命名体识别(NER)实战---NLP技术
命名体识别(Name Entity Recognition)是自然语言处理(Nature Language Processing)领域中比较重要的一个任务,几乎百分之50的和文本处理有关的项目中都会涉及到命名体识别。笔者认为其中最关键的原因是:从广义的角度来讲,如果把一句话比作一串珍珠的话,命名实体就是这串珍珠项链中的珍珠,句子的其他部分是把珍珠串起来的线。
举个例子: "小明在1992年从哈佛大学毕业 "
其中小明,1992年,哈佛大学都是命名实体,而这些实体包含了这句话里面的极为重要信息:人物信息,时间信息,还有组织信息。而其他的词将这些实体串起来,才能表达出这句话完整的语义。
而在一些专业领域,比如化学,医药领域,经常出现一些四氧化三铁,阿尔兹海默症等专业词汇,如果只通过简单的分词很难将这些重要的关键词汇识别出来。而在这样的场景下,NER就能发挥出它的威力了。
总而言之,NER 的任务就是要将这些包含信息的或者专业领域的实体给识别出来。这个过程是不是很像在一串珍珠项链里面识别出宝贵的珍珠(这个比喻笔者觉得只能算凑合)。
NER任务简介
NER是一个序列标注任务,和分词,词性标注的任务属同一类。任务的输入是一串序列,输出也是一串序列。例子如下:
输入:[北,京,天,气,真,不,错]
输出:[1,2,0,0,0,0,0]
其中1表示位置实体的开头(B_LOC),2表示位置实体的中间(I_LOC),通过 B_LOC和I_LOC我们就可以锁定北京这个位置实体。
NER算法简介
NER算法从上古时期的HMM,到CRF,再到现在的特别火爆的深度学习CNN+BiLSTM+CRF(论文地址),算法的准确率可谓是节节高升,现在的比较先进CNN+BiLSTM+CRF算法已经可以达到97%以上的准确率了。这里我只简单介绍一下最先进的CNN+BiLSTM+CRF 算法。算法分为三个部分,每个部分各司其职:
(1)CNN 做字符级别的编码,主要解决OOV(out of vocabulary :测试数据中出现了训练数据中未出现过的词)的问题。
(2)LSTM 作为神经网络的一份子,其强大的拟合能力可以很好的完成这个序列标注问题。
(3)CRF能记住实体序列的规则。它的作用是纠正LSTM的一些低级错误。
有兴趣的同学可以研读一下这篇论文。
NER实战部分
如果一个深度学习项目摆在你面前,基本可以不假思索的列出下面这四部:
1.数据预处理;
2.构建网络模型;
3.训练网络模型,优化模型;
4.预测;
当然我省去了头部极为费时费力的数据清洗,数据标注步骤(为数据标注工程师打call),以及尾部的模型上线和模型迭代优化步骤。
我这里的实战代码使用的是阉割版的CNN+BiLSTM+CRF---BiLSTM+CRF。
数据预处理
训练数据的样式如下图所示。

NER数据样式.png
定义Dataset类,封装一些数据读入和预处理方法。
import pickle
import numpy as np
from keras.preprocessing.sequence import pad_sequences
from keras import Sequential
from keras_contrib.layers import CRF
import pickle
from keras.layers import Embedding ,Bidirectional,LSTM
class Data_set:
def __init__(self,data_path,labels):
with open(data_path,"rb") as f:
self.data = f.read().decode("utf-8")
self.process_data = self.process_data()
self.labels = labels
def process_data(self):
train_data =self.data.split("\n\n")
train_data = [token.split("\n") for token in train_data]
train_data = [[j.split() for j in i ] for i in train_data]
train_data.pop()
return train_data
def save_vocab(self,save_path):
all_char = [ char[0] for sen in self.process_data for char in sen]
chars = set(all_char)
word2id = {char:id_+1 for id_,char in enumerate(chars)}
word2id["unk"] = 0
with open (save_path,"wb") as f:
pickle.dump(word2id,f)
return word2id
def generate_data(self,vocab,maxlen):
char_data_sen = [[token[0] for token in i ] for i in self.process_data]
label_sen = [[token[1] for token in i ] for i in self.process_data]
sen2id = [[ vocab.get(char,0) for char in sen] for sen in char_data_sen]
label2id = {label:id_ for id_,label in enumerate(self.labels)}
lab_sen2id = [[label2id.get(lab,0) for lab in sen] for sen in label_sen]
sen_pad = pad_sequences(sen2id,maxlen)
lab_pad = pad_sequences(lab_sen2id,maxlen,value=-1)
lab_pad = np.expand_dims(lab_pad, 2)
return sen_pad ,lab_pad
数据处理部分
