AAAI 2020|SetRank: 一种针对推荐系统隐式反馈的贝叶斯协同排序算法

你和“懂AI”之间,只差了一篇论文
很多读者给芯君后台留言,说看多了相对简单的AI科普和AI方法论,想看点有深度、有厚度、有眼界……以及重口味的专业论文。
为此,在多位AI领域的专家学者的帮助下,我们解读翻译了一组顶会论文。每一篇论文翻译校对完成,芯君和编辑部的老师们都会一起笑到崩溃,当然有的论文我们看得抱头痛哭。
同学们现在看不看得懂没关系,但芯君敢保证,你终有一天会因此爱上一个AI的新世界。
读芯术读者论文交流群,请加小编微信号:zhizhizhuji。等你。
这是读芯术解读的第149篇论文
AAAI 2020
SetRank:一种针对推荐系统隐式反馈的贝叶斯协同排序算法
SetRank: A Setwise Bayesian Approach for Collaborative Ranking
from Implicit Feedback
中国科学技术大学、百度
原文
Chao Wang, Hengshu Zhu, Chen Zhu, Chuan Qin, Hui Xiong, SetRank: A Setwise Bayesian Approach for Collaborative Ranking from Implicit Feedback, In Proceedings of the 34th AAAI Conference on Artificial Intelligence (AAAI 2020), New York, USA
本文是中国科学技术大学和百度TIC联合发表于AAAI2020的工作,文章提出一种新颖的针对推荐系统隐式反馈的贝叶斯协同排序算法SetRank。相比传统方法,SetRank能够更好地贴合推荐系统中隐式反馈的特点,以提供更好的排序结果。具体地,SetRank旨在最大程度地提高setwise偏好结构的后验概率,本文提供了矩阵分解和神经网络两种SetRank的实现方法。理论分析和实验结果都表明我们的方法可以有效地提高隐式反馈的推荐效果。


1.引言
推荐系统已广泛部署在许多流行的在线服务中,以增强用户体验和业务收入。作为个性化推荐的一项代表性任务,协同排序旨在根据用户从历史反馈中学到的偏好为用户提供备选物品的排名。用户反馈可以分为两种主要类型,一是显式反馈,二是隐式反馈。显式反馈指的是拥有明确的评分标准的数值反馈,例如豆瓣电影的五星制评分。与显式评分不同,隐式反馈仅包含正样本和未观测样本,而不是已分级的用户偏好。常见的隐式反馈包括点击记录,购买记录,点赞记录等等。在日常生活中,大多数用户的反馈都是隐式的,而非显式的。这为构建推荐系统带来了新的研究挑战,因为隐式反馈中并没有明确的未观测样本,而只有未观测样本。因此,近年来,基于隐式反馈的协同排序任务越来越引起人们的关注。
传统的协同排序方法以pairwise和listwise方法为代表,目前已有很多的相关研究工作,也取得了很好的实践效果,但这些方法仍然存在一些关键性的挑战。图1展示了不同的协同排序方法的大体思路。pairwise方法通常以一个正反馈物品和一个未观测物品组成的物品对作为基础,对隐式反馈中的偏好结构进行建模,这种做法容易出现假设与实现上的独立性不一致问题。例如,目前使用最广泛的pairwise方法中的贝叶斯个性化排序(BPR)方法试图最大化正反馈和未观测反馈之间的成对比较概率。这种处理要求严格假设两个物品具有独立的成对偏好,以此作为构建损失函数的基础。但是,如图1所示,如果用户1存在的偏好对A>B和C>D,则由于隐式反馈是0/1数值的,因此用户1也必须存在偏好对A>D和C>B。换句话说,在实际的偏好对构建过程中,我们有![]() 。因此偏好对之间的独立性无法保障,从而影响了pairwise损失函数的优化结果。一些后续的pairwise研究选择通过考虑用户和物品的组信息来放松独立性假设。例如,GBPR引入了更丰富的用户组信息,而Cofiset则定义了用户对物品组的偏好。但是,独立性不一致的问题仍然存在 。
