手把手 | 数据科学速成课:给Python新手的实操指南
数据科学团队在持续稳定的发展壮大,这也意味着经常会有新的数据科学家和实习生加入团队。我们聘用的每个数据科学家都具有不同的技能,但他们都具备较强的分析背景和在真正的业务案例中运用此背景的能力。例如,团队中大多数人都曾研究计量经济学,这为概率论及统计学提供了坚实的基础。
典型的数据科学家需要处理大量的数据,因此良好的编程技能是必不可少的。然而,我们的新数据科学家的背景往往是各不相同的。编程环境五花八门,因此新的数据科学家的编程语言背景涵盖了R, MatLab, Java, Python, STATA, SPSS, SAS, SQL, Delphi, PHP to C# 和 C++。了解许多不同的编程语言在有些时候确实很有必要,然而我们更希望使用一种编程语言来完成大多数的项目,这样我们可以在项目上更容易的进行合作。由于无人知晓一切,一种首选的编程语言让我们有机会互相学习。
我们公司更倾向于使用Python。在开源社区的大力支持下,Python已经成为了处理数据科学强有力的工具。Python容易使用的语法,强大的数据处理能力和极好的开源统计库,例如Numpy, Pandas, Scikit-learn, Statsmodels等,使我们可以完成各种各样的任务,范围从探索性分析到构建可伸缩的大数据管道和机器学习算法。只有对那些较宽松的统计模型我们有时会将Python和R结合使用,其中Python执行大量的数据处理工作和R进行统计建模。
我的理念是通过实践来学习,因此为了帮助新数据科学家使用Python进行数据科学研究,我们创建了Python数据科学(速成)课(Python Data Science (Crash) Course)。这门课的目标是使我们的新员工(也包括其他部门的同事)以互动的方式和自己的节奏来学习解决实际的业务问题。与此同时,更有经验的数据科学家可以回答任何问题,但也不要小看从StackOverflow或者图书馆的文档中寻找答案的的技能,我们也当然愿意向新数据科学家传授这项技能!
在文章中,我们会按阶段来介绍这个实践课程。
阶段一:学习Python的基础知识
显而易见,第一步是学习Python这个软件,即学习Python语法及基本操作。幸运的是,如果你能处理好代码缩进的话,Python语法就不没那么难了。我在使用Java编程语言时无需考虑注意缩进问题,然而当我之后开始使用Python时在缩进上容易出错。
因此,如何开始学习Python?由于我们更喜欢通过实践来学习的方式,所以我们总是让新员工从Codecademy Python课程开始。Codecademy提供了交互式的Python课程体验,无需担心安装软件会麻烦,可以在浏览器中直接学习使用Python。
Codecademy Python课程用时大约13个小时,完成之后,你应该能够在Python中进行简单的操作。
提示:数据科学家还可以在Codecademy上学习SQL,这门课程也十分重要。

阶段二:在Anaconda环境下本地安装Python
在结束了Codecademy课程后,我们显然会想去开始编写自己的代码,然而因为我们不继续在浏览器中运行Python,需要在我们本地电脑上安装Python。
Python是开源的,并可通过www.python.org.免费下载。然而官方版本只包含了标准的Python库,标准库中包含文本文件、日期时间和基本算术运算之类的函数。Python标准库不够全面,无法进行多样化的数据科学分析,但开源社区已经创建出了很棒的库来扩展Python的功能,使其能够进行数据科学研究。
为了避免单独下载安装所有的库,我建议使用Anaconda Python发行版。Anaconda实际上是与大量的库结合在一起的Python,因此你不需要手动安装它们。此外,Anaconda附带了一个简单的命令行工具,在必要时安装新的或更新现有的库。
提示:尽管默认情况下Anaconda几乎涵盖了所有很棒的库,但还有一些没有包含在内。你可以通过conda install package_name or pip install package_name语句来安装新的包。例如,我们经常在项目中使用进度条库 tqdm。因此,我们需要先执行pip install tqdm语句来完成Anaconda的新安装。

阶段三:使用PyCharm进行简单的编码
安装了Python之后,我们可以在本地电脑上运行Python代码。打开编辑器写下Python代码,打开命令行并运行新创建的Python文件,路径为python C:\Users\thom\new_file.py。
