2019年, VQA论文汇总
目录
- CVPR2019:XNMs
- ICCV2019:Q+I+A(数据集)
- NeurIPS2019:SCR
- CVPR2019:Modified QANet
- CVPR2019:GQA(数据集)
- CVPR2019:Cycle-Consistency(数据集)
- ICCV2019:MLIN
- CVPR2019:It`s not about the Journey
- CVPR2019:Transfer Learning via Unsupervised Task Discovery
- ICCV2019:LCGN
CVPR2019:XNMs
- 题目
Explainable and Explicit Visual Reasoning over Scene Graphs
下载链接
南洋理工大学张含望老师小组的工作. - 动机
在NMN (神经模块网络) 出现之前, 针对VQA任务提出的方法都是黑箱的, 是连接主义"流派"的, 神经网络会直接基于数据集学到inductive bias, 使得模型的结果缺乏可解释性. NMN在连接主义和符号主义之间"架设"了一座桥梁, 使后来的VQA方法具有了可解释性. 但是使用NMN需要仔细设计每个模块的内部细节, 不易拓展. - 贡献
- 在CLEVR和CLEVR-CoGent数据集上达到100%准确率.
- 和现有NMN方法相比, 具有的参数量很少.
- 泛化能力强.
- 具有高可解释性和高显性.
-
方法
本文方法的整体框架如图所示:

首先, 对于给定的image进行scene grpah parsing (场景图解析). 然后, 对于给定的question进行program generation. 最后, 在场景图上进行reasoning即可. 整个方法的流程看起来很简单, 而且在实验部分可以看出, 本文方法十分work, 可以在CLEVR数据集上达到100%的准确率.
本文在场景图上预设了四种不同的meta-types, 分别为: ① AttendNode (代表"实体"). ② AttendEdge (代表"实体"之间的"关系"). ③ Transfer (根据"关系"对"实体"进行转化). ④ Logic (与, 或, 非等逻辑操作). 以上四种操作在文中都有详细的介绍, 这里不多做解释.
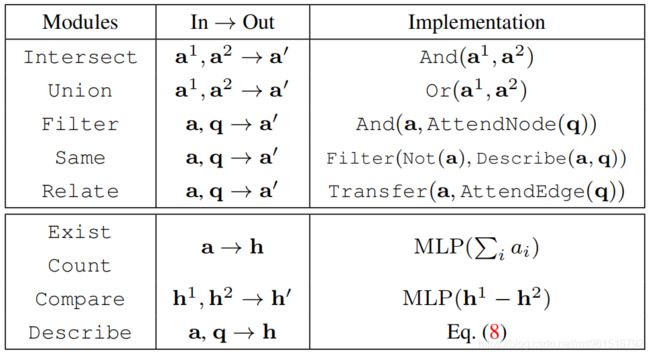

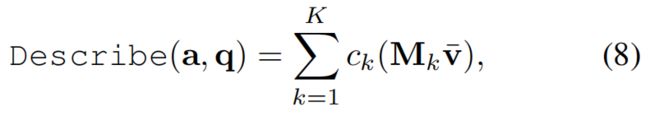
Transfer操作如下图所示:
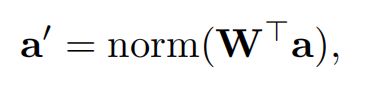
-
实验
在CLEVR数据集上的实验结果. XNM-Det表示所有的物体都是使用某种检测模型得到的, XNM-GT表示所有的物体都是直接使用的Ground-Truth. Program的也有两种选项, supervised表示使用训练得到的program generator, GT表示直接使用Ground-Truth. 可以看出, 只要在物体检测阶段足够给力, 无论使用哪种program generator, 都可以达到很高的准确率.