。因此偏好对之间的独立性无法保障,从而影响了pairwise损失函数的优化结果。一些后续的pairwise研究选择通过考虑用户和物品的组信息来放松独立性假设。例如,GBPR引入了更丰富的用户组信息,而Cofiset则定义了用户对物品组的偏好。但是,独立性不一致的问题仍然存在 。
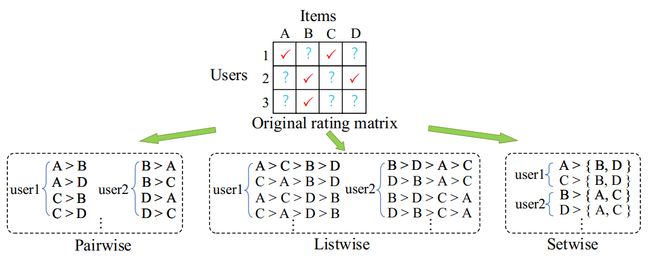
图1.不同协同排序方法对比
Listwise方法的做法是在物品列表上定义偏好大小的概率关系。对于listwise方法,关键的挑战是由于要用到整个列表的排列熟悉怒,如何有效地处理具有相同评级值的项目是很重要的,特别是因为隐式反馈中没有明确的分级评分,而是0/1评分,这时会有大量的物品评分相同,如何指定这些物品的排序顺序是一个难题。此外,listwise方法常通过计算交叉熵来计算观测和预测列表中排名靠前的P项物品之间的差异性,这将导致关于P的指数计算复杂度,这就是为什么许多listwise方法通常将P 设置为1的原因。
为了避免现有协同排序方法的局限性,在本文中,我们提出了一种新颖的setwise贝叶斯协同排序方法,我们称其为SetRank。SetRank可以更好地贴合推荐系统中隐式反馈的特征。例如,与成对方法相比,我们独立性假设更弱,就不会出现独立性不一致的问题。SetRank方法将将原始的评分记录转换为每个正样本与一组未观测样本之间的偏好比较,即每个用户相对于未观测到的物品集合,都更喜欢正反馈物品,如图1所示。此外,由于原始数据中不包含未观测到的物品之间的偏好比较,也不包含正样本物品之间的偏好比较,因此可以不对未观测物品集合或者正样本物品集合内部进行排序,这就放宽了listwise方式中的排列限制。因此,SetRank能够以更贴合实际场景的方式对隐式反馈的数据进行建模,同时避免了pairwise和listwise排序方法的弊端。在本文中,我们从理论估计和实验验证两方面验证了SetRank模型的效果。一方面,我们给出了SetRank方法的理论误差风险上确界,另一方面大量实验结果证明了SetRank能够超过目前最先进的一些协同排序方法。
2. 模型框架
SetRank方法建立在深度理解用户隐式反馈数据含义的基础上设计和实现,总体上可以分为两个主要的部分:(1)偏好结构建模:通过利用用户的历史评分记录来对用户的偏好结构进行建模,发掘用户的真实偏好和需求,从而学习并预测出用户对不同物品的评分值,这里的评分值仅用于物品排序来为用户推荐评分高的物品,不对应用户的真实评分数据(在隐式反馈中真实评分是0/1数据);(2)评分建模:这一部分指的是建立一个机器学习预测模型来得到用户的评分预测结果。需要注意的是,这两个部分并不是分开的,评分建模需要在偏好结构建模的指导下才能学习到用户的真实偏好属性,从而给出更精准的评分预测结果。
2.1问题形式化定义
本文用![]() 来表示用户的学习记录矩阵,其中N为用户数量,M为物品数量,若用户i与物品l有交互记录,则记
来表示用户的学习记录矩阵,其中N为用户数量,M为物品数量,若用户i与物品l有交互记录,则记![]() 为1,反之则记
为1,反之则记![]() 为0,故而评分矩阵是一个0-1矩阵。对每个用户i,评分为1的物品集合记为
为0,故而评分矩阵是一个0-1矩阵。对每个用户i,评分为1的物品集合记为![]() ,评分为0的物品集合记为
,评分为0的物品集合记为![]() 。最终推荐结果按照预测的评分大小给出,预测评分高的物品优先推荐,预测评分矩阵