为了使事情变得简单一些,我更喜欢在Pychanm环境中编写Python代码。PyCharm是一种所谓的集成开发环境,对开发人员编写代码时提供支持。它可以处理常规任务,例如通过提供一个简单的运行脚本按钮来运行程序,此外它还可以通过提供自动完成功能和实时错误检查来提高效率。如果忘记了某处的空格或使用了未被定义的变量名称,PyCharm会发出警告提示。想要使用版本控制系统例如Git来进行项目合作?PyCharm会帮助你。不管怎样,使用Pycham可以在编写Python程序时节省大量的时间,charm名副其实。
阶段四:解决一个模拟的业务问题
定义研究的问题假设现在经理提出了一个他面对的业务问题,他希望能够预测用户在公司网站上进行首次点击/参与(例如订阅简报)的概率。在给出了一些想法后,我们提出可以基于用户的页面浏览量来预测订阅转换概率,此外,你构建了以下假设:更多的页面浏览量会导致用户首次订阅的概率增大。
为了检验假设是否成立,我们需要从网络分析师处获得两个数据集:
• Session数据集 包含所有用户的所有页面浏览量。
1. user_id: 用户标识符
2. session_number: 会话数量(升序排列)
3. session_start_date: 会话的开始日期时间
4. unix_timestamp: 会话的开始unix时间标记
5. campaign_id: 将用户带到网站的活动的ID
6. domain: 用户在会话中访问的(子)域
7. entry: 会话的进入页面
8. referral: 推荐网站,例如:google.com
9. pageviews: 会话期间的页面访问量
10. transactions: 会话期间的交易量
• Engagement数据集 包含所有用户的所有参与活动。
1. user_id:唯一的用户标识符
2. site_id: 产生参与活动的网站ID
3. engagement_unix_timestamp: 发生参与活动的unix时间标记
4. engagement_type: 参与活动的类型,例如订阅简报
5. custom_properties: 参与活动的其他属性
不幸的是,我们有两个单独的数据集,因为它们来自不同的系统。然而,两个数据集可以通过唯一用户标识符user_id来匹配。我已经在GitHub上放置了我用来解决业务问题的最终代码 ,然而我强烈建议你仅在自己解决了这个问题后再去查看代码。此外,你还可以找到创建两个虚构数据集的代码。
代码链接:
https://github.com/thomhopmans/themarketingtechnologist/tree/master/7_data_science_in_python
使用Pandas进行简单的数据处理
无论我们应用任何统计模型解决问题,都需要预先清洗和处理数据。例如,我们需要为会话数据集中的每个用户找到其首次活动的数据(如果有的话)。这就要求在user_id上加入两个数据集,并删除首次活动后的其他所有活动数据。
Codecademy Python课程已经告诉你如何逐行阅读文本文件。Python非常适合数据管理和预处理,但不适用于数据分析和建模。
Python的Pandas库克服了这个问题。Pandas提供了(数值)表和时间序列的数据结构和操作。因此,Pandas让Python数据科学工作变得更加简单!
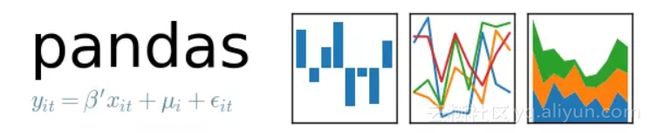
使用pd.read_csv()读取数据集
我们的Python代码中的第一步是加载Python中的两个数据集。Pandas提供了一个简单易用的函数来读取.csv文件:read_csv()。本着学习的原则,我们建议您自己找出如何读取这两个数据集。最后,你应该建立两个独立的DataFrames,每个数据集都需要有一个。
小贴士:在这两个文件中,我们都有不同的分隔符。此外,请务必查看read_csv()中的date_parser选项,将UNIX时间标记转换为正常的日期时间格式。
过滤无用数据
任何(大)数据问题中的下一步是减少问题规模的大小。在我们的例子中,有很多与我们问题无关的列,例如会话的媒介/来源。因此,我们在Dataframes上应用索引和选择只保留相关的列,比如user_id(必需加入这两个DataFrames),每个会话和活动的日期(在此之前搜索首次活动和会话)以及页面访问量(假设验证的必要条件)。
另外,我们会筛选出DataFrame中所有非首次的活动。可以通过查找每个user_id的最早日期来完成。具体怎样做呢?使用GroupBy:split-apply-combine逻辑!
