Python语言程序设计课程论文
文章目录
- 摘要
- Abstract
- 第1章 引言
- 1.1 课题背景
- 1.2 目的和意义
- 1.3 系统设计思想
- 1.4 系统开发环境
- 1.5 系统运行要求
- 第2章 需求分析
- 2.1 系统功能分析
- 2.2 系统整体业务流程
- 第3章 总体设计
- 3.1 系统总体设计
- 3.1.1 系统模块功能
- 3.2 数据库设计概述
- 3.2.1 数据库选择
- 3.2.2 数据库编码
- 3.3 数据库详细设计
- 3.3.1 数据库物理结构设计
- 3.3.2 数据表的设计
- 第4章 详细设计
- 4.1 数据爬取
- 4.1.1 爬取腾讯疫情网页
- 4.1.2 爬取百度热搜页面
- 4.2 数据存储(MySQL)
- 4.2.1 与数据库连接/关闭
- 4.2.2 腾讯数据存取
- 4.2.2.1 插入历史表数据
- 4.2.2.2 更新历史表数据
- 4.2.2.3 更新细节表数据
- 4.2.3 百度热搜数据存取
- 4.3 前台展示
- 4.4 数据获取
- 4.4.1 获取数据库数据
- 4.4.2 获取数据并解析
- 4.4.3 Ajax请求
- 第5章 实验展示
- 第6章 系统测试
- 6.1 测试方案概述
- 6.2 测试计划与实施
- 6.2.1 是否正确爬取到数据
- 6.2.2 是否正确落盘到数据库
- 6.2.3 是否正确获取数据库的数据
- 6.2.4 各个模块是否正常显示
- 结论
- 参考文献
- 致谢
摘要
今年世界的疫情深挂人心,为使人们更加清楚了解到疫情的走向,本系统向人们展示疫情的实时现状,使人们做好必要的预防工作。
本系统后端通过Python爬取腾讯以及百度热搜网页的数据,将数据解析并且落盘到MySQL;前端通过Ajax发送请求,Python从MySQL获取数据并传输到前端,通过Echarts组件进行渲染的一系列过程。
关键字: 爬取MySQL Ajax Echarts
Abstract
This year’s world epidemic is deeply popular, in order to make people more clearly understand the direction of the epidemic, the system to show people the real-time status of the epidemic, so that people do the necessary prevention work.
The back end of the system uses Python to crawl the data of Tencent and Baidu Hot Search Web pages, parse the data and drop it to MySQL, the front end sends a request through Ajax, Python obtains the data from MySQL and transmits it to the front end, rendering through the Etables component.
Keywords: Crawl MySQL Ajax Echarts
第1章 引言
1.1 课题背景
2020年的疫情注定载入史册。疫情的情况牵挂人心,因此实现一个疫情实时状况显得尤为必要,本系统因此而诞生。
1.2 目的和意义
通过此系统,使人们即使了解到当下疫情状况,及时做好响应的预防。
1.3 系统设计思想
本系统后端通过Python爬取腾讯以及百度热搜网页的数据,将数据解析并且落盘到MySQL;前端通过Ajax发送请求,Python从MySQL获取数据并传输到前端,通过Echarts组件进行渲染的一系列过程。
1.4 系统开发环境
操作系统:win7
开发工具:Jypyter、Pycharm
服务器:虚拟机一台
数据库:Mysql-8.0.15-winx64
1.5 系统运行要求
后端爬取数据,通过Jupyter,可以及时看到运行结果,比较方便;此外数据量不大,使用MySQL进行存储;而此系统有网页交互,需要通过Pycharm进行编码。
第2章 需求分析
2.1 系统功能分析
通过爬虫,获取数据并解析,前端展现数据。
2.2 系统整体业务流程
![]()
第3章 总体设计
3.1 系统总体设计
疫情实时监控基于Python程序开发语言,主要分为前台和后台两个大模块。
前台模块:主要实现全国累计趋势、全国新增趋势、非湖北地区城市确诊TOP5、今日疫情热搜(词云图)、各项数据、中国地图疫情数据展示模块
后台模块:数据爬取及解析、数据存储、各个功能对应的实现逻辑
3.1.1 系统模块功能
通过分析可以得出系统模块功能分为全国累计趋势、全国新增趋势、非湖北地区城市确诊TOP5、今日疫情热搜(词云图)、各项数据、中国地图疫情数据展示模块
3.2 数据库设计概述
3.2.1 数据库选择
系统采用MySQL作为数据库。MySQL是一个关系型数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
3.2.2 数据库编码
数据库采用UTF-8编码格式。UTF-8是一种针对Unicode的可变长度字符编码,又称万国码。UTF-8用1到6个字节编码Unicode字符,用在网页上可以统一页面显示中文简体繁体及其他语言。
3.3 数据库详细设计
3.3.1 数据库物理结构设计
系统采用MySQL作为数据库,采用InnoDB作为存储引擎(适用于事务,锁机制),字符集为UTF-8
3.3.2 数据表的设计