。最终推荐结果按照预测的评分大小给出,预测评分高的物品优先推荐,预测评分矩阵![]() 。
。
2.2偏好结构建模
偏好结构建模的关键点是如何建模用户对不同物品的偏好倾向,本文提出一种新型偏好结构建模方法——setwise方法。考虑到每个用户的评分过程可以近似认为是互相独立不受其他用户影响的,我们首先假设每个用户的评分结果都是独立的。然后对每一个用户,可以认为其对正样本的偏好高于未观测样本的偏好。因此,我们可将用户的每个正样本和未观测样本集合做对比,认为用户喜欢正样本的概率要大于喜欢未观测样本集合的概率。然后我们就可以极大化这些对比的似然概率值来求解问题。相比于pairwise假设,setwise假设通过放宽独立性要求避免了独立性不一致的问题。
Setwise偏好结构的贝叶斯后验概率可如下给出:
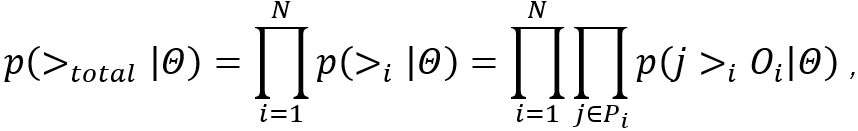
其中![]() 是所有用户的偏好结构,
是所有用户的偏好结构,![]() 是一个表示表示用户i的偏好结构的随机变量,
是一个表示表示用户i的偏好结构的随机变量,![]() 是在评分建模部分要学习的参数。
是在评分建模部分要学习的参数。![]() 这个概率就表示一个正样本j优于一些未观测样本组成的集合
这个概率就表示一个正样本j优于一些未观测样本组成的集合![]() 的偏好结构概率,注意到这个概率可以等价于认为是这个正样本在由这个正样本和所有未观测样本组成的列表中排第一的概率,而未观测样本之间或者正样本内部的顺序是不需要考虑的,所以不存在listwise方法相同评分物品排序的问题。
的偏好结构概率,注意到这个概率可以等价于认为是这个正样本在由这个正样本和所有未观测样本组成的列表中排第一的概率,而未观测样本之间或者正样本内部的顺序是不需要考虑的,所以不存在listwise方法相同评分物品排序的问题。
我们引入listwise方法中基于列表顺序的概率建模方法来计算概率![]() ,其公式如下:
,其公式如下:
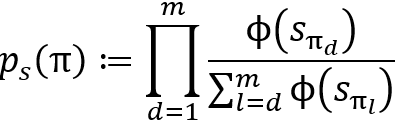 ,
,
其中π是一个物品排序,![]() 则是排在第l位的物品的对应评分。上式的一大问题在于如果要计算一个物品排名在前P位的概率就需要计算P!个排序概率。幸运的是,setwise方法仅关心正样本排在第1位时的排序概率,此时的概率计算公式可以简单地如下式给出:
则是排在第l位的物品的对应评分。上式的一大问题在于如果要计算一个物品排名在前P位的概率就需要计算P!个排序概率。幸运的是,setwise方法仅关心正样本排在第1位时的排序概率,此时的概率计算公式可以简单地如下式给出:
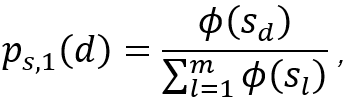
其中![]() 就表示物品d排第一的概率,
就表示物品d排第一的概率,![]() 是物品l的评分。
是物品l的评分。
由此可以得到setwise方法的完整概率建模形式:
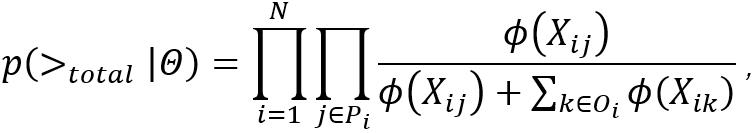
则通过极大化后验概率的方式,最终优化目标函数可以如下给出:
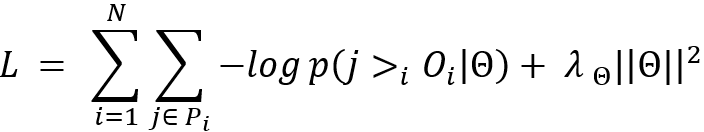
2.3 评分建模
在本文中我们提供两种高效的评分建模方法实现SetRank,即矩阵分解方法(MF-SetRank)和深度学习方法(Deep-SetRank)。注意SetRank并不局限于这里列举的两种评分建模方法,其他任意可行的评分建模方法都可以与我们的setwise偏好结构建模方法共同使用。
矩阵分解方法假定对用户的每个预测评分都可以视为受到用户需求隐向量和物品属性隐向量两方面的影响,每个评分都是由这两个隐向量的乘积得到,![]() 。也就是说,矩阵分解方法将高维稀疏的评分矩阵映射到两个处于低维的矩阵中来,分别记为U和V,预测的评分记录矩阵X是U转置和V的矩阵乘积。
