想做好一对一直播开发就要先从音视频基础技术开始
想做好一对一直播开发就要先从音视频基础技术开始
这是音视频技术从零开始学习笔记的第一篇,从音频技术相关的概念开始,本篇不涉及任何编程相关内容。个人认为,概念理解清楚对以后编程模块的边界、职责划分以及该使用哪些工具有很大的帮助。

图1-音频技术核心概念
采样
模拟信号(连续信号)是连续的,意味着不会失真(音质好),比如磁带、唱片中就通过物理介质(通过唱片表面的起伏跌宕,或者是磁带上的磁粉引起的磁场强度来表示音箱上振膜的即时位置)保存着音频的模拟信号。
我们都知道唱片和磁带已经逐渐离开人们的视野,就是因为通过物理手段无法长久的保存音频信号,唱片会磨损,磁带会老化,那用什么方法能够长久的保存音频信息呢?
目前,使用最多的方法就是通过数字来保存音频,那么又如何将音频转为数字呢?首先先通过图中「采样」手段,将模拟信号转为离散信号,离散信号可以理解为不连续信号,把一段连续函数按照一定规则断开。

图2-采样信号 原图链接
此图为CD标准的采样信号图,图中的「采样率44.1Khz」就是断开函数的规则,每 1s 将一段波分为 44100 个矩形,经过采样,得到了一个有一堆柱形图组成的图形(离散信号)
为什么音频的采样率是 44.1Khz 呢?对于高质量的音频(人耳能够听到的频率范围是 20hz-20Khz),根据采样定理,按比人能听到的最大频率的2倍进行采样可以保证声音在被数字化处理后,还能有质量保障
量化

图3-量化(信号处理)
经过采样后,我们发现图中的纵坐标是没有值的,无法表示每段样本的数字大小,这时候就需要引入量化的概念。通俗易懂地讲「量化」就是在沿水平方向再将信号图按照一定数字范围切断,保证每段样本能用数字描述。这个数字的最终物理意义是反应在音响振膜位置,比如用[0-10万]进行量化,最终反应在振膜的位置就是 0-10万。
那么CD的量化标准是什么呢?采用16bit(short),也就是2的16次方,总共65536,然后为了由于振膜是可以发生正向和负向位移,所以用[-32767,32768]进行量化。
所以图中虚线范围就代表了量化的数字范围,最终的红色曲线就是量化的结果,数字信号
编码
经过量化后,每一个采样都是一个数字,那这么多的数字该如何存储呢?这就需要第三个概念:「编码」,所谓编码,就是按照一定的格式记录采样和量化后的数据,比如顺序存储或压缩存储等。
这里涉及很多种格式,通常所说的音频的裸数据格式就是脉冲编码调制数据,简称 PCM (Pulse Code Modulation)。描述一段 PCM 通常需要以下三个概念
- 量化格式(SampleFormat)
- 采样率(SampleRate)
- 声道数(Channel)
还以CD标准为例,量化格式 16bit,采样率 44100,声道数 2。
这里对声道概念做一个补充,平时所谓的双声道、单声道其实可以理解为需要记录几个信号,比如磁带,双声道就是同一时刻记录两个轨道的信息,一个负责记录左耳机振膜位置,一个负责记录右耳机振膜位置,以此类推,多个声道也是类似
上述信息就描述了CD的音质,对于声音格式来说,还有另一个概念用来描述它的大小,称为数据比特率(bitRate),即 1s 内的比特数目,用于衡量音频数据单位时间内的容量大小,那么比特率如何计算?
单位为千比特每秒kbps(kb per second)。
比如对于CD音质, 那么,一分钟里,CD音质数据需要占多大存储空间呢?
所以一段1分钟的音频经过采样、量化、编码后可以得到一个大约10MB裸数据,成功地将音频的模拟信号转为数字信号,并存储下来。
音频压缩编码
上面说到1分钟的CD音质数据的存储空间大于为 10MB,这对于光盘磁盘存储来说可接受,但对于网络传输肯定是无法接受的。所以就需要「压缩编码」出面解决问题
所谓音频编码主要指音频压缩技术,压缩通常又被分为有损和无损两种,但事实上,任何音频编码方式相对于最真实的自然声音信号,都是有损的压缩。从前面说到的采样、量化、编码中不难理解,我们把一条光滑的音频信号曲线分割成了许多数据块,然后对数据进行二进制编码,过程中其实就已经损失了一部分数据了,所以再次进行压缩也只能是尽可能的接近经过PCM编码后的音频裸数据。
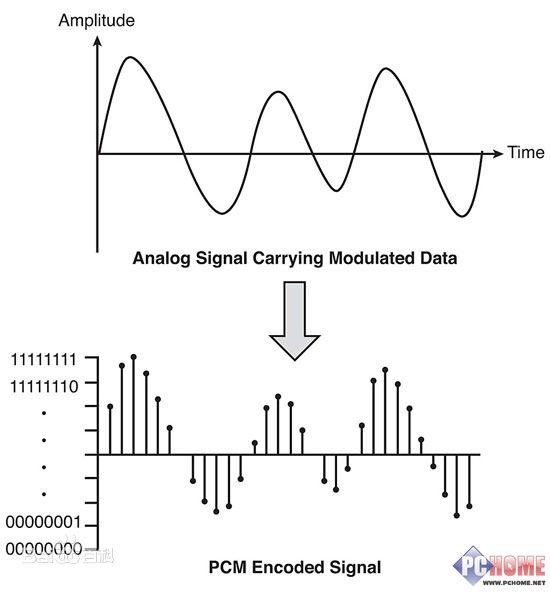
图4-PCM编码 原图链接
既然压缩是为了减小编码后的数据存储空间,那么就应该去掉音频的“冗余信息”,从以下两个方面去衡量哪些数据是冗余的
- 之前提到过,人耳所能察觉的声音信号的频率范围为20Hz-20KHz,除此之外的其它频率人耳无法察觉,都可视为冗余信号
- 当一个强音频信号和一个弱音频信号同时存在时,弱信号会被强信号掩蔽,可视为冗余
其中第二点涉及另两个概念「频谱掩蔽效应」和「时域掩蔽效应」,名字看起来高深莫测,其实不难理解。