从下图可以看出, 本文方法的收敛速度很快

下图是在CLEVR-CoGenT数据集上的结果:

ICCV2019:Q+I+A(数据集)
- 题目
Why Does a Visual Question Have Different Answers?
下载链接 - 动机
在VQA任务中,一直存在一个问题:不同的人会对同一个问题做出不同的答案。本文尝试去分析为什么会造成这个现象。 - 贡献
- 提高数据集制作的质量。
- 帮助大家分辨模型产生不同答案的原因。
- 当得到多个答案时,提供一种自动整合多个答案的策略。
-
方法
首先,作者提出了9种可能导致不同答案的原因,如下图所示,分别是:LOW QUALITY IMAGE, DIFFICULT, SYNONYMS, ANSWER NOT PRESENT / GUESSWORK, AMBIGUOUS, GRANULAR, INVALID, SUBJECTIVE, SPAM。
对于上述的9种原因,又可以归结为3类,分别为Q(issues with the Question)、I(issues with the Image)、A(issues with the Answer)。作者将Q和I临时归为一类,以表格的形式对9种原因进行了分类和解释。

作者在VizWiz和VQA_2.0两个数据集上进行了人工标注。由于不同人对此问题的理解也不同,故使用3个人进行标注。对于下面的图片,左侧是VizWiz数据集,右侧是VQA_2.0数据。最内环的圆圈代表仅有一人标注的数据集结果,中间的圆圈代表需要两个人同意才可以这样标注,最外环表示三人都同意时才可以这样标注。可以看出,造成不同答案的主要原因是QI&A。

接下来,作者又按照9个类别进行了统计,得到如下图的结果。可以看出,最主要的三个原因是:AMB, SYN, GRN.
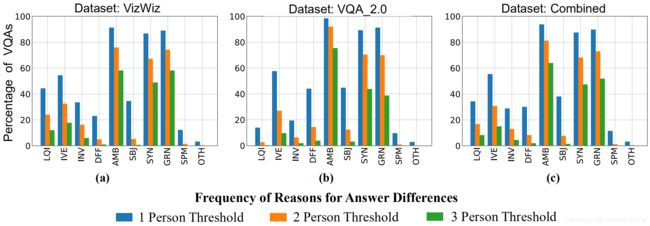
接下来,作者又在两个数据集上统计了每种情况“单独发生”or“和其他情况同时发生”的概率,如下图所示。左侧是VizWiz数据集,右侧是VQA_2.0数据集。

接下来,作者提出了用来预测是哪种情况发生的模型,如下图所示。该模型共预测10个类别,除了上述的9个类别,还有个others类,用来表示上述9类没涵盖到的情况。
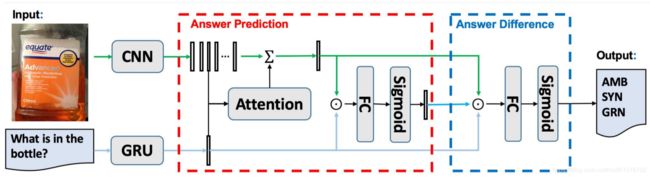
-
实验
本文的实验结果如下图所示。其中,Random表示随机猜测;QI-Relevance表示预测Q和I之间的相关性,如果预测结果是“相关”,则将LQI、IVE和AMB置为0,其他的置为1;I表示只有I存在问题;Unanswerable表示预测这个问题是否不可回答,若不是,则将LQI、IVE和AMB都置为0,其他的置为1;Q表示只有Q存在问题;Q+I表示Q和I都存在问题;Q+I+A表示Q、I和A都存在问题;Q+I+A_FT表示模型的最后一层使用Fc代替且进行fineTune的结果;Q+I+A_GT表示使用GroundTruth代替Answer Prediction得到的结果。

可以看出,本文模型对AMB、SYN和GRN原因预测的准确率还是挺高的,且这9类原因基本涵盖了所有原因。
NeurIPS2019:SCR
- 题目
Self-Critical Reasoning for Robust Visual Question Answering
下载链接 - 动机
训练数据和测试数据的QA distribution不同,导致预测的结果不准确。