。也就是说,矩阵分解方法将高维稀疏的评分矩阵映射到两个处于低维的矩阵中来,分别记为U和V,预测的评分记录矩阵X是U转置和V的矩阵乘积。
在矩阵分解评分建模方法下,最终SetRank的优化目标函数为:
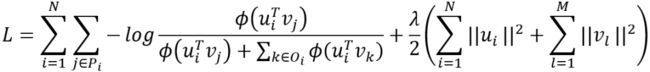
其中![]() 是sigmoid函数。
是sigmoid函数。
在实际计算过程中,没有必要对每个用户都计算所有的未观测样本,可以采用均匀负采样的方法随机选择![]() 个未观测样本进行计算,这可以大大提高计算效率。
个未观测样本进行计算,这可以大大提高计算效率。
可以采用随机梯度下降方法对目标函数进行求解,具体的梯度求导公式如下:
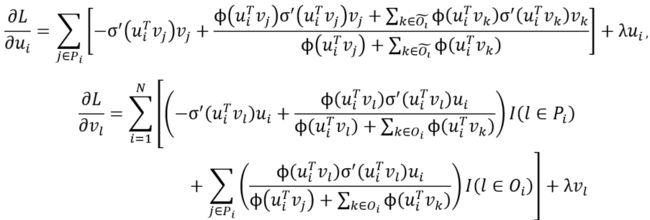
直接对每个用户和物品单独计算梯度会导致![]() 的计算复杂度,然而,上式的计算过程中存在大量可重复利用的计算项。算法1展示了在固定U时更新关于V的梯度的快速计算算法,反过来固定V时更新U的算法也可以类似得到。该算法可以让计算复杂度减少到
的计算复杂度,然而,上式的计算过程中存在大量可重复利用的计算项。算法1展示了在固定U时更新关于V的梯度的快速计算算法,反过来固定V时更新U的算法也可以类似得到。该算法可以让计算复杂度减少到![]() 级别。
级别。
算法1.当固定U时更新关于V的梯度的快速计算算法

鉴于深度学习方法已经在图像和语音识别等很多任务上表现出远超传统机器学习方法的精度,本文在矩阵分解方法之外也提供一种基于神经网络的深度矩阵分解方法。

图2.Deep-SetRank的评分建模过程
如图2所示,深度学习方法包含两个神经网络组件,分别是用户解析网络和物品解析网络。每个解析网络由n层全连接网络(Multi-layerPerceptionNetwork)组成,每一层网络都对上一层网络传输过来的数据进行加工并再传输到下一层中,第一层的输入就是用户或物品的评分向量。具体的,每一层网络有两个参数,分别是权重系数矩阵和偏置向量,以用户解析网络为例:
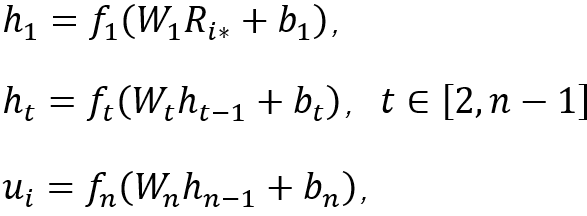
其中![]() 是第t层神经网络的激活函数,这里我们在最后一层采用tanh函数,在前面的网络层采用Sigmoid函数。
是第t层神经网络的激活函数,这里我们在最后一层采用tanh函数,在前面的网络层采用Sigmoid函数。
最终的评分由经过用户解析网络和物品解析网络得到的两个隐向量![]() 和
和![]() 的乘积得到。不同于矩阵分解方法,深度学习方法不再训练两个隐向量矩阵,而是训练神经网络的权重参数。
的乘积得到。不同于矩阵分解方法,深度学习方法不再训练两个隐向量矩阵,而是训练神经网络的权重参数。
2.4理论分析
在这一节里,本文将会给出SetRank方法的理论误差风险上确界。
考虑如下的优化问题:

其中X通常被低秩条件限制,例如在矩阵分解方法中,有![]() ,其中的范数是Frobenius范数。假设存在
,其中的范数是Frobenius范数。假设存在![]() ,
,![]() 是由概率
是由概率![]() 生成的,那么误差风险就可以定义为真实概率和预测概率之间的交叉熵:
生成的,那么误差风险就可以定义为真实概率和预测概率之间的交叉熵:
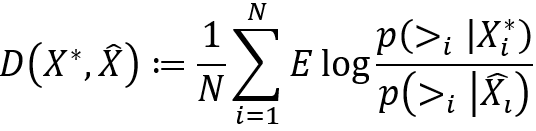
目前,在矩阵分解评分建模情况下,最优的listwise方法得到的误差风险上确界为![]() ,而可以证明,SetRank方法的理论误差风险上确界为
