PyTorch torch.optim.lr_scheduler 学习率 - LambdaLR;StepLR;MultiStepLR;ExponentialLR
PyTorch学习率调整策略通过torch.optim.lr_scheduler接口实现。PyTorch提供的学习率调整策略分为三大类,分别是
- 有序调整:等间隔调整(Step),按需调整学习率(MultiStep),指数衰减调整(Exponential)和余弦退火CosineAnnealing。
- 自适应调整:自适应调整学习率 ReduceLROnPlateau。
- 自定义调整:自定义调整学习率 LambdaLR。
引用: PyTorch学习之六个学习率调整策略
LambdaLR 自定义调整
torch.optim.lr_scheduler.ReduceLROnPlateau 能够根据自己的定义调节LR
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1)
| 参数 | 含义 |
|---|---|
| o p t i m i z e r optimizer optimizer | 优化器 |
| l r — l a m b d a lr_—{lambda} lr—lambda | 为optimizer.param_groups中的每个组计算一个乘法因子。 |
| l a s t — e p o c h ( i n t ) last_—epoch (int) last—epoch(int) | 是从last_start开始后已经记录了多少个epoch, Default: -1. |
# Assuming optimizer has two groups.
lambda1 = lambda epoch: epoch // 30
lambda2 = lambda epoch: 0.95 ** epoch
scheduler = LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])
for epoch in range(100):
train(...)
validate(...)
scheduler.step()
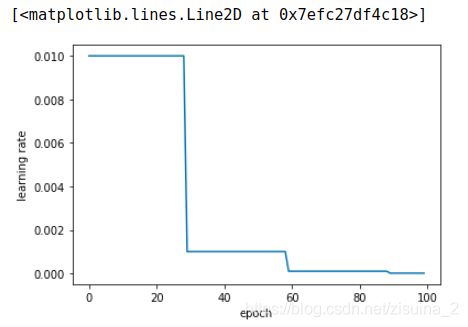
StepLR - 有序调整
class torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
功能: 等间隔调整学习率,调整倍数为gamma倍,调整间隔为step_size。间隔单位是step。需要注意的是,step通常是指epoch,不要弄成iteration了。
参数:
| 参数 | 含义 |
|---|---|
| o p t i m i z e r optimizer optimizer | 优化器 |
| s t e p − s i z e ( i n t ) step_-size(int) step−size(int) | 学习率下降间隔数,若为30,则会在30、60、90…个step时,将学习率调整为lr*gamm |
| g a m m a ( f l o a t ) gamma(float) gamma(float) | 学习率调整倍数,默认为0.1倍,即下降10倍。 |
| l a s t — e p o c h ( i n t ) last_—epoch (int) last—epoch(int) | 是从last_start开始后已经记录了多少个epoch, Default: -1. |
官方使用方法
>>> # Assuming optimizer uses lr = 0.05 for all groups
>>> # lr = 0.05 if epoch < 30
>>> # lr = 0.005 if 30 <= epoch < 60
>>> # lr = 0.0005 if 60 <= epoch < 90
>>> # ...
>>> scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
>>> for epoch in range(100):
>>> train(...)
>>> validate(...)
>>> scheduler.step()
学习率展示案例
import torch
import torch.optim as optim
from torch.optim import lr_scheduler
from torchvision.models import AlexNet
import matplotlib.pyplot as plt
model = AlexNet(num_classes=2)
optimizer = optim.SGD(params=model.parameters(), lr=0.01)
# lr_scheduler.StepLR()
# Assuming optimizer uses lr = 0.05 for all groups
# lr = 0.05 if epoch < 30
# lr = 0.005 if 30 <= epoch < 60
# lr = 0.0005 if 60 <= epoch < 90
scheduler = lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
plt.figure()
x = list(range(100))
y = []
for epoch in range(100):
scheduler.step()
lr = scheduler.get_lr()
print(epoch, scheduler.get_lr()[0])
y.append(scheduler.get_lr()[0])
plt.xlabel("epoch")