- 贡献
本文提出了Self-Critical Reasoning,可以提高与正确answer相关的objects的sensitivity,同时降低模型预测出错误answer的概率(通过降低相关objects的sensitivity实现)。 - 方法
本文的整体框架如下图所示:
接下来,对本文的框架图进行解释。从图中我们可以看出,总共分为三部分:UpDn VQA system(左上部分)、Recognizing and Strengthening Influential Objects(左下部分)、Criticizing Incorrect Dominant Answers(右侧部分),下面对这三部分一一介绍。
第一部分 - UpDn VQA system。大体流程和传统的UpDn方法一样,首先,对image提取visual feature;然后,对question提取question feature;最后,将两类feature输入answer predictor得到answer。在以上基础上,本文添加了一个Constructor,用于生成proposal influential objects。作者提到,本文生成的proposal influential objects可能不准确,且含有较多noisy,但是假定其至少包含the most relevant object。文中共提到了3种Constructor,分别是:Construction from Visual Explanations、Construction from Textual Explanations和Construction from Questions and Answers。前两种需要数据集提供特定的标签,最后一种适用于常见的VQA数据。
第二部分 - Recognizing and Strengthening Influential Objects。这部分通过公式(3)实现,即:通过在损失函数中添加损失项 L i n f l L_{infl} Linfl最小化非influential objects的sensitivity。下面的公式中, a a a表示answer, v i v_i vi表示第 i i i个object的features, S ( a , v i ) S(a,v_i) S(a,vi)表示answer a a a对第 i i i个object的sensitivity, S V ( a , v i , v j ) SV(a,v_i,v_j) SV(a,vi,vj)表示第 j j j个object比第 i i i个object高出的sensitivity。

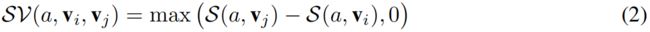
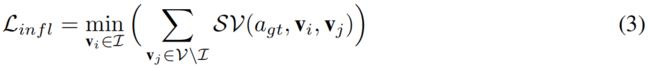
第三部分 - Criticizing Incorrect Dominant Answers。这部分通过公式(5)实现,即:通过在损失函数中添加损失项 L c r i t L_{crit} Lcrit最小化incorrect answers对于the most influential object的sensitivity。公式中, v ∗ v^* v∗表示the most influential object。
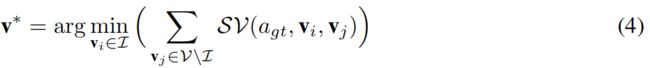

