python 爬取百度翻译
爬取百度翻译_python
- 1.简介
- 2.百度翻译开发平台
- 3.request分析
- 4.tranBaidu代码
- 5.excelTrans代码
- 5.最终代码
1.简介
准备考研复试的项目,想了想就先做了个简单爬虫,爬取百度翻译单词意思。
2.百度翻译开发平台
- 注册APPID
在百度翻译开发平台上进行注册,并选择开发者插入方式,得到appid,后续会用到。
2.开通服务
根据需要选择api服务,我这里使用的是通用api
3.request分析
-
进行简单的分析
进入百度翻译页面,使用F12进入开发者模式
进行简单的单词翻译
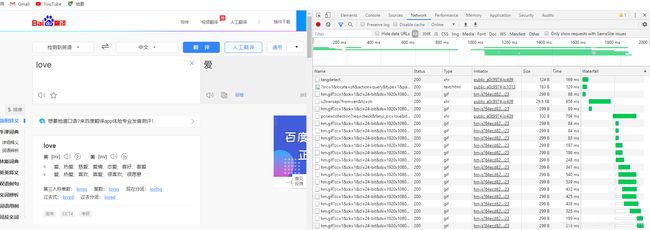
可以在右边的数据栏里找到一个v2transapi开头的数据,我们发现这里有目标译文。尝试解析headers,resoponse,发现关联。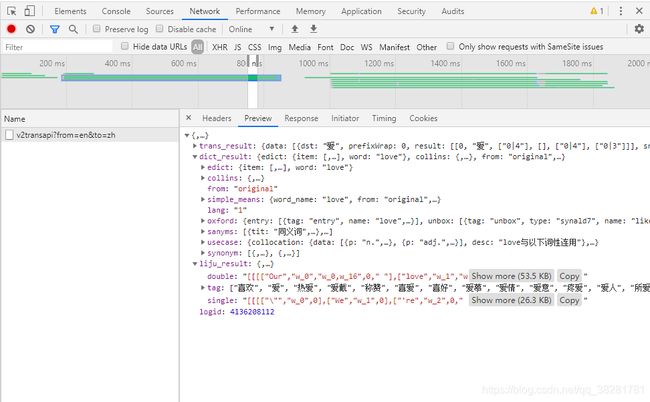
-
查看开发者DEMO文档
在分析request后,回到百度翻译所给的demo(可以在百度翻译开发平台获取)
# coding=utf-8
import http.client
import hashlib
import urllib
import random
import json
appid = '' # 填写你的appid
secretKey = '' # 填写你的密钥
httpClient = None
myurl = '/api/trans/vip/translate'
fromLang = 'auto' #原文语种
toLang = 'zh' #译文语种
salt = random.randint(32768, 65536)
q= 'apple'
sign = appid + q + str(salt) + secretKey
sign = hashlib.md5(sign.encode()).hexdigest()
myurl = myurl + '?appid=' + appid + '&q=' + urllib.parse.quote(q) + '&from=' + fromLang + '&to=' + toLang + '&salt=' + str(
salt) + '&sign=' + sign
try:
httpClient = http.client.HTTPConnection('api.fanyi.baidu.com')
httpClient.request('GET', myurl)
# response是HTTPResponse对象
response = httpClient.getresponse()
result_all = response.read().decode("utf-8")
result = json.loads(result_all)
print (result)
except Exception as e:
print (e)
finally:
if httpClient:
httpClient.close()
阅读后可以知道百度翻译url的加密方式,至此我们对翻译机制有了一定的了解,接下来开始尝试动手写代码了。
4.tranBaidu代码
到此已经可以对单词进行爬取翻译
def transbaidu(res_q):
appid = '你的id' # 百度翻译开发者appid
secretKey = '你的密钥' # 开发密钥
httpClient = None
myurl = '/api/trans/vip/translate'#url地址
fromLang = 'auto' #原文语种
toLang = 'zh' #译文语种
salt = random.randint(32768, 65536)
q= res_q #翻译内容
sign = appid + q + str(salt) + secretKey #密文
sign = hashlib.md5(sign.encode()).hexdigest() #加密MD5
myurl = myurl + '?appid=' + appid + '&q=' + urllib.parse.quote(q) + '&from=' + fromLang + '&to=' + toLang + '&salt=' + str(
salt) + '&sign=' + sign #最终url
try:
httpClient = http.client.HTTPConnection('api.fanyi.baidu.com')
httpClient.request('GET', myurl)
# response是HTTPResponse对象
response = httpClient.getresponse()
result_all = response.read().decode("utf-8")
result = json.loads(result_all)
#print (result['trans_result'][0]['src'])原文
res=result['trans_result'][0]['dst']
return res
except Exception as e:
print (e)
finally:
if httpClient:
httpClient.close()
5.excelTrans代码
- 原文excel
如果我们需要翻译的数据较大或是以文件方式存在,我们也需要在对代码进行update(这里假设原文数据存放在excel文件里面)
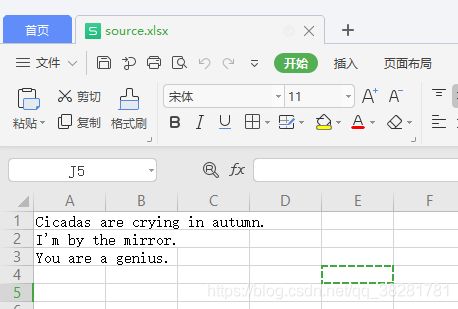
- 使用openpyxl模块对excel进行数据获取,转储。具体不再赘述,模块使用方法见官方文档
点击传送门