,而可以证明,SetRank方法的理论误差风险上确界为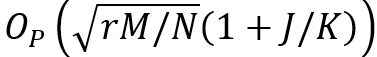 。注意到由于在现实应用场景中,通常一个用户的正样本物品数量要远远小于未观测样本的数量,因此我们有
。注意到由于在现实应用场景中,通常一个用户的正样本物品数量要远远小于未观测样本的数量,因此我们有![]() 。这使得SetRank方法的理论误差风险上确界看起来非常好。观察这个上确界我们可以发现,当用户数量越多的时候模型的误差风险就越小,这是因为更多的用户提供了更多的信息量,而当物品数量变多的时候,模型的误差风险就会增大,这是因为更多的备选物品带来了更多的不确定性。这一结果较为符合我们通常的认知。
。这使得SetRank方法的理论误差风险上确界看起来非常好。观察这个上确界我们可以发现,当用户数量越多的时候模型的误差风险就越小,这是因为更多的用户提供了更多的信息量,而当物品数量变多的时候,模型的误差风险就会增大,这是因为更多的备选物品带来了更多的不确定性。这一结果较为符合我们通常的认知。
3. 实验
· 实验数据集:为了将SetRank方法与其他协同排序方法进行对比,我们采用了4个不同的公开数据集进行验证,分别是MovieLens,Kindle,Yahoo和CiteULike。其中MovieLens是常用的电影推荐数据集。Kindle包含了从AmazonKindle商店收集的产品评分。Yahoo包含Yahoo!歌曲的评分数据。CiteULike由用户在CiteULike网站上收藏的文章数据组成。我们采取了两个步骤的数据预处理。首先,MovieLens,Kindle和Yahoo的原始数据采用5星级评分的形式,我们将它们转换为隐式数据,每个物品的评分都被标记为1或者0,取决于原始评分是否大于3。其次,为了确保我们有足够的正反馈来更好地评估推荐算法,我们分别剔除MovieLens,Kindle,Yahoo和CiteULike中少于60、20、10、10个正样本物品的用户。经过数据过滤后,MovieLens中总共有3,937个用户和3,533个物品,有923,473个评分记录;Kindle中总共有4,379个用户和3,774个物品,有102,545个评分记录。Yahoo中总共有4,664个用户,921中个物品,有82,384个评分记录。CiteULik中有4,123个用户和7,849个物品,有135,365个评分记录。
· 实验设置:在本实验中,我们采用三种不同的推荐系统常见评价指标,分别是精准率P@P,召回率R@P和平均准确率MAP@P。P@P计算的是推荐的top-P个物品中预测准的物品与P的比例,R@P计算的是推荐的top-P 个物品中预测准的物品与所有该用户在测试集中的正样本物品数量的比率,MAP@P则是加入了排名信息的来计算准确度。我们选取50%的数据作为训练集,并且重复5次随机选取数据集,最终给出的结果是这5次实验的平均值。
· 对比方法:在本实验中,我们将MF-SetRank和Deep-SetRank与许多先进的协同排序方法进行对比。由于MF-SetRank和Deep-SetRank分别基于矩阵分解和神经网络实现,在选取对比方法时,我们也分别对比基于矩阵分解和神经网络的pointwise(WMF,DeepMF,Multi-VAE),pairwise(BPR,Deep-BPR)和listwise(SQL-Rank,Deep-SQL)协同排序方法。
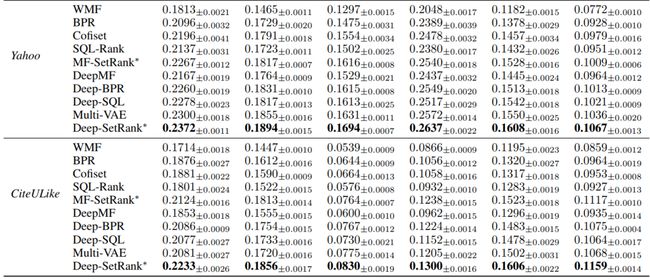