w ( a ) = c o s i n e _ d i s t ( G l o v e ( a g t ) , G l o v e ( a ) ) w(a)=cosine\_dist(Glove(a_{gt}),Glove(a)) w(a)=cosine_dist(Glove(agt),Glove(a))
综上,本文方法在训练时的损失函数为:
L = L v q a + L i n f l + λ L c r i t L=L_{vqa}+L_{infl}+\lambda L_{crit} L=Lvqa+Linfl+λLcrit - 实验
实验结果
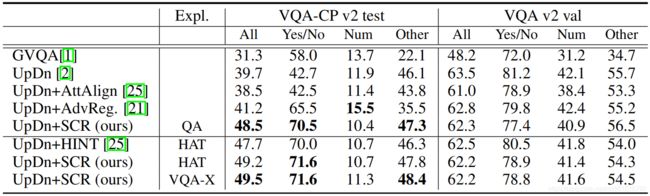
消融实验
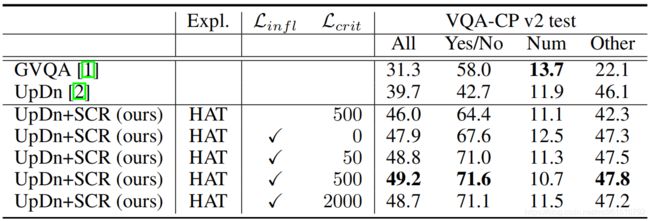
结果展示
CVPR2019:Modified QANet
- 题目
Visual Question Answering as Reading Comprehension
下载链接 - 动机
现有的VQA方法致力于将视觉信息和文本信息进行跨模态融合,而跨模态交互是很困难的,本文提出了一个做VQA的新思路,将VQA任务转化为机器阅读理解任务。
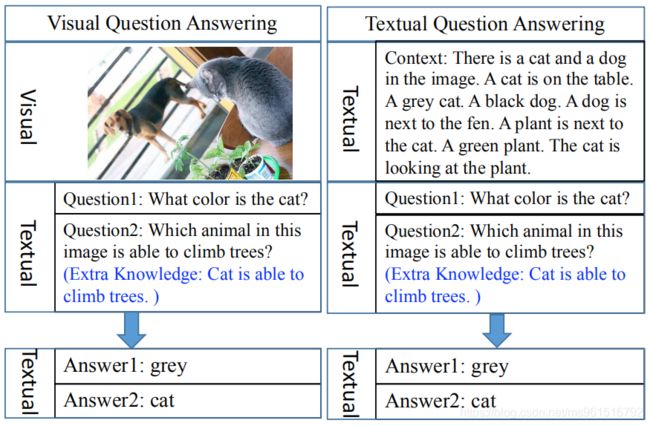
- 贡献
- 提出一个解决VQA问题的新思路,将VQA任务转化为机器阅读理解任务。
- 对于open-end VQA(没有answer候选项)和multiple-choice VQA(有answer候选项)任务,提出两种模型。
- 大多数的VQA方法对于knowledge based VQA的表现不是很好,但是本文方法可以很容易的拓展至knowledge based VQA(因为模态相同)。
- 方法
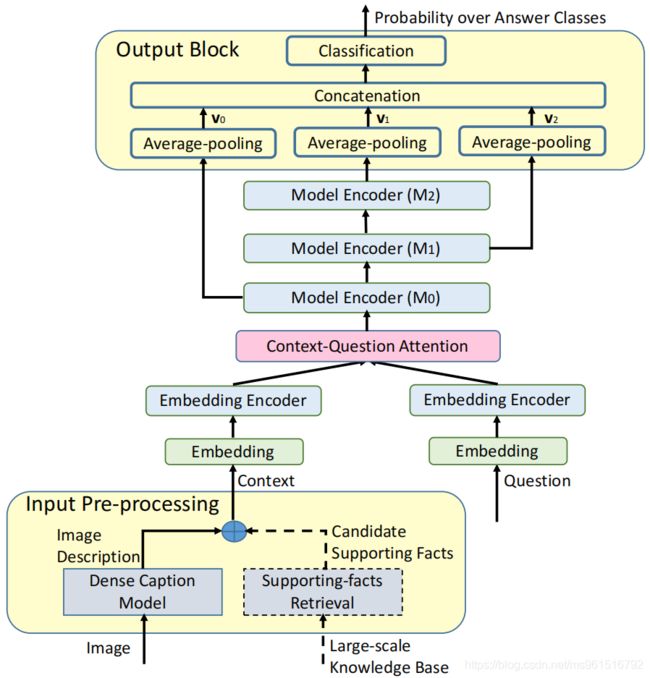
本文方法主要基于TQA(机器阅读理解)领域的QANet模型构建,下图是QANet中使用的encoder结构。QANet中主要包括5个组成部分,分别是:embedding block、embedding encoder、context-query attention block、model encoder和output layer。

下图是本文对于open-ended VQA问题提出的模型。
下图是本文对于multiple-choice VQA问题提出的模型。

- 实验
下图是在FVQA数据集上的实验结果,使用微调的QANet达到了sota。

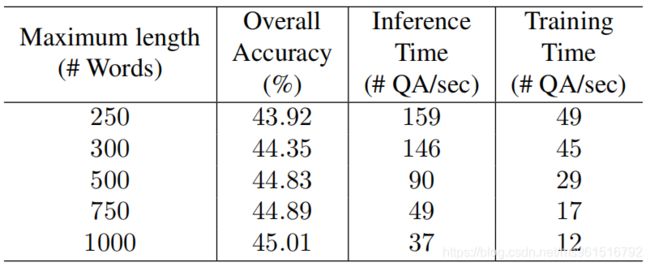
下图展示了限制图片生成的captions长度,对准确率带来的影响。可以看出,captions越长,则准确率越高,但是计算负担会变大。
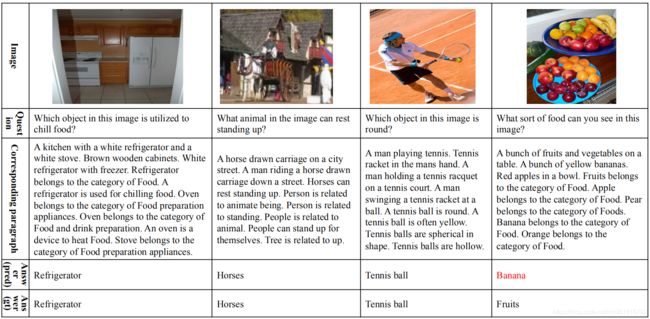
下图是一些在FVQA数据集上的结果展示。
下图是在VGQA数据集上和open-ended模型的对比。