plt.ylabel("learning rate")
plt.plot(x, y)
每30epoch进行一次刷新通过
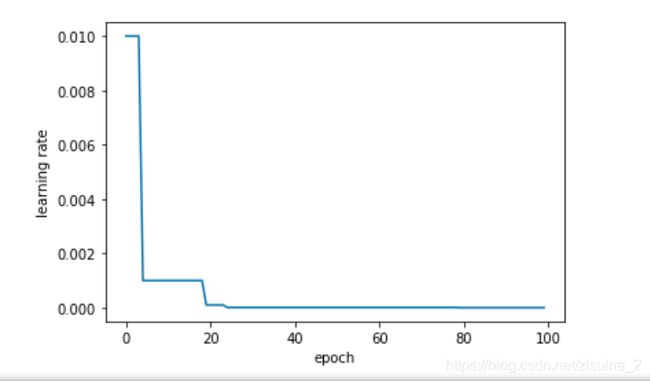
MultiStepLR - 有序调整
StepLR的区别是,调节的epoch是自己定义,无须一定是【30, 60, 90】 这种等差数列;
请注意,这种衰减是由外部的设置来更改的。 当last_epoch=-1时,将初始LR设置为LR。
torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)
你看就多了milestone
参数:
| 参数 | 含义 |
|---|---|
| o p t i m i z e r ( O p t i m i z e r ) optimizer(Optimizer) optimizer(Optimizer) | 优化器 |
| m i l e s t o n e s ( l i s t ) milestones (list) milestones(list) | lr改变时的epoch数目,一定是上升的,如【30,80】,就在第30个epoch进行改变,和在第80个epcho进行改变 |
| g a m m a ( f l o a t ) gamma(float) gamma(float) | 学习率调整倍数,默认为0.1倍,即下降10倍。 |
| l a s t — e p o c h ( i n t ) last_—epoch (int) last—epoch(int) | 是从last_start开始后已经记录了多少个epoch, Default: -1. |
官方使用方法
>>> # Assuming optimizer uses lr = 0.05 for all groups
>>> # lr = 0.05 if epoch < 30
>>> # lr = 0.005 if 30 <= epoch < 80
>>> # lr = 0.0005 if epoch >= 80
>>> scheduler = MultiStepLR(optimizer, milestones=[30,80], gamma=0.1)
>>> for epoch in range(100):
>>> train(...)
>>> validate(...)
>>> scheduler.step()
学习率展示案例
model = AlexNet(num_classes=2)
optimizer = optim.SGD(params = model.parameters(), lr=0.01)
#在指定的epoch值,如[5,20,25,80]处对学习率进行衰减,lr = lr * gamma
scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=[5,20,25,80], gamma=0.1)
plt.figure()
x = list(range(100))
y = []
for epoch in range(100):
scheduler.step()
lr = scheduler.get_lr()
print(epoch, scheduler.get_lr()[0])
y.append(scheduler.get_lr()[0])
plt.xlabel("epoch")
plt.ylabel("learning rate")
plt.plot(x,y)
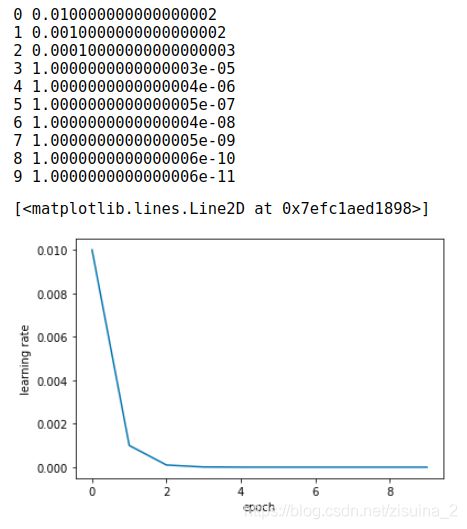
ExponentialLR - 指数形式增长 - 有序调整
按次方的形式来减少;
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1)
| 参数 | 含义 |
|---|---|
| o p t i m i z e r ( O p t i m i z e r ) optimizer(Optimizer) optimizer(Optimizer) | 优化器 |
| g a m m a ( f l o a t ) gamma(float) gamma(float) | 学习速率衰减的乘法因子。。 |
| l a s t — e p o c h ( i n t ) last_—epoch (int) last—epoch(int) | 是从last_start开始后已经记录了多少个epoch, Default: -1. |
官方使用方法
学习率展示案例
import torch
import torch.optim as optim
from torch.optim import lr_scheduler
from torchvision.models import AlexNet
import matplotlib.pyplot as plt
model = AlexNet(num_classes=2)
optimizer = optim.SGD(params = model.parameters(), lr=0.1)
#即每个epoch都衰减lr = lr * gamma,即进行指数衰减
scheduler = lr_scheduler.ExponentialLR(optimizer, gamma=0.1)
plt.figure()
x = list(range(10))
y = []
for epoch in range(10):
scheduler.step()
lr = scheduler.get_lr()
print(epoch, scheduler.get_lr()[0])
y.append(scheduler.get_lr()[0])
plt.xlabel("epoch")
plt.ylabel("learning rate")
plt.plot(x,y)
结果