· 推荐效果对比实验:表1给出了我们方法与对比方法在4个公开数据集上的表现。从表1中,我们可以观察到,MF-SetRank超过了其他基于矩阵分解的推荐模型,而Deep-SetRank则超过了其他基于神经网络的推荐模型。这证明了SetRank方法的有效性,SetRank方法相比于pairwise和listwise方法其假设限制条件更弱,能够更好地拟合隐式反馈数据的真实特性。此外,可以看到基于神经网络的方法效果基本上都要优于矩阵分解的方法,这说明了神经网络确实具有更强的数据拟合能力。
表1.推荐效果对比表

· 参数敏感性实验:如前文所述,在SetRank中无需将所有未观测物品都用于每个用户的梯度计算。我们可以在每轮迭代中为每个用户随机抽取![]() 个未观测物品作为负样本。由于正样本的数量通常远小于总物品数量,因此对于每个用户而言,在不同迭代轮次里很少会碰到采样得到的重复未观测物品。在本小节中,我们将所有其他参数固定为相同设置,并评估采样倍率
个未观测物品作为负样本。由于正样本的数量通常远小于总物品数量,因此对于每个用户而言,在不同迭代轮次里很少会碰到采样得到的重复未观测物品。在本小节中,我们将所有其他参数固定为相同设置,并评估采样倍率![]() 对最终推荐结果的影响,结果如图3所示。P @ 5的结果显示,当τ=3 时,模型的性能已经足够好。即使我们进一步扩大τ的值,效果也不会有显著增加。
对最终推荐结果的影响,结果如图3所示。P @ 5的结果显示,当τ=3 时,模型的性能已经足够好。即使我们进一步扩大τ的值,效果也不会有显著增加。
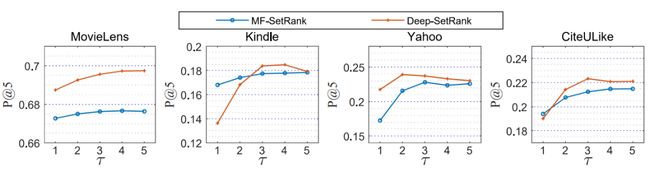
图3.不同的采样倍率τ对结果造成的影响对比图
另一个重要的参数是隐向量维度r。我们将评分矩阵分解为维度为r的隐空间中用户和物品向量的乘积。因此,隐空间的维度r对推荐结果也有很大影响。如果维度r太小,则该模型不能很好地拟合真实世界的数据,而如果r太大,则可能会导致过拟合的问题。我们固定其他所有其他参数不变,改变r来训练我们的模型,图4展示了对比结果。我们可以观察到r= 50 时SetRank的性能表现结果不佳。当r的值较大时,MF-SetRank的性能往往会更好。因此,我们建议采用较大的r值以在MF-SetRank中获得最佳性能。相比之下,对于Deep-SetRank,r=100似乎模型效果已经足够好了。这可能是因为神经网络本身就有许多要学习的参数,因此不需要再像矩阵分解模型那样增加隐空间的维度来获得更好的拟合结果。
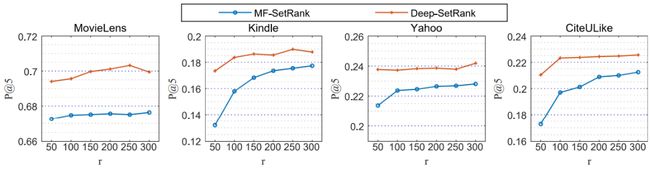
图4.不同的隐向量维度r对结果造成的影响对比图
4. 总结
在本文中,我们提出了一种针对推荐系统中隐式反馈数据的贝叶斯协同排序方法,即SetRank。SetRank能够很好地贴合推荐系统中隐式反馈的特性,达到更好的推荐效果。具体地说,我们首先设计了一种新颖的setwise偏好结构。然后,我们通过极大化setwise偏好结构的后验概率来完成贝叶斯模型推断。为了实现SetRank,我们提供了两种不同的评分建模方式,分别是MF-SetRank和Deep-SetRank。此外,我们还提供了SetRank的理论分析,从理论上证明了误差风险上确界可以与![]() 成正比,其中M是物品数量,N是用户数量。最后,我们在四个真实的推荐数据集上进行了大量的实验,实验结果证明了SetRank方法的有效性。
成正比,其中M是物品数量,N是用户数量。最后,我们在四个真实的推荐数据集上进行了大量的实验,实验结果证明了SetRank方法的有效性。

推荐阅读专题




留言点赞发个朋友圈
我们一起分享AI学习与发展的干货
如转载,请后台留言,遵守转载规范
推荐文章阅读
ACL2018论文集50篇解读
EMNLP2017论文集28篇论文解读
2018年AI三大顶会中国学术成果全链接
ACL2017论文集:34篇解读干货全在这里
10篇AAAI2017经典论文回顾
长按识别二维码可添加关注
读芯君爱你