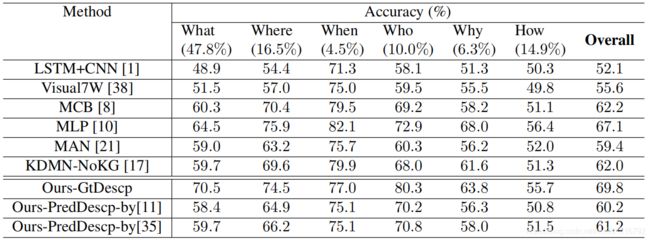
下图是在Visual7W数据集上和multiple-choice模型的对比。
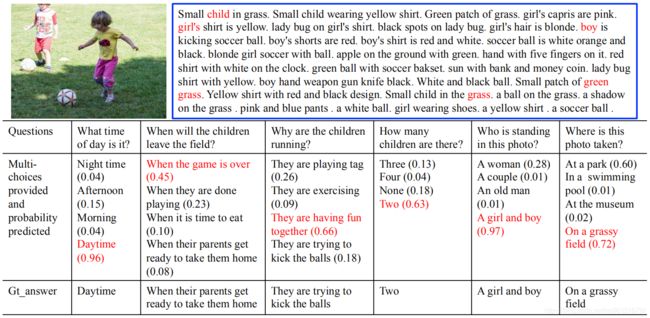
下图是在Visual7W数据集上的successful case展示。
CVPR2019:GQA(数据集)
- 题目
GQA: A New Dataset for Real-World Visual Reasoning and Compositional Question Answering
下载链接 - 动机
针对现有VQA数据集的不足之处,提出GQA数据集。
- 只是用basic、non-compositional的语言,很少需要超出object recognition的能力。
- 对于场景和对象的描述方法存在很多种,使得我们难以学习到明确的语义信息,而这对场景理解至关重要。
- 对于questions的内容、结构、类型等缺少标注信息,使得无法确定模型错误的根本原因。
- 贡献
- 提出GQA数据集用于视觉推理。
- 提出一种有效的生成大量语义变化问题的方法,将场景图表示和计算语言方法相结合。
- 提出了新的metrics,可以更好的对模型进行评估。
- 方法
GQA数据集的构造过程如下图所示,共包括22M的questions和110K个图像。

在构造GQA数据时,首先,需要有每张图像对应的scene graph,这里使用的是Visual Genome数据集。然后,使用question engine生成questions,并且每个question对应一个functional program。然后,要balance答案的分布。最后,对于每个answer,都应指向图中对应的区域。
下图是GQA数据集的一些样例:
下图是对数据集信息的一个统计,共分为:structural types、semantic types、semantic length三张图(图中最后一张画错了)。其中,structural types表示要执行的最终操作,semantic types表示问题的主要主题,semantic length表示推理步骤共几步。

下图是VQA和GQA数据集的对比。

下图对比了多个数据集中question length的分布:

- 实验
下图是一些sota模型在GQA数据集上的实验结果。本文提出了多维度评价指标,主要包括:Consistency(考察模型回答问题的一致性,对于同一张图片的不同问题,回答不应该自相矛盾),Validity(考察模型回答问题的合理性,如颜色相关的问题,模型的回答应该是一种颜色),Plausibility(考察模型回答问题的常识性,如苹果有红色和绿色,但是没有紫色的,所以在问苹果颜色时,不能出现紫色的答案),Distribution(考察预测答案的分布与真实答案的分布之间的距离,如果模型只预测那些经常出现的答案,忽略出现次数少的答案,则此分数较低),Grounding(考察模型是否将attention放在了准确的区域)。

