算法(六)贪心
一、概述
1、概念
在每个决策点作出在当时看来最佳的选择,即总是遵循某种规则,做出局部最优的选择,以推导出全局最优解(局部最优解->全局最优解)
2、适用条件
- 贪心选择性质:所求问题的整体最优解,可以通过一系列局部最优的选择(贪心选择)来达到。
- 贪心选择可以依赖以往所做过的选择,但绝不依赖于将来所作的选择,也不依赖于子问题的解(所以叫贪心**,只看眼前,不管未来),是贪心法和动态规划法的主要区别**
- 贪心算法通常以自顶向下的方式进行,不断迭代多出贪心选择,每做一次贪心选择就将问题简化为规模更小的问题。从全局来看,贪心法解决问题的过程中没有回溯过程。(动态规划算法通常是以底向上的方式)
- 最优子结构性质:原问题包含了其子问题的最优解
3、解题思路
- 建立数学模型来描述最优化问题;
- 把求解的最优化问题转化为这样的形式:对其做出一次选择后,只剩下一个子问题需要求解;
- 证明做出贪心选择后:
- 原问题总是存在全局最优解,即贪心选择始终安全;
- 剩余子问题的局部最优解与贪心选择组合,即可得到原问题的全局最优解。
4、技巧
贪心算法解决的正确性虽然很多时候看起来是显而易见的,但是要严谨地证明算法能够得到最优解,并不是件容易的事。所以,很多时候,我们只需要多举几个例子,看一下贪心算法的解决方案是否真的能得到最优解就可以了。
简单的题多用排序
二、综合实例
1、简单排序
几道例题
https://www.luogu.com.cn/problem/P2945
https://www.luogu.com.cn/problem/P5602
1、排队打水问题
每个人的花费时间=每个人装满水桶的时间+等待时间。
显然越小的排在越前面(先接水)得出的结果越小
https://blog.csdn.net/ds19980228/article/details/82714478?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
#include
#include
#include
using namespace std;
int main() {
int a[1000],b[0100],n,r;
scanf("%d%d",&n,&r);
int i,sum=0;
int temp;
for(i=0; i 2、排队接水!
https://www.luogu.com.cn/problem/P1223
涉及到了多属性排序:重写Arrays.sort()方法
import java.io.*;
import java.util.*;
//外部类
class Person {
int index;
int time;
}
public class Main {
public static void main(String[] args) throws IOException {
StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
PrintWriter out = new PrintWriter(new OutputStreamWriter(System.out));
in.nextToken();
int n = (int)in.nval;
Person[] people = new Person[n];
for (int i = 0; i < n; i++) {
//记得创建对象!
people[i] = new Person();
people[i].index = i + 1;
in.nextToken();
people[i].time = (int)in.nval;
}
//重写,这里是重小到大
Arrays.sort(people, new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
if(o1.time == o2.time) return o1.index - o2.index;
else return o1.time - o2.time;
}
});
long sum = 0;
long t = 0;
for(int i = 0;i < n;i++) {
out.print(people[i].index);
if(i != n - 1) {
out.print(" ");
}
sum += t;
t += people[i].time;
}
out.println();
out.printf("%.2f",(sum * 1.0)/n);
out.close();
}
}
2、均分纸牌(NOIP2002)
https://blog.csdn.net/ds19980228/article/details/82714478?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
1.如果你想到把每堆牌的张数减去平均张数,题目就变成移动正数,加到负数中,使大家都变成0
2.正数可移,故负数也可移
#include
int n;
int a[105];
int main()
{
int i,j;
int aver = 0,step=0; //aver记录每堆纸牌的平均值 step记录移动次数
scanf("%d",&n);
for(i=0;i 3、Saruman’s Army(标记点问题)
#include
#include
#include
using namespace std;
int N,R;
int ans=0; //标记数
int point[1010];
int main()
{
int i,s,p;
scanf("%d",&N);
scanf("%d",&R);
for(i=0;i 4、Sleepy Cow Herding S??