第4章 详细设计
4.1 数据爬取
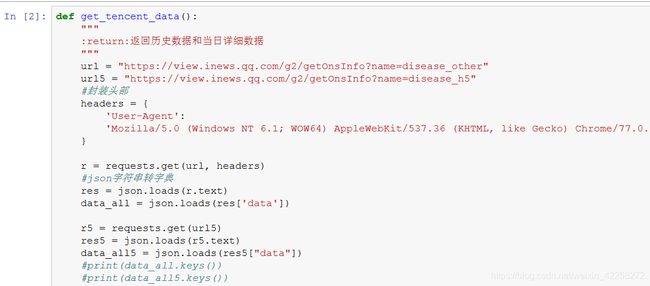
4.1.1 爬取腾讯疫情网页
url = “https://view.inews.qq.com/g2/getOnsInfo?name=disease_other”
url5 = https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5
代码讲解:
通过不同的url来获取数据,封装头部,将获得的数据转为字典格式(json.loads());
#历史数据
遍历chinaDayList(之前每天的数据),获取响应的内容封装到history;
遍历chinaDayAddList(日新增),如果某一天的数据有变,则通过update进行更新。
#详细数据
同理,遍历数据项,获取响应的数据进行封装到details
将history、details返回
代码如下:


4.1.2 爬取百度热搜页面
url=https://voice.baidu.com/act/virussearch/virussearch?from=osari_map&tab=0&infomore=1
代码讲解:
百度的数据页面使用动态渲染技术(js),通过普通爬取方式是爬取不到数据的,可以用selenium来爬取(from selenium.webdriver import Chrome,ChromeOptions)
设置浏览器的选项,之后进行get(url),通过页面组件的xpath(find_elements_by_xpath)进行获取,获取数据后遍历,添加到context中,返回context
代码如下:

4.2 数据存储(MySQL)
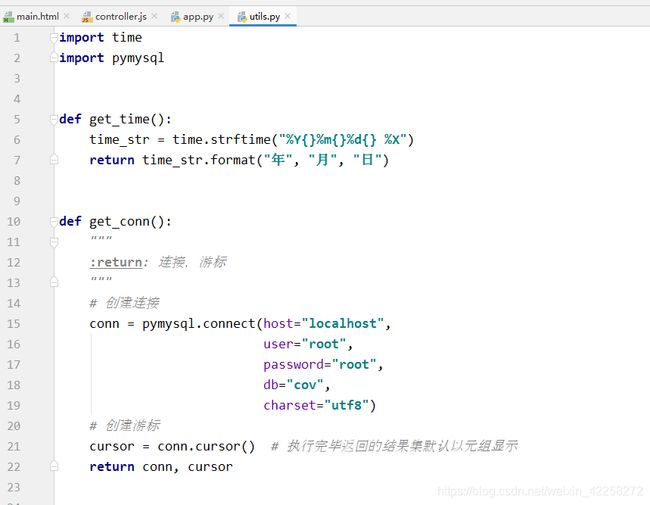
Python与MySQL连接,需要通过pymysql(import pymysql)
4.2.1 与数据库连接/关闭
代码讲解:设置连接数据库必要的属性,创建连接,建立游标,返回conn、cursor

