IntelliJ Idea开发spark程序及运行
版本:spark-1.6.0,IntelliJ Idea15
1.创建一个SBT项目
参考步骤:http://blog.csdn.net/jameshadoop/article/details/52299250
2.编写简单代码
package com.james.scala
/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
//默认HDFS,本地读取需要加:file://
val logFile = "file:///usr/local/spark/README.md" // Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}3.打包
3.1利用idea打包:
步骤参考:http://blog.csdn.net/jameshadoop/article/details/52305228
3.2 sbt打包
项目的根目录下执行:
sbt compile
sbt package4.运行
4.1 windows本地运行:
在Run/Debug Configurations的VM options添加参数:
-Dspark.master=local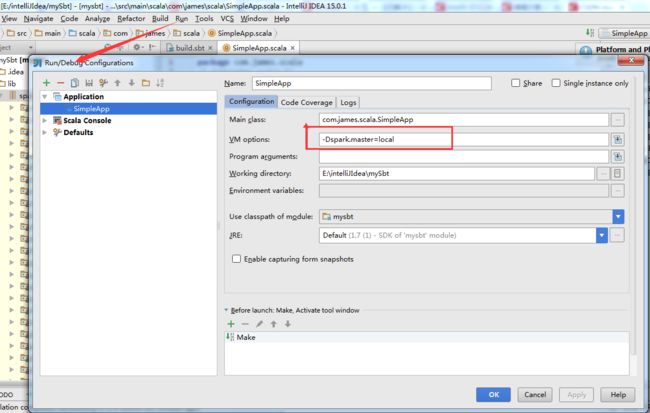
4.2 或提交spark集群运行
bin/spark-submit --master spark://c1:7077 --class com.james.scala.SimpleApp --executor-memory 2g /usr/local/app/mySbt.jar 1000附录:
spark-submit各项参数详解:
Options:
–master MASTER_URL spark://host:port, mesos://host:port, yarn, or local.
–deploy-mode DEPLOY_MODE driver运行之处,client运行在本机,cluster运行在集群
–class CLASS_NAME 应用程序包的要运行的class
–name NAME 应用程序名称
–jars JARS 用逗号隔开的driver本地jar包列表以及executor类路径
–py-files PY_FILES 用逗号隔开的放置在Python应用程序PYTHONPATH上的.zip, .egg, .py文件列表
–files FILES 用逗号隔开的要放置在每个executor工作目录的文件列表
–properties-file FILE 设置应用程序属性的文件放置位置,默认是conf/spark-defaults.conf
–driver-memory MEM driver内存大小,默认512M
–driver-java-options driver的java选项
–driver-library-path driver的库路径Extra library path entries to pass to the driver
–driver-class-path driver的类路径,用–jars 添加的jar包会自动包含在类路径里
–executor-memory MEM executor内存大小,默认1G
Spark standalone with cluster deploy mode only:
–driver-cores NUM driver使用内核数,默认为1
–supervise 如果设置了该参数,driver失败是会重启
Spark standalone and Mesos only:
–total-executor-cores NUM executor使用的总核数
Master URL 含义:
local 使用1个worker线程在本地运行Spark应用程序
local[K] 使用K个worker线程在本地运行Spark应用程序
local
使用所有剩余worker线程在本地运行Spark应用程序
spark://HOST:PORT 连接到Spark Standalone集群,以便在该集群上运行Spark应用程序
mesos://HOST:PORT 连接到Mesos集群,以便在该集群上运行Spark应用程序
yarn-client 以client方式连接到YARN集群,集群的定位由环境变量HADOOP_CONF_DIR定义,该方式driver在client运行。
yarn-cluster 以cluster方式连接到YARN集群,集群的定位由环境变量HADOOP_CONF_DIR定义,该方式driver也在集群中运行。