Pandas最强大的操作之一是合并,连接和序列化表格。它允许我们执行任何从简单的左连接和合并到复杂的外部连接。因此,可根据用户的唯一标识符结合会话和首次活动的DataFrames。
删除首次活动后的所有会话
在上一步中使用简单的合并,我们为每个会话添加了首次活动的时间标记。通过比较会话时间标记与首次活动时间标记,你应该能够过滤掉无用的数据并缩小问题的规模。
添加因变量y:参与/订阅活动转换
如上所述,我们希望预测页面访问量对转换(即首次活动)概率的影响。因此,我们的因变量y是一个二进制变量,用它表示会话内是否发生了转换。由于我们做了上面的过滤(即在首次活动后删除所有非首次活动和会话),所以这种转换按照定义在每个用户的最近一次会话中进行。同样,使用GroupBy:split-apply-combine逻辑,我们可以创建一个包含观察值的新列,如果它是用户的最后一个会话,观察值将为1,否则为0。
添加自变量X:访问量的累计总和
我们的自变量是页面访问量。但是,我们不能简单地将会话中的页面访问量计算在内,因为早期会话中的页面访问会影响转换概率。因此,我们创建一个新的列,用来计算用户页面访问量的累计总和。这才是我们的自变量X。
使用StatsModels拟合逻辑回归
通过Pandas库我们最终得到了一个包含单个离散X列和单个二进制Y列的小型DataFrame。并用(二元)逻辑回归模型来估计基于一个或多个独立变量的因变量的二元响应概率。StatsModels是Python的统计和计量经济学库,提供了参数估计和统计测试工具。因此,它包含逻辑回归函数也就不足为奇了。那么,如何通过StatsModels来拟合逻辑回归模型呢?请自行百度...
技巧1:不要忘记给逻辑回归添加一个常数。
技巧2:另一个非常棒的拟合统计模型(如逻辑回归)库是scikit-learn。
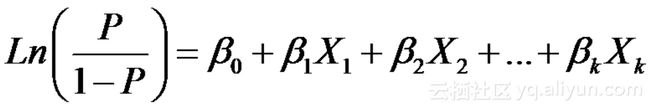
使用Matplotlib或Seaborn进行可视化
在拟合逻辑回归模型之后,我们可以预测每个累计访问量的转换概率。但是,我们不能仅仅通过交付一些原始数据来将我们最新发现的结果传达给管理层。因此,数据科学家的重要任务之一就是要清晰有效地展示他的成果。在大多数情况下,这意味着提供我们的可视化结果,因为众所周知,一图胜千言...
Python包含几个非常棒的可视化库,其中MatplotLib是最知名的。而Seaborn是建立在MatplotLib上的另一个很棒的库。
MatplotLib的语法大概是以前使用过MatLab的用户所熟知的。但是,我们倾向选择Seaborn,是因为它提供更漂亮的图表而且外观很重要。
我们通过Seaborn得到了模型拟合的可视化结果,如下所示:
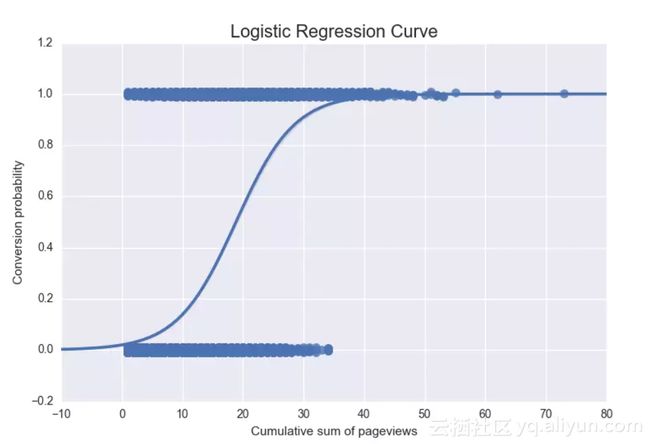
我们可以很好地利用这个可视化结果来证明我们的假设是否成立。
验证假设
最后一步是就验证我们提出的假设是否成立。回想一下,我们认为更多的网页访问量导致首次活动的可能性更高。
首先,我们从以前的可视化结果中可以看出,假设是成立的。不然,预测的概率也不会单调递增。尽管如此,我们还是可以从拟合的模型总结中得出同样的结论,如下所示。
Logit Regression Results
==============================================================================
Dep. Variable: is_conversion No. Observations: 12420
Model: Logit Df Residuals: 12418
Method: MLE Df Model: 1
Date: Tue, 27 Sep 2016 Pseudo R-squ.: 0.3207
Time: 21:44:57 Log-Likelihood: -5057.6
converged: True LL-Null: -7445.5
LLR p-value: 0.000
====================================================================================
coef std err z P>|z| [95.0% Conf. Int.]
------------------------------------------------------------------------------------
const -3.8989 0.066 -59.459 0.000 -4.027 -3.770
pageviews_cumsum 0.2069 0.004 52.749 0.000 0.199 0.215
====================================================================================我们看到,统计结果中,pagesviews_cumsum系数在显著性水平为1%时显示为正。因此,这足以表明我们的假设成立,加油!此外,您刚刚已经完成了第一个Python数据科学分析工作!:)
原文发布时间为:2018-03-6
本文作者:文摘菌
本文来自云栖社区合作伙伴“大数据文摘”,了解相关信息可以关注“大数据文摘”微信公众号