原来可以这样中文转码
大家做爬虫时,是不是也遇到过url是中文,然后在显示时转码了的情况,一长串字符,根本就不知道是什么,要验证的时候很不方便,这里分享一下我的处理方法。
一、尝试
一长串字符,首先想到用在线unicode转中文,结果还是不知道是什么.
原内容:
%5B9500%5D%5B552e%5D%5B6307%5D%5B6807%5D%5B5b8c%5D%5B6210%5D%5B7387%5D111
%5B8d39%5D%5B7528%5D%5B989d%5D%5B5ea6%5D%5B67e5%5D%5B8be2%5D
转后:
[9500][552e][6307][6807][5b8c][6210][7387]111
[8d39][7528][989d][5ea6][67e5][8be2]
心想这是什么东西?
难道就这样失败了?
仔细看看内容,四个字,四个字的,是不是有点像unicode?可是中括号是什么鬼?
试着拿一个数试试,\u9500.

![]()
果然,不是巧合,真的就是unicode, 可是这么多括号,手动解决是不可能的。
二、怎么才能去除括号并且换上\u呢?
当然首选是pyhton, 上代码:
# coding=utf-8
from urllib import parse
import re
def _change(matched):
if matched.group(0) == "[":
return '\\u'
else:
return ''
def url_de(x):
'''对URL进行解码'''
replaceStr = re.sub(
r'([\[|\]])', _change, parse.unquote(x))
return replaceStr
x = '''
%5B9500%5D%5B552e%5D%5B6307%5D%5B6807%5D%5B5b8c%5D%5B6210%5D%5B7387%5D111
%5B8d39%5D%5B7528%5D%5B989d%5D%5B5ea6%5D%5B67e5%5D%5B8be2%5D
'''
print(url_de(x))
首先,我们引入要用的包,这里主要是两个包,parse用来做第一遍转码,转成带括号的形式。然后使用re.sub对括号进行替换和消除。
输出:
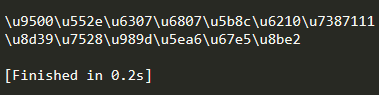
其实应该有方法再转一次输出中文的,可是一时半会没找到方法。只能用笨办法了,复制输出的内容到在线unicode转中文。

成功了,原来是这样。
三、 转机
就在我打算先这么样的时候,一个朋友给出了一个方法。
谢谢 @程序员喜欢猫 的帮助,使用json 可以顺利的解析出中文,不用反复使用 在线unicode转中文 。
新的代码也放到下面:
# coding=utf-8
from urllib import parse
import re
import json
def _change(matched):
if matched.group(0) == "[":
return '\\u'
else:
return ''
# 原来方法加上json.loads
def url_de(x):
'''对URL进行解码'''
replaceStr = re.sub(
r'([\[|\]])', _change, parse.unquote(x))
return json.loads(f'"{replaceStr}"')
# @程序员喜欢猫 提供的方法
def func(string):
string = parse.unquote(string)
string = string.replace('[', '\\u').replace(']', '')
return json.loads(f'"{string}"')
x = 'http://www1.site.com:8888/WebReport/ReportServer?formlet=/test/[7efc][5408][5206][6790]/zonghexinxi_erji_yiyao_tuiguangbu--%5B9500%5D%5B552e%5D%5B6307%5D%5B6807%5D%5B5b8c%5D%5B6210%5D%5B7387%5D111.frm'
print('方法一:')
print(url_de(x))
print('方法二:')
print(func(x))
四、结果:

很明显中文已经解析出来了,不用再去 在线unicode转中文 了, 完美,再次感谢 @程序员喜欢猫
五、再进一步
果然是方法总比问题多,经过 @程序员喜欢猫 的提醒,我想应该方法不止这些,又上网搜索了下,果然,也有小伙伴遇到这个问题,具体可见 https://www.zhihu.com/question/26921730
于是现改进方法:
def url_de(x):
'''对URL进行解码'''
replaceStr = re.sub(
r'([\[|\]])', _change, parse.unquote(x))
return replaceStr.encode('latin-1').decode('unicode_escape')
六、效果:
![]()
注意:
这里需要注意的是, 如mailto1587 说的:
先检查text是什么类型如果type(text) is bytes,那么text.decode('unicode_escape')
如果type(text) is str,那么text.encode('latin-1').decode('unicode_escape')
用这种方法可以不用引入 json , 理解起来更自然点。
七、后记:
这次的问题其实还是比较简单的,但是我们在做爬虫的过程中,这种问题层出不穷,怎么以简便快捷的方式处理问题就很重要了,但是在处理好问题后,我们还可以进一步研究,怎么才能做的更好,进步就再这一点点。欢迎大家关注我的公众号 Python与跨境电商 一起讨论。