CVPR2019:Cycle-Consistency(数据集)
- 题目
Cycle-Consistency for Robust Visual Question Answering
下载链接
本文出自Facebook AI研究院 - 动机
作者认为,现有VQA方法很少关注模型的鲁棒性。鲁棒性低意味着:对于同一张图片,使用两个相同语义的question(语义相同,可能语法结构有些许变化),模型会输出不同的answer。具体如下图:

- 贡献
- 本文提出了基于循环一致性的训练方法,使得VQA模型更加鲁棒。
- 本文基于VQA2.0数据集提出了VQA-Rephrasings数据集,用于验证模型的鲁棒性。
- 使用本文方法训练的模型,在VQA-Rephrasings数据集上更加鲁棒。
- 方法
本文方法的整体架构如下图中(a)图所示,(b)图代表VQG(Visual Question Generation)模块的结构。从(a)图中可以看出,在传统的训练方法上,本文添加了额外的VQG( A ′ → Q ′ A^{'} \rightarrow Q^{'} A′→Q′)和VQA过程( Q ′ → A ′ ′ Q^{'} \rightarrow A^{''} Q′→A′′),并添加了两个一致性损失:Question Consistency Loss和Answer Consistency Loss。
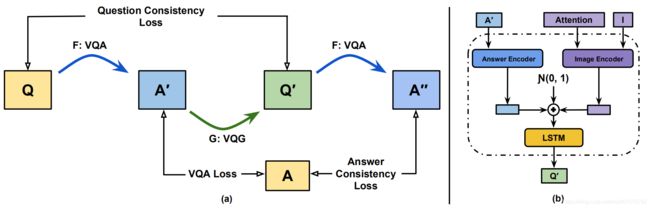
关于上图中(b)图的VQG模块,使用的方法类似于image captioning。而生成后的 Q ′ Q^{'} Q′不能保证和原问题 Q Q Q在语义上具有一致性,故使用门机制过滤掉一些不合适的 Q ′ Q^{'} Q′,作者计算 Q ′ Q^{'} Q′和 Q Q Q的余弦相似度,并用阈值 T s i m T_{sim} Tsim进行过滤。另外,作者在文中提到,为了保证每个模块能够独立的工作,防止联合训练带来的“欺骗”,在经过一定次数的迭代后才激活一致性损失。
关于VQA-Rephrasing数据集,作者从VQA2.0的验证集中随机采样了40504个问题(每个问题和一张图片对应),通过人工标注生成约3倍个数的改写问题,下图展示了一些示例。
- 实验
首先在多个baseline上验证了VQA-Rephrasing数据集的难度。
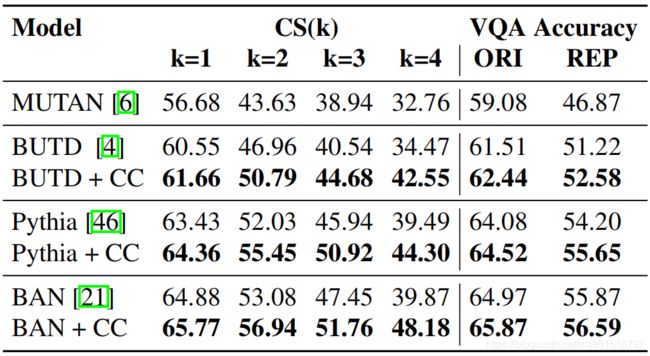
接下来是消融实验。