data = Data_set("drive/My Drive/dataset/ner_data/train_data.data",['O', 'B-PER', 'I-PER', 'B-LOC', 'I-LOC', "B-ORG", "I-ORG"])
vocab = data.save_vocab("vocab.pk")
sentence,sen_tags= data.generate_data(vocab,200)
原始数据格式如下:
句子:[冬天的上海真冷]
tag : [O,O,O,B_LOC,I_LOC,O,O]
执行完上方代码后,就可以将数据处理成这样:
word_id: [0,0,0......35,67,2,89,21,36,78]
tag_id. : [-1,-1,-1......0,0,0,1,2,0,0]
word_id 是将字映射成词典中对应的id,tag_id是将tag映射成tag对应的id。数据被处理成这样格式之后,才能喂给模型。需要注意的是笔者在这里没有使用预先训练好的词向量。
BiLSTM+CRF模型构建
定义一个BiLSTM+CRF类,封装模型的构建,训练和预测方法。
class Ner:
def __init__(self,vocab,labels_category,Embedding_dim=200):
self.Embedding_dim = Embedding_dim
self.vocab = vocab
self.labels_category = labels_category
self.model = self.build_model()
def build_model(self):
model = Sequential()
model.add(Embedding(len(self.vocab),self.Embedding_dim,mask_zero=True)) # Random embedding
model.add(Bidirectional(LSTM(100, return_sequences=True)))
crf = CRF(len(self.labels_category), sparse_target=True)
model.add(crf)
model.summary()
model.compile('adam', loss=crf.loss_function, metrics=[crf.accuracy])
return model
def train(self,data,label,EPOCHS):
self.model.fit(data,label,batch_size=16,epochs=EPOCHS)
self.model.save('crf.h5')
def predict(self,model_path,data,maxlen):
model =self.model
char2id = [self.vocab.get(i) for i in data]
pad_num = maxlen - len(char2id)
input_data = pad_sequences([char2id],maxlen)
model.load_weights(model_path)
result = model.predict(input_data)[0][-len(data):]
result_label = [np.argmax(i) for i in result]
return result_label
构建ner模型
tags = ['O', 'B-PER', 'I-PER', 'B-LOC', 'I-LOC', "B-ORG", "I-ORG"]
ner = Ner(vocab,tags)
其架构图如下:

BiLSTM+CRF架构图
模型训练
ner.train(sentence,sen_tags,1)
运行上方代码模型就开始训练,训练过程如图所示,笔者只设置了一个epoch做这个实验。至此模型顺利跑起来了。
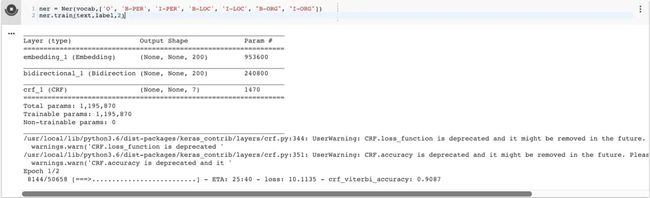
BILSTM+CRFj架构训练截图.png
模型预测
sen_test = "北京故宫,清华大学图书馆"
res = ner.predict("./crf.h5",sen_test,200)
label = ['O', 'B-PER', 'I-PER', 'B-LOC', 'I-LOC', "B-ORG", "I-ORG"]
res2label =[label[i] for i in res]
per, loc, org = '', '', ''
for s, t in zip(a, res2label):
if t in ('B-PER', 'I-PER'):
per += ' ' + s if (t == 'B-PER') else s
if t in ('B-ORG', 'I-ORG'):
org += ' ' + s if (t == 'B-ORG') else s
if t in ('B-LOC', 'I-LOC'):
loc += ' ' + s if (t == 'B-LOC') else s
print("人名:",per)
print("地名:",loc)
print("组织名:",org)
训练完模型后,执行上面代码就会返回如下结果:
人名:
地名:北京 故宫 清华大学图书馆
组织名:
当然你也可以尝试一下其他带有实体的句子作为输入。至此整个NER的任务基本上就算完成了。是不是So easy。
结语
序列标注(分词,NER),文本分类(情感分析),句子关系判断(语意相似判断),句子生成(机器翻译)作为NLP领域的四大任务,今天笔者只对序列标注任务--NER进行了介绍,之后也会对其他任务逐一进行介绍,希望能够帮助大家初步了解NLP这个神秘的领域。收!
参考:
End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF
https://github.com/stephen-v/zh-NER-keras
https://github.com/Determined22/zh-NER-TF
转载链接:https://www.jianshu.com/p/6668b965583e