4.2.2 腾讯数据存取
4.2.2.1 插入历史表数据
代码讲解:
创建与数据库的连接;通过4.1.1返回的history,遍历history每一项,执行对应的插入history表的sql语句,conn提交;执行完毕后执行close_conn关闭连接;中途有异常时traceback会打印(import trackback 进行导入)


4.2.2.2 更新历史表数据
代码讲解:
通过4.1.1返回的history,如果满足条件


4.2.2.3 更新细节表数据
代码讲解:
获取4.1.1返回的details数据,sql_query获取当前最大的时间戳,与传入的时间戳li[0][0]进行比较,如果一致则没必要去更新,如果不等则要进行更新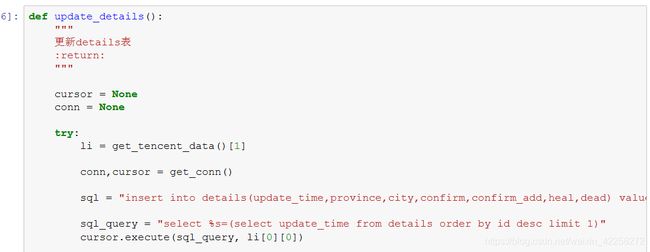

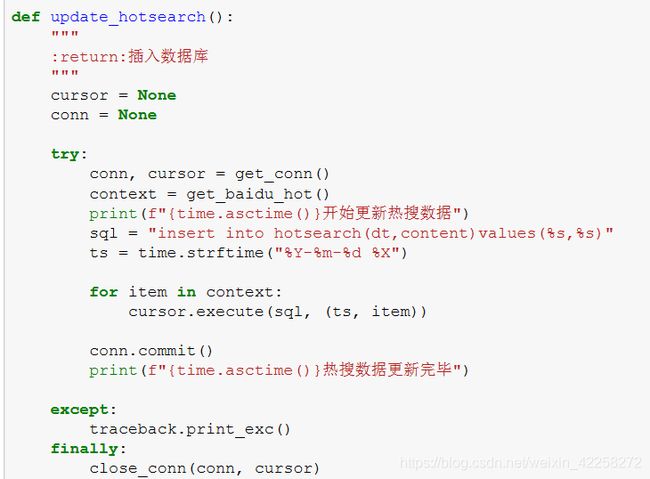
4.2.3 百度热搜数据存取
代码讲解:
通过4.1.2返回的百度热搜数据context,且当前的时间转换格式形成ts,通过插入语句sql插入到数据库hotsearch表
4.3 前台展示
代码讲解:main.html通过各个div以及各个js脚本进行展示,展示的数据封装在js脚本中


4.4 数据获取
以下是数据库—>前端页面的数据传送过程
4.4.1 获取数据库数据
通过业务需求,写出具体的sql语句实现响相应的功能。
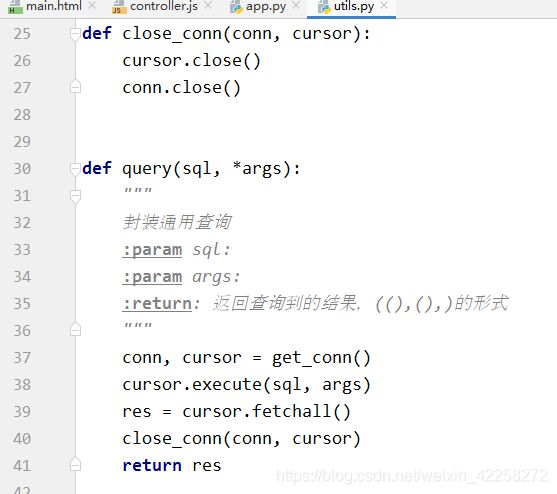



