如何让对抗网络GAN生成更高质量的文本?LeakGAN现身说法:“对抗中,你可能需要一个间谍!”...
自生成式对抗性网络 GANs 出现以来,它和它的变体已经无数次在图像生成任务中证明了自己的有效性,也不断地吸引着越来越多的研究人员加入到提高GANs训练的可控性和稳定性的研究中。
最初,由于其中的一个缺陷,GANs在文本生成方面无法得到有效的应用。得益于该团队之前发表的SeqGAN,GANs在文本生成上有了可能,不过表现并没有图像生成任务中那么突出。主要问题之一就是,生成器 G 从鉴别器 D 获得的反馈中含有的信息量太少,不足以有效地引导 G 更新、提升文本生成质量,尤其是当文本长度较长的时候。
这就引出了下面这个问题:如果让鉴别器反馈更多信息给生成器,是否能够有效地改善生成器在长句生成任务中的表现呢?上海交通大学俞勇教授、张伟楠助理教授及学生郭家贤、卢思迪、蔡涵联合UCL计算机系汪军教授共同完成的论文「Long Text Generation via Adversarial Training with Leaked Information」(通过有信息泄露的对抗性训练生成长文本)中,他们就对长句子的文本生成这个问题进行了研究,找到了答案,提出了行之有效的方法,为对抗网络广泛用在机器人问答,自动生成新闻,和机器翻译等应用中提供了可能性。

生成式对抗性网络(GANs)最初是为生成图像之类的连续数据设计的。之前该小组提出的 SeqGAN 等模型可以处理分段的序列离散数据,这样就可以为对抗网络文本生成提供了可能,展现出了一些有潜力的成果。由于英文文本是天然地分为一个一个词的,逐词的文本生成任务可以被建模为一个序列决策过程,对于其中的每一步,当前状态是已经生成的词,行为是即将要生成的词,生成式网络 G 就是一个把当前状态映射到行为空间分布的随机策略。当整句文本生成结束之后,生成的这个句子就会被送入鉴别器 D,它经过训练之后能够把真实的文本和生成的文本区分开,区分的结果就会作为 G 的得到的回报,引导它更新。
SeqGAN之后,研究人员们提出了许多把 GANs 及其变体用于文本生成的方法。然而,这些研究结果往往局限于生成的文本较短的情况(比如20个词以内),更困难的长文本生成方面则没有看到多少研究。在新闻报道、产品说明的自动生成这种实际任务中,长文本生成能力是不可或缺的。目前基于序列决策的文本生成方法中有一个很大的不足,那就是来自鉴别器 D 的概率标量反馈信号是稀疏的,因为文本虽然是由 G 在多轮行动中逐个词生成的,但只有当整个句子都生成完毕后 G 才能收到来自 D 的反馈信号。而且,G 本应是在 D 的指导下更新自己的策略的,但 D 对这整段文字的反馈是一个标量,信息量极为有限,不足以保留过程中的句法结构和文本语意,也就无法有效地帮助 G 学习更新。
一方面,为了增加来自鉴别器 D 的信息量,它应当在最终的判别反馈值之外提供更多的指导信息,毕竟 D 是一个结构已知的、经过训练的 CNN网络,而不是一个黑箱子,完全有可能让 D 提供更多的信息。另一方面,来自 D 的指导信息仍然是稀疏的,为了缓解这个问题,作者们想到了利用文本生成中的层次性,即:真实的文本样本都是遵照语意结构和词性之类的语言层次而写出的。通过把整个文本生成任务按照层次结构分解成多个子任务,模型就能够更轻松地进行学习。
在这篇论文中,作者们就沿着以上的思路,提出了名为 LeakGAN 的模型结构,同时处理 D 反馈信息量不足和反馈稀疏的两个问题。LeakGAN 就是一种让鉴别器 D 提供更多信息给生成器 G 的新方式。