图5-频谱掩蔽效应 原图链接
「频谱掩蔽效应」一个音频信号被人耳听到是有一个阈值,阈值越小越容易被人听到,如图所示,虚线是随声音频率增大反应的阈值曲线,在 2-5kHz范围内,阈值很低,是人耳对声音最敏感的频率。现在假设有一个 60dB-0.2kHz 的强音信号出现时,阈值曲线会有所改变(图中实线部分),0.1-0.5kHz 频率的阈值被明显抬高,图中大概40dB-0.17kHz 左右的信号和 30dB-0.48kHz左右的信号都会被掩蔽。所以在0.1kHz-0.5kHz范围内,只能听到 65dp-0.2kHz 的声音,其余信号可视为冗余。

图6-时域掩蔽效应 原图链接
「时域掩蔽效应」是强信号和弱信号在时间维度发生的掩蔽,分为
- 前掩蔽,人在听到强信号之前,一些弱信号会被掩蔽
- 同时掩蔽,强信号会掩蔽同时发生的弱信号
- 后掩蔽,强信号消失后,需要经过一段时间后,才能重新听到弱信号
在这过程中被掩蔽的信号被视为冗余
几种音频压缩编码简介
| 编码 | 实现简介 | 特点 | 适用场景 |
|---|---|---|---|
| WAV | 无损压缩,其中一种实现方式是在 PCM 数据格式前加上 44 字节,分别描述采样率、声道数、数据格式等信息。 | 音质非常好,大量软件都支持 | 多媒体开发的中间文件、保存音乐和音效 |
| MP3 | 具有不错的压缩比,使用 LAME 编码(MP3 编码格式的一种实现)的中高码率的 MP3 文件 | 音质在 128Kbit/s 以上表现还不错,压缩比比较高,大量软硬件都支持 | 高比特率下对兼容性有要求的音乐鉴赏 |
| AAC | 新一代有损压缩技术,通过一些附加的编码技术(PS、SBR 等),衍生出了 LC-AAC、HE-AAC、HE-AAC v2三种主要编码格式 | 小于 128Kbit/s 表现优异,多用于视频中的音频编码 | 128Kbit/s 一下的音频编码,多用于视频中的音频编码 |
| Ogg | 一种非常有潜力的编码,各种码率下都有比较优秀的表现,尤其是低码率场景下。可以在低码率的场景下仍然保持不错的音质,但目前软件硬件支持情况较差 | 可用比 MP3 更小的码率实现比 MP3 更好的音质,但兼容性不好 | 语音聊天的音频消息场景 |
1.压缩比,压缩后大小/原大小,通常小于 1,越小表示压缩的越狠
2.“码率”是比特率是俗称
3.表格总结于《音视频开发指南》,其中一些细节有兴趣的同学可以再深入查阅,本文不再深入研究