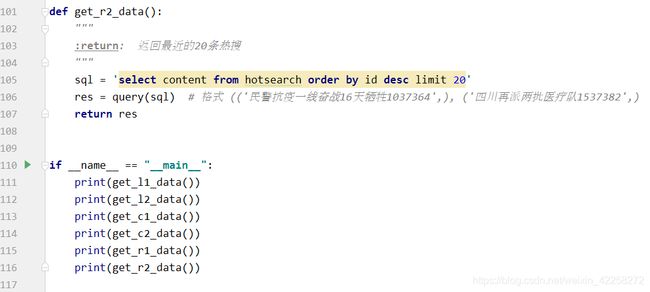
4.4.2 获取数据并解析
app.py通过调用utils.py(即4.4.1获取数据库数据的py)来获取数据,并且通过Python的jsonify解析数据,返回到前端
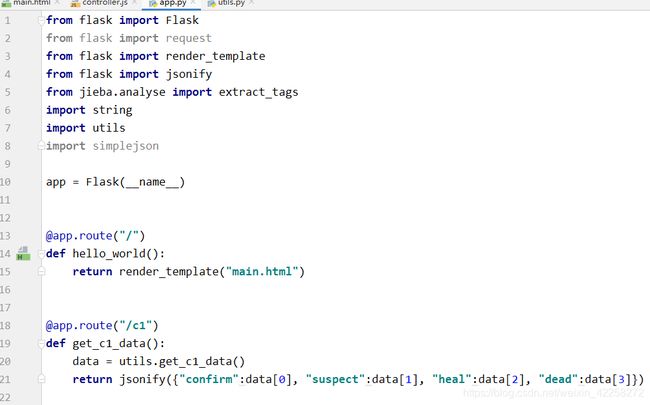
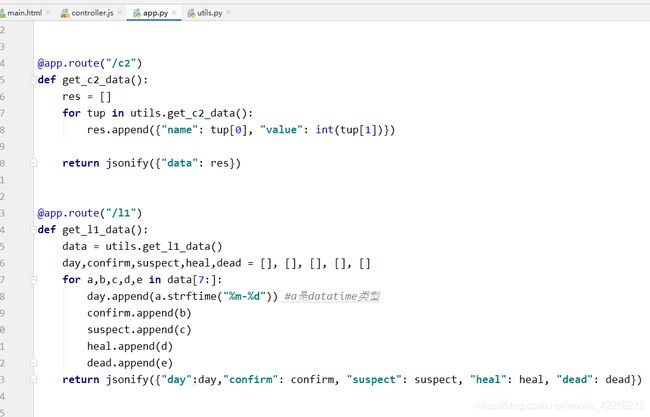
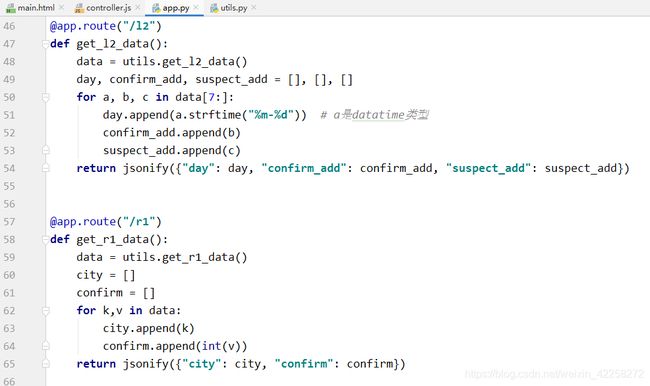

4.4.3 Ajax请求
代码讲解:
Ajax发起请求,设置不同的url以及超时时间,请求成功success或者失败error都有各自的函数;当成功的话,可以通过返回的data对前端的模块进行赋值(这里用到Echarts组件,Echart需要一个放图标的容器,如div,之后通过设置参数进行初始化,更改对应option里面的data,让图标变化)
调用不同的函数去获取数据,并设置不同的触发间隔(不同的时间段更新)