如图所示,为了利用从D中泄露出的高维信息,作者们参考DeepMind在ICML2017中发表的FeUdal Network设计了一个层次化的生成器 G,其中包含了一个高阶的 Manager 模块和低阶的 Worker 模块。Manager 模块是一个 LSTM 网络,它起到的作用是信息中介。在每一轮生成新一个单词的过程中,Manager 模块都会从鉴别器 D 接收到高维特征表征,比如 D 的CNN网络中的feature map,然后 Manager 模块就会利用这些信息形成指导目标(goal),作用于当前的 Worker 模块。由于 D 和 G 的角色本来是对抗性的,D 中的信息只应当保留在自己内部;但现在有一些 D 中的信息被“泄露”给 G 了,好像间谍一样,所以作者们把它命名为 LeakGAN。
接着,当 Manager 模块生成了目标嵌入(goal embedding)之后,Worker 模块会把当前已生成的单词用另一个 LSTM 网络编码,然后把 LSTM 的输出和目标嵌入结合起来,以确保能够综合依据 Manager 的指导和当前状态生成一个合适的新单词。通过这样的过程,来自 D 的反馈信息就不仅仅表现为整句话生成完成后的判别结果的那个标量,更在这句话的生成过程中就通过目标嵌入向量的方式提供了许多信息,指导 G 提升自己的表现。
据作者们介绍,这是首个GAN框架中通过泄露信息的方式来更好地训练生成器,并且结合了层次化强化学习来解决长文本生成问题的研究。
根据作者们的设计,生成器中 Manager 模块接收来自 D 的特征向量、生成目标嵌入以及 Worker 模块结合当前句子和目标生成新单词的整个过程都是可微的,所以REINFROCE这样的策略梯度算法可以被直接端到端地(end to end)用于训练 G。但是,由于Manager 模块和Worker模块被期望能专注于各自的任务以识别到有意义的特征,所以正如FeUdal Network中的做法,Manager 模块和 Worker 模块是被单独训练的,其中 Manager 模块要能从鉴别器的特征空间中预测到更有价值的方向,而 Worker 模块沿着这个方向做出行动的话就会收到奖励。训练时, Manager 模块和 Worker 模块也是交替更新的,每次都是固定一个、更新另一个。
并且,作者们也仔细设计了训练方法来应对一般的 GAN 训练中容易出现的问题,比如当 D 比 G 强很多的时候会出现梯度消失的问题。受到 RankGAN 中排序方法的启发,他们提出了一个简单高效、基于排名的方法“自举再激活”(Bootstrapped Rescaled Activation)来调整 D 的反馈大小。经过这个转换后,每个mini-batch得到的反馈的期望和差值会成为常数,这个方法就相当于是一个值稳定器,当算法对数值大小很敏感的时候能够起到很大帮助;而且,作为排序方法,它也能避免梯度消失的问题,这加速了模型的收敛。
作者们还采取了交替训练(Interleaved Training)的方法来避免模式崩溃(mode collapse)的问题,即,在预训练之后,不是像以往一样全部由对抗式训练直到收敛,而是让监督学习训练和对抗式训练交替进行。这种做法的意义是能够帮助模型避开不好的局部最小值,并避免模式崩溃。另一方面,加入的监督学习训练也是对生成模型的一种隐式正则化,避免模型行为偏离监督学习的结果太远。

训练曲线如图,可以看到,LeakGAN 的负对数似然下降得比以往的方法都要快得多;在文本长度为40的状况下,以往的方法甚至很难收敛。
作者们基于生成的数据和真实数据做了许多的实验。在基于生成的数据的实验中,LeakGAN 在20到40词长度的文本序列中取得了比以往模型明显更低的负对数似然。(表1)

在基于真实数据的实验中,作者们选用了 EMNLP 2017 WMT新闻、COCO图像标注和中文诗词分别作为长、中、短的文本语料,LeakGAN也取得了最高了BLEU分数。(表2、3、4)


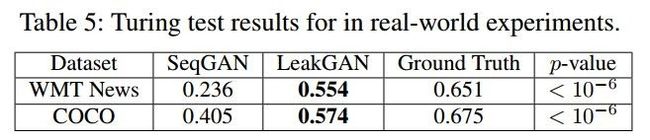
在人类图灵测试中,LeakGAN也比以往模型取得了明显提高。(表5)
作者们还对 Manager 模块和 Worker 模块之间的互动行为做了深入的研究,结果表明 LeakGAN 在没有显式给出句子结构的情况下可以隐式地学到句子结构,比如标点符号、时态和长后缀。
下面是一个该模型生成文本例子与之前工作的对比:

研究的具体细节可以参见原论文 https://arxiv.org/abs/1709.08624 ,论文中有丰富的附录介绍了训练过程中的数据,提供了不少生成的句子,并且提供了模型代码。
此外,我们也邀请到了论文作者之一的张伟楠到雷锋网做公开课,讲解这篇论文的成果以及用GANs做文本生成相关研究的更多状况。

张伟楠现于上海交通大学计算机系和约翰·霍普克罗夫特研究中心担任助理教授,研究方向为机器学习及其在数据挖掘问题中的应用。他于2011年毕业于上海交通大学计算机系ACM班,于2016年获得英国伦敦大学学院计算机系博士学位,研究成果在国际一流学术会议和期刊上发表50篇论文,其中5次以第一作者身份在ACM国际数据科学会议KDD上发表;2016年获得由微软研究院评选的“全球SIGKDD Top 20科研新星”称号;2017年获得ACM国际信息检索会议SIGIR的最佳论文提名奖。他曾在KDD-Cup用户个性化推荐大赛获得全球季军,在全球大数据实时竞价展示广告出价算法大赛获得最终冠军。