程必须遵守的协议.他是tcp/ip中的一个应用协议。用来协议数据交换过程和数据本身的格式.主要的有HTTP/1.0和HTTP1.1.
HTTP/1.0和HTTP/1.1都把TCP作为底层的传输协议。
HTTP客户首先发起建立与服务器TCP连接。一旦建立连接,浏览器进程和服务器进程就可以通过各自的套接字来访问TCP。如前所述,客户端套接字是客户进程和TCP连接之间的“门”,服务器端套接字是服务器进程和同一TCP连接之间的 “门”。客户往自己的套接字发送HTTP请求消息,也从自己的套接字接收HTTP响应消息。类似地,服务器从自己的套接字接收HTTP请求消息,也往自己 的套接字发送HTTP响应消息。客户或服务器一旦把某个消息送入各自的套接字,这个消息就完全落入TCP的控制之中。
TCP给HTTP提供一个可靠的数据传输服务;这意味着由客户发出的每个HTTP请求消息最终将无损地到达服务器,由服务器发出的每个HTTP响应消息最终也将无损地到达客户。我们可从中看到分层网络体系结构的一个明显优势——HTTP不必担心数据会丢失,也无需关心TCP如何从数据的丢失和错序中恢复出来的细节。这些是TCP和协议栈中更低协议层的任务。
TCP还使用一个拥塞控制机制。该机制迫使每个新的TCP连接一开始以相对缓慢的速率传输数据,然而只要网络不拥塞,每个连接可以迅速上升到相对较高的速率。这个慢速传输的初始阶段称为缓启动(slow start)。
需要注意的是,在向客户发送所请求文件的同时,服务器并没有存储关于该客户的任何状态信息。即便某个客户在几秒钟内再次请求同一个对象,服务器也不会响应说:自己刚刚给它发送了这个对象。相反,服务器重新发送这个对象,因为它已经彻底忘记早先做过什么。既然HTTP服务器不维护客户的状态信息,我们于是 说HTTP是一个无状态的协议(stateless protocol)。
2.一个完整的HTTP请求过程
HTTP事务=请求命令+响应结果

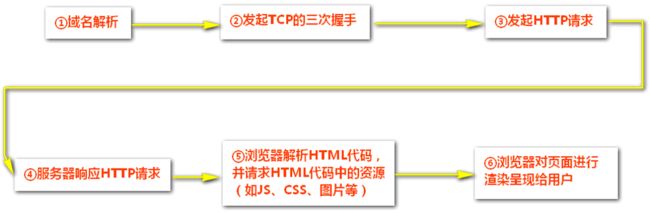
一次完整的请求过程:
(1)域名解析
(2)建立TCP连接,三次握手
(3)Web浏览器向Web服务端发送HTTP请求报文
(4)服务器响应HTTP请求
(5)浏览器解析HTML代码,并请求HTML代码中的资源(JS,CSS,图片)(这是自动向服务器请求下载的)
(6)浏览器对页面进行渲染呈现给客户
(7)断开TCP连接
如何解析对应的IP地址?域名解析过程(注意了先走本地再走DNS)

3.HTTP/1.0和HTTP/1.1的区别
HTTP 协议老的标准是HTTP/1.0,目前最通用的标准是HTTP/1.1。
在同一个tcp的连接中可以传送多个HTTP请求和响应.
多个请求和响应可以重叠,多个请求和响应可以同时进行.
更加多的请求头和响应头(比如HTTP1.0没有host的字段).