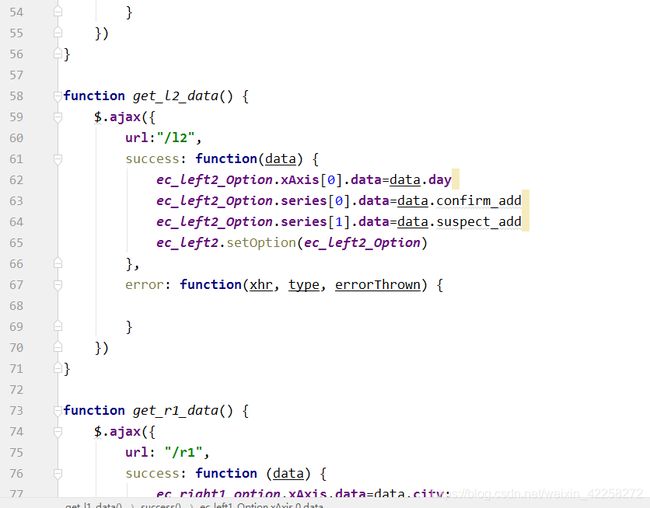


第5章 实验展示
第6章 系统测试
6.1 测试方案概述
测试环境: win7
测试平台:Jupyter、MySQL、Pycharm、Edge浏览器
测试功能:1、是否正确爬取到数据
2、是否正确落盘到数据库
3、是否正确获取数据库的数据
4、各个模块是否正常显示
6.2 测试计划与实施
6.2.1 是否正确爬取到数据

6.2.2 是否正确落盘到数据库
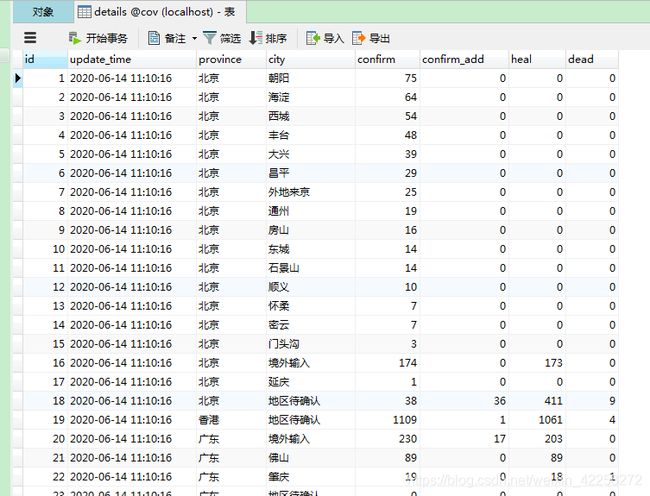
通过Navicat查看是否存在数据:
1/details表:
2/history表

3/hotsearch表
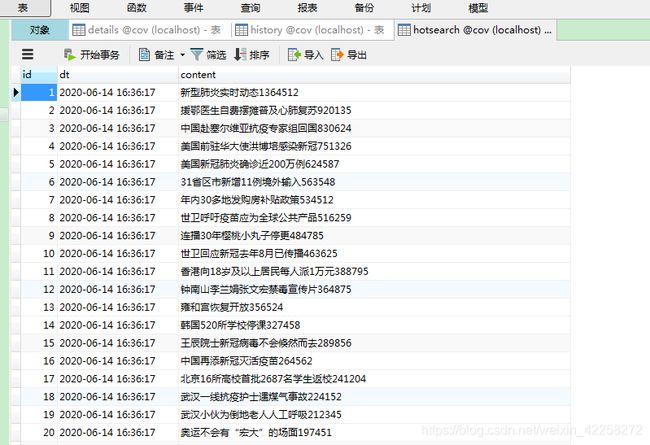
6.2.3 是否正确获取数据库的数据

6.2.4 各个模块是否正常显示

结论
通过本次实验,增强了python的语法使用,其次初步掌握爬虫的过程,并且明白了前后端数据交互的整个流程。在系统开发过程中遇到许多问题,通过不断查阅资料来解决,也认识到本系统仍有许多可以改进的地方,比如部分数目的ETL,通过清洗可以排除一些无效的信息,使得前台页面可以更加准确的展示等等。
参考文献
[1] Python基础教程
[2] Jupyter的基础使用
[3] Python与MySQL交互
[4] Echarts官网
致谢
学习语言的过程,单单学习语法是很枯燥的,最好的学习方式是以项目为导向进行学习,这样才能边在实操过程中掌握基础语法的使用,虽说不能面面俱到,但能完成工作即可。通过这次的实验我收获颇丰,希望以后可以更进一步。感谢老师的付出,谢谢老师!