https://www.luogu.com.cn/problem/P5541
三、背包问题
1、最优装载问题
有n个物体,第i个物体的重量为wi(wi为正整数)。选择尽量多的物体,使得总重量不超过C。
**优先取重量小的物体。**对n个物体按重量递增排序,依次选择每个物体直到装不下为止。
有时考虑条件可能需要转换后得出https://www.luogu.com.cn/problem/P2616
2、部分背包(分数背包)问题
有n个物体,第i个物体的重量为wi,价值为vi(wi, vi均为正整数)。在总重量不超过C的情况下让总价值尽量高。每一个物体都可以只取走一部分,价值和重量按比例计算。
优先取性价比高的物体。
四、区间问题
(一)不相交区间选择问题
1、概念
又称【区间调度问题】
2、解题思路
(1)构造区间
(2)右递增
(3)遍历取左侧大于等于当前最右侧的区间
3、例题
(1)工作选择
参与尽可能多的工作,如果选择了参与,那么自始至终都必须全程参与。此外,参与工作的时间段不能重叠
方法:在可选的工作中,每次都选取结束时间最早的工作(b递增)
https://blog.csdn.net/ds19980228/article/details/82714478?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
#include
#include
#include
using namespace std;
const int maxn=100005;
int N;
int ans=0;
struct Work //定义工作
{
int s; //开始时间
int t; //结束时间
} w[maxn];
bool cmp(struct Work w1,struct Work w2) //按工作结束时间递增排序
{
return (w1.tend) //若发现某项工作的开始时间比end晚
{
ans++; //则选择当前工作
end=w[j].t; //将这项工作的结束时间作为end
}
}
printf("%d\n",ans);
return 0;
}
(2)会场安排
https://www.cnblogs.com/acgoto/p/9824723.html
(二)区间选点问题
1、概念
2、解题思路
(1)构造区间
(1)先右递增,再左递减
(2)取未覆盖的第一个区间的最右点。
如下图,如果选灰色点,移动到黑色点更优。
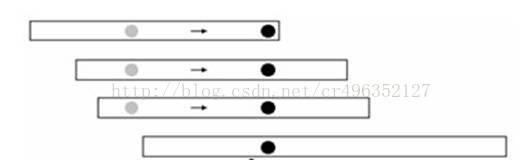
https://blog.csdn.net/ds19980228/article/details/82714478?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
3、例题
(1)找点
#include
#include
#include
#define maxn 10010
using namespace std;
int n;
int ans; //最少区间数量
struct Seg //定义区间
{
int a;
int b;
} s[maxn];
bool cmp(struct Seg s1,struct Seg s2) //自定义排序规则
{
if(s1.b!=s2.b)
return (s1.bs2.a);
}
int main()
{
int i,loc; //loc记录当前选择的区间终点
scanf("%d",&n);
for(i=0;iloc) //若发现后面有区间的起点比loc大
{
ans++; //则应再选一个点
loc=s[i].b; //并修改loc为新区间的终点
}
}
printf("%d\n",ans);
return 0;
}
(2)Radar Installation
(三)区间覆盖问题
1、概念
给定一个长度为m的区间**(连续的)**,再给出n条线段的起点和终点(注意这里是闭区间),求最少使用多少条线段可以将整个区间完全覆盖。(给定一条指定的线段[s,t],数轴上有n个闭区间[ai,bi],求最少使用多少区间可以覆盖整条线段。)
2、解题思路
(1)构造区间
(2)先左递增,再右递增
(2)设置一个变量表示已覆盖到的区间右端点,在剩下的线段中找出所有左端点小于等于当前已覆盖到的区间右端点的线段(使区间连续),选择右端点最大并且大于当前已覆盖到的区间右端点(否则题目无解),重复以上操作直至覆盖整个区间;
3、例题
(1)NYOJ #12 喷水装置(二)
https://www.cnblogs.com/acgoto/p/9824723.html
#include
using namespace std;
const int maxn=10005;
int t,n,k,cnt,pos,beg;double w,h,lb,xi,ri,maxv;pair itv[maxn];bool flag;
int main(){
while(cin>>t){
while(t--){
cin>>n>>w>>h;h/=2.0;pos=cnt=0;//h取一半
//构造得到“n条线段的起点和终点”!!!