接下来是,successful cases展示,上面一行代表Pythia原模型,下面一行代表使用本文方法训练的Pythia模型。
ICCV2019:MLIN
- 题目
Multi-modality Latent Interaction Network for Visual Question Answering
下载链接
本文出自港中文+商汤+清华 - 动机
文中提到,现有VQA方法只是对单个的visual regions和words之间的关系进行建模,这与人的思考方式是不同的。人类回答视觉问题,通常会通过视觉信息和问题得到summarizations(提取主要信息),基于此summarizations进行回答。 - 贡献
- 通过多模态信息的summarizations对多模态信息进行交互,这样相当于是一个global的视角,避免了建立无用的visual regions和words之间的关系。
- 在VQA2.0和TDIUC数据集上表现很好。
- 方法
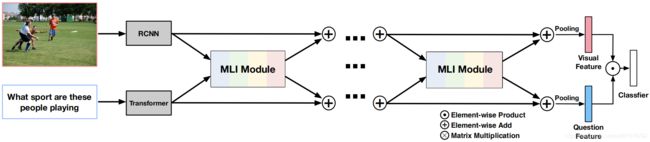
本文方法的整体框架如下图所示,通过堆叠的MLI Module提取Visual Feature和Question Feature。
MLI Module的结构如下图所示,共分为四个步骤,分别是:Summarization、Interaction、Propagation和Aggregation。其中,Summarization用于提取主要的visual features和question features,Interaction将两种模态的信息进行交互,Propagation用于更深层次地理解特征之间的关系,Aggregation用于得到最终的visual features和question features,通过Transformer的key-query注意力机制进行建模。

- 实验
首先,作者在VQA2.0数据集上进行了消融实验,证明了各个模块的有效性。
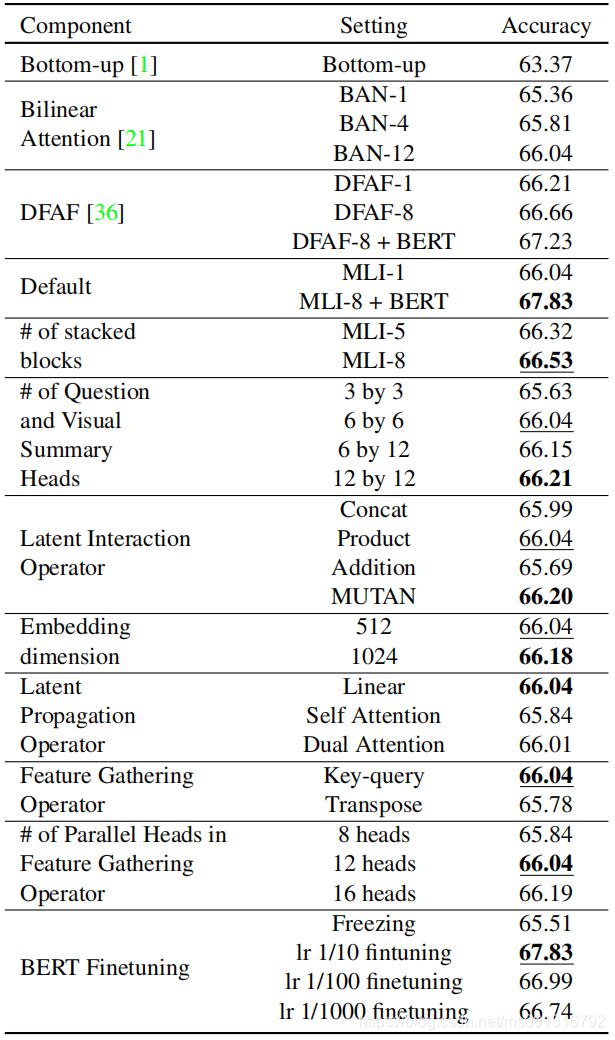
然后,做了与当前sota模型在VQA2.0数据集上的对比。