需要注意的是百度默认有反爬机制,这里采用的等待时长1s,如果数据实在太大可以采用其他方法。
def excelTrans(
srcFilename=r'D:\test\source.xlsx',
desFilename=r'D:\test\result.xlsx',
srcSheet='Sheet1',
num = 2,
#srcColumn=2,
srcRowBegin=1,
srcRowEnd=44,
desColumn=1,
desSheet='result2'):
wb = openpyxl.load_workbook(srcFilename)
ws = wb[srcSheet]
wb2 = Workbook()
#ws2 = wb2.create_sheet(title=desSheet)
#ws2 = wb2.create_sheet(title=desSheet,index = 1)
for j in range(num):
ws2 = wb2.create_sheet(title=desSheet,index = j)
for i in range(srcRowBegin, srcRowEnd, 1):
sstr = ws.cell(row=i, column=j+1).value
if not (sstr is None):
ws2.cell(row=i-srcRowBegin+1, column=desColumn).value = transbaidu(sstr)
time.sleep(1) #反爬,设置定时;数据太大时就要用多线程了。
wb2.save(desFilename)
- 译文结果

5.最终代码
# coding=utf-8
import http.client
import hashlib
import urllib
import random
import json
import time
import openpyxl
from openpyxl import Workbook
def transbaidu(res_q):
appid = '你的id' # 百度翻译开发者appid
secretKey = '你的密钥' # 开发密钥
httpClient = None
myurl = '/api/trans/vip/translate'#url地址
fromLang = 'auto' #原文语种
toLang = 'zh' #译文语种
salt = random.randint(32768, 65536)
q= res_q #翻译内容
sign = appid + q + str(salt) + secretKey #密文
sign = hashlib.md5(sign.encode()).hexdigest() #加密MD5
myurl = myurl + '?appid=' + appid + '&q=' + urllib.parse.quote(q) + '&from=' + fromLang + '&to=' + toLang + '&salt=' + str(
salt) + '&sign=' + sign #最终url
try:
httpClient = http.client.HTTPConnection('api.fanyi.baidu.com')
httpClient.request('GET', myurl)
# response是HTTPResponse对象
response = httpClient.getresponse()
result_all = response.read().decode("utf-8")
result = json.loads(result_all)
#print (result['trans_result'][0]['src'])原文
res=result['trans_result'][0]['dst']
return res
except Exception as e:
print (e)
finally:
if httpClient:
httpClient.close()
def excelTrans(
srcFilename=r'D:\test\source.xlsx',
desFilename=r'D:\test\result.xlsx',
srcSheet='Sheet1',
num = 2,
#srcColumn=2,
srcRowBegin=1,
srcRowEnd=44,
desColumn=1,
desSheet='result2'):
wb = openpyxl.load_workbook(srcFilename)
ws = wb[srcSheet]
wb2 = Workbook()
#ws2 = wb2.create_sheet(title=desSheet)
#ws2 = wb2.create_sheet(title=desSheet,index = 1)
for j in range(num):
ws2 = wb2.create_sheet(title=desSheet,index = j)
for i in range(srcRowBegin, srcRowEnd, 1):
sstr = ws.cell(row=i, column=j+1).value
if not (sstr is None):
ws2.cell(row=i-srcRowBegin+1, column=desColumn).value = transbaidu(sstr)
time.sleep(1) #反爬,设置定时;数据太大时就要用多线程了。
wb2.save(desFilename)
if __name__ == '__main__':
excelTrans()
以上就是pytthon爬取百度翻译,要准备下一个项目了,真希望复试能过,好想有书读,太卑微了