for(int i=0;i>xi>>ri;
//ri0){cout<<0<lb)cnt++,lb=maxv;//beg=k;不用吧
//否则说明不能覆盖整个区间,直接退出,输出0
else {flag=true;break;}
}
if(flag)cout<<0< (四)其他
(1)铺设道路
每次可选一段区间进行操作
https://www.luogu.com.cn/problem/P5019
类似的还有https://www.luogu.com.cn/problem/P1969 https://www.luogu.com.cn/problem/P3078
import java.io.*;
import java.util.*;
public class Main {
public static void main(String[] args) throws IOException {
StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
PrintWriter out = new PrintWriter(new OutputStreamWriter(System.out));
int result = 0;
in.nextToken();
int n = (int)in.nval;
int[] s = new int[n];
for(int i = 0;i < n;i++) {
in.nextToken();
s[i] = (int)in.nval;
}
for(int i = 1;i < n;i++) {
if(s[i] > s[i - 1]) {
result += s[i] - s[i - 1];
}
}
out.print(result + s[0]);
out.close();
}
}
(2)泥泞路
区间覆盖(所要覆盖的大区间是分散的……)
import java.io.*;
import java.util.*;
class Node{
int a;
int b;
}
public class Main {
public static void main(String[] args) throws IOException {
StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
PrintWriter out = new PrintWriter(new OutputStreamWriter(System.out));
in.nextToken();
int n = (int)in.nval;
in.nextToken();
int l = (int)in.nval;
Node[] s = new Node[n];
for(int i = 0;i < n;i++) {
s[i] = new Node();
in.nextToken();
s[i].a = (int)in.nval;
in.nextToken();
s[i].b = (int)in.nval;
}
Arrays.sort(s,new Comparator<Node>() {
@Override
public int compare(Node n1, Node n2) {
// TODO Auto-generated method stub
return n1.a - n2.a;
}
});
int start = s[0].a,result = 0;
for(int i = 0;i < n;i++) {
start = Math.max(start,s[i].a);
while(start < s[i].b) {
start += l;
result++;
}
}
out.print(result);
out.close();
}
}
(3)鸿山洞的灯
每段距离小于dist的中间点去掉
import java.io.*;
import java.util.*;
public class Main {
public static void main(String[] args) throws IOException {
StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
PrintWriter out = new PrintWriter(new OutputStreamWriter(System.out));
in.nextToken();
int n = (int)in.nval;
in.nextToken();
int dist = (int)in.nval;
int[] s = new int[n];
for(int i = 0;i < n;i++) {
in.nextToken();
s[i] = (int)in.nval;
}
Arrays.sort(s);
int result = 0;
//对中间的点进行判断,看是否用除去
for(int i = 1;i < n - 1;i++) {
if(s[i + 1] - s[i - 1] <= dist) {
//除去该点,并使前面的点后移以便后续计算
s[i] = s[i - 1];
result++;
}
}
out.print(result);
out.close();
}
}
(4)公路维修问题
切分段数,使距离最小:去掉相距最远的几个点距离
import java.io.*;
import java.util.*;
public class Main {
public static void main(String[] args) throws IOException {
StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
PrintWriter out = new PrintWriter(new OutputStreamWriter(System.out));
in.nextToken();
int n = (int)in.nval;
in.nextToken();
int m = (int)in.nval;
int[] s = new int[n];
int[] j = new int[n - 1];
for(int i = 0;i < n;i++) {
in.nextToken();
s[i] = (int)in.nval;
}
for(int i = 1;i < n;i++) {
j[i - 1] = s[i] - s[i - 1];
}
Arrays.sort(j);
//每段距离均要加一,m段则要加上m个1
int result = m;
for(int i = 0;i < n - m ;i++) {
result += j[i];
}
out.print(result);
out.close();
}
}
五、字典序问题
1、最大整数(拼数问题)
问题:设有n个正整数(n≤20),将它们联接成一排,组成一个最大的多位整数。
方法:按字典序从大到小输出即可
(字符串排序的规则:首先按字典序,然后看串长度。如7>414321>4143>32)
问题:一个高精度的正整数n(≤240位),去掉其中任意s个数字后剩下的数字按原左右次序将组成一个新的正整数 方法: https://blog.csdn.net/ds19980228/article/details/82714478?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task 问题:构造**字典序尽可能小(小的在前)**的字符串T 方法: https://blog.csdn.net/weixin_41676901/article/details/80615415 https://blog.csdn.net/every__day/article/details/87252852 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wyLziFXk-1595651515299)(C:\Users\ddjj6\AppData\Roaming\Typora\typora-user-images\1582469479796.png)] 我们每个字符看作一个节点,并且附带把频率放到**优先级队列(频率从小到大,左边出队,取两最小的)**中。我们从队列中取出频率最小的两个节点A、B,然后新那一个节点C,把频率设置为两个节点的频率之和,并把这个新节点C作为节点A、B的父节点。最后两把C节点放到优先级队列中。重复这个过程,直到队列中只剩一个数据(这个结果往往是要求的最小解)。 逻辑上:哈夫曼树 实际操作:优先队列 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0gwPkE6j-1595651515307)(C:\Users\ddjj6\AppData\Roaming\Typora\typora-user-images\1582469551030.png)] 现在,给每一条边画一个权值,指向左子节点的边我们统统标记为0,指向右子节点的过,我们统统标记为1,那从根节点到叶子节点的路径就是叶子节点对应字符的霍夫曼编码。 这里每次取两最大的处理后再放回去,最后队列剩下的最后元素就是最小的 https://blog.csdn.net/jianglw1/article/details/83037103 森林? https://blog.csdn.net/Mr_Treeeee/article/details/80255022?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task#include 2、删数问题
#include 3、字典序最小问题
#include六、哈夫曼编码思想
1、贪心 哈夫曼思想
#include 2、FZU 2219 StarCraft???
#include