然后,做了与当前sota模型在TDIUC数据集上的对比。

最后,是attention的可视化展示。
CVPR2019:It`s not about the Journey
- 题目
It’s not about the Journey; It’s about the Destination: Following Soft Paths under Question-Guidance for Visual Reasoning
下载链接 - 动机
- 贡献
- 方法
- 实验
CVPR2019:Transfer Learning via Unsupervised Task Discovery
- 题目
Transfer Learning via Unsupervised Task Discovery for Visual Question Answering
下载链接
本文出自浦项科技大学(韩国)+OpenAI - 动机
在VQA领域,测试集和训练集的单词组成往往是不同的,测试集中经常会出现out-of-vocabulary的答案,本文尝试通过迁移学习解决这个问题。
- 贡献
- 本文提出了基于task conditional visual classifier的用于vqa任务的迁移学习方法。
- 本文提出了无监督的task discovery技术,不使用特定的task标注即可学习task conditional visual classifier。
- 本文方法可以通过迁移visual dataset的知识来处理out-of-vocabulary的answer,不需要question annotations。
- 方法
本文方法的步骤如下图所示,共分为三步:Unsupervised Task Discovery、Pretraining和Transfer to VQA。这三个步骤是渐进的,首先进行Unsupervised Task Discovery,这部分用于得到下一步使用的训练样本对。然后,在Pretraining阶段训练得到Task conditional visual classifier。最后,将上一步训练好的参数迁移到VQA任务中。
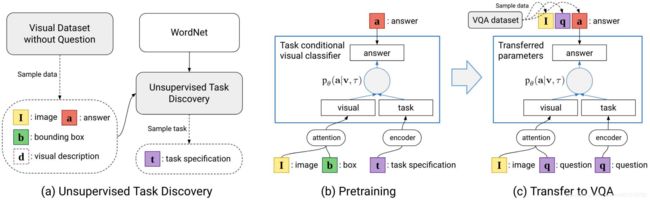
Unsupervised Task Discovery的具体步骤如下图所示,通过Visual Description生成样本对,进行无监督的Task Discovery。

WordNet是一个同义词词集,结构如下图所示。

- 实验
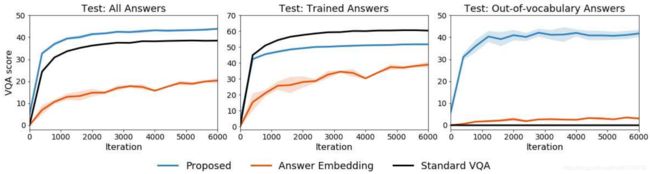
实验结果如下图所示,可以看出,对于out-of-vocabulary数据,本文的方法很有效。
out-of-vocabulary示例展示:
ICCV2019:LCGN
- 题目
Language-Conditioned Graph Networks for Relational Reasoning
下载链接
本文出自UC伯克利。 - 动机
关于复杂的关系推理,已存在很多的研究方法。但是它们都将研究重点放在推理结构(inference structure)上,而忽略了特征。本文提出了LCGN(Language-Conditioned Graph Networks),使用每个节点表示一个物体,基于输入的文本信息,通过迭代的消息传递,最终得到物体的上下文表示(context-aware representation)。

- 贡献
- 提出LCGN。
- 在多个任务上均有效(作者在VQA和REF两个任务上做了实验)
- 方法
下图是本文方法的整体框架。首先,使用双向LSTM提取文本特征,这里作者使用了Stack-NMN(ECCV2018)和MAC(ICLR2018)中的multi-step textual attention。然后,对图像提取local features。最后,进行 T T T轮消息传递,得到output context- aware features。根据不同的任务,再添加不同的组件即可。

- 实验(这里只放VQA部分的实验结果,REF的读者可以去原文中看)
在GQA数据集上的实验结果:

在GQA数据集上,使用不同的local features得到的实验结果:

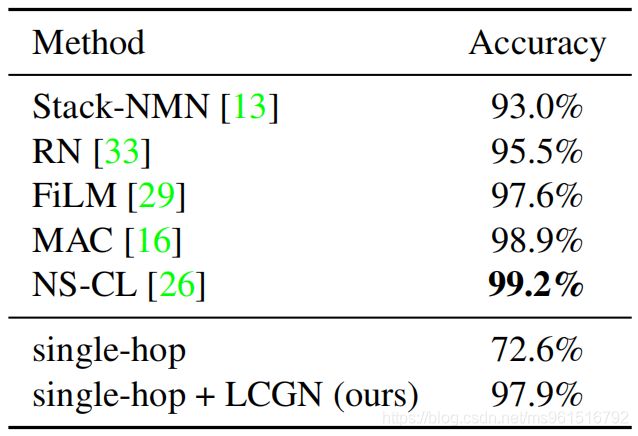
在CLEVER数据集上的实验结果, T = 4 T=4 T=4:
一些中间结果展示:

- 题目
下载链接 - 动机
- 贡献
- 方法
- 实验