它们最大的区别:
在 HTTP/1.0 中,大多实现为每个请求/响应交换使用新的连接。HTTP 1.0规定浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接,服务器完成请求处理后立即断开TCP连接,服务器不跟踪每个客户也不记录过去的请求。
在 HTTP/1.1 中,一个连接可用于一次或多次请求/响应交换,尽管连接可能由于各种原因被关闭。HTTP 1.1支持持久连接,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟。一个包含有许多图像的网页文件的多个请求和应答可以在一个连接中传输,但每个单独的网页文件的请求和应答仍然需要使用各自的连接。HTTP 1.1还允许客户端不用等待上一次请求结果返回,就可以发出下一次请求,但服务器端必须按照接收到客户端请求的先后顺序依次回送响应结果,以保证客户端能够区分出每次请求的响应内容,这样也显著地减少了整个下载过程所需要的时间。
举例说明:
一个包含有许多图像的网页文件中并没有包含真正的图像数据内容,而只是指明了这些图像的URL地址,当WEB浏览器访问这个网页文件时,浏览器首先要发出针对该网页文件的请求,当浏览器解析WEB服务器返回的该网页文档中的HTML内容时,发现其中的图像标签后,浏览器将根据
标签中的src属性所指定的URL地址再次向服务器发出下载图像数据的请求。
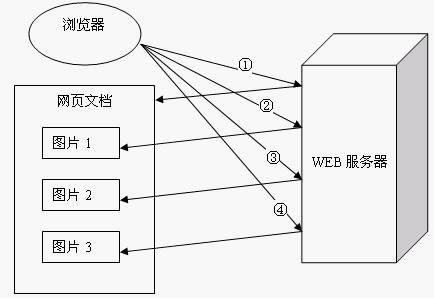
显然,访问一个包含有许多图像的网页文件的整个过程包含了多次请求和响应,每次请求和响应都需要建立一个单独的连接,每次连接只是传输一个文档和图像,上一次和下一次请求完全分离。即使图像文件都很小,但是客户端和服务器端每次建立和关闭连接却是一个相对比较费时的过程,并且会严重影响客户机和服务器的性能。当一个网页文件中包含Applet,JavaScript文件,CSS文件等内容时,也会出现类似上述的情况。
为了克服HTTP 1.0的这个缺陷,HTTP 1.1支持持久连接,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟。一个包含有许多图像的网页文件的多个请求和应答可以在一个连接中传输,但每个单独的网页文件的请求和应答仍然需要使用各自的连接。
HTTP 1.1还允许客户端不用等待上一次请求结果返回,就可以发出下一次请求,但服务器端必须按照接收到客户端请求的先后顺序依次回送响应结果,以保证客户端能够区分出每次请求的响应内容,这样也显著地减少了整个下载过程所需要的时间。
基于HTTP 1.1协议的客户机与服务器的信息交换过程,如下图所示
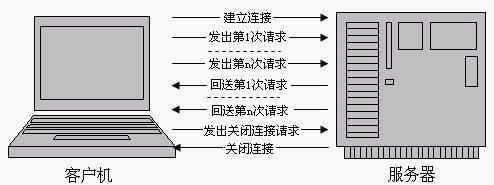
可见,HTTP 1.1在继承了HTTP 1.0优点的基础上,也克服了HTTP 1.0的性能问题。
还有哪些小的区别呢?
HTTP 1.1还通过增加更多的请求头和响应头来改进和扩充HTTP 1.0的功能。
例如,由于HTTP 1.0不支持Host请求头字段,WEB浏览器无法使用主机头名来明确表示要访问服务器上的哪个WEB站点,这样就无法使用WEB服务器在同一个IP地址和端口号上配置多个虚拟WEB站点。
在HTTP 1.1中增加Host请求头字段后,WEB浏览器可以使用主机头名来明确表示要访问服务器上的哪个WEB站点,这才实现了在一台WEB服务器上可以在同一个IP地址和端口号上使用不同的主机名来创建多个虚拟WEB站点。
HTTP 1.1的持续连接,也需要增加新的请求头来帮助实现。
例如,Connection请求头的值为Keep-Alive时,客户端通知服务器返回本次请求结果后保持连接;Connection请求头的值为close时,客户端通知服务器返回本次请求结果后关闭连接。
HTTP 1.1还提供了与身份认证、状态管理和Cache缓存等机制相关的请求头和响应头。
4.Http怎么处理长连接
基于http协议的长连接
在HTTP1.0和HTTP1.1协议中都有对长连接的支持。其中HTTP1.0需要在request中增加”Connection: keep-alive“ header才能够支持,而HTTP1.1默认支持.
http1.0请求与服务端的交互过程:
(1)客户端发出带有包含一个header:”Connection: keep-alive“的请求
(2)服务端接收到这个请求后,根据http1.0和”Connection: keep-alive“判断出这是一个长连接,就会在response的header中也增加”Connection: keep-alive“,同时不会关闭已建立的tcp连接.
(3)客户端收到服务端的response后,发现其中包含”Connection: keep-alive“,就认为是一个长连接,不关闭这个连接。并用该连接再发送request.转到(1)
http1.1请求与服务端的交互过程:
(1)客户端发出http1.1的请求
(2)服务端收到http1.1后就认为这是一个长连接,会在返回的response设置Connection: keep-alive,同时不会关闭已建立的连接.
(3)客户端收到服务端的response后,发现其中包含”Connection: keep-alive“,就认为是一个长连接,不关闭这个连接。并用该连接再发送request.转到(1)
基于http协议的长连接减少了请求,减少了建立连接的时间,但是每次交互都是由客户端发起的,客户端发送消息,服务端才能返回客户端消息。因为客户端也不知道服务端什么时候会把结果准备好,所以客户端的很多请求是多余的,仅是维持一个心跳,浪费了带宽。
栗子:下列哪些http方法对于服务端和用户端一定是安全的?(C)
A.GET
B.HEAD
C.TRACE
D.OPTIONS
E.POST
TRACE: 这个方法用于返回到达最后服务器的请求的报文,这个方法对服务器和客户端都没有什么危险。