Python带你看文献—xpath抓取知网文献!
在做学术的道路上,陪伴我们的不是对象(可能没有),不是家人(可能不在身边),甚至不是头发(日减稀疏),始终不离不弃的肯定是浩如烟海的论文。查阅文献常用的网站当属知网,为了实现快速翻阅、应用有类似纸质书体验的效果,我们今天就用Python来翻一翻知网上顶级期刊的文献目录。
一、案例简介
我们进入中国知网网站,点击出版物检索,选择期刊导航,输入《会计研究》。

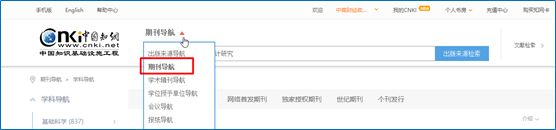
就进入了目标网址:https://navi.cnki.net/knavi/JournalDetail?pcode=CJFD&pykm=KJYJ。我们的目标是爬取2018年全年的文章题目和作者,对于没有作者的文章题目,如征文启事,则予以删除。我们先对单期期刊进行处理,再将其扩展到12期期刊。

在做学术的道路上,陪伴我们的不是对象(可能没有),不是家人(可能不在身边),甚至不是头发(日减稀疏),始终不离不弃的肯定是浩如烟海的论文。查阅文献常用的网站当属知网,为了实现快速翻阅、应用有类似纸质书体验的效果,我们今天就用Python来翻一翻知网上顶级期刊的文献目录。
一、案例简介
我们进入中国知网网站,点击出版物检索,选择期刊导航,输入《会计研究》。


就进入了目标网址:https://navi.cnki.net/knavi/JournalDetail?pcode=CJFD&pykm=KJYJ。我们的目标是爬取2018年全年的文章题目和作者,对于没有作者的文章题目,如征文启事,则予以删除。我们先对单期期刊进行处理,再将其扩展到12期期刊。

二、案例实操
(一)单个期刊
我们打开开发者模式,选择network,在name中寻找到网页信息,发现其网页获取方式是post,接着我们模拟人工浏览网页的行为写入headers对应的信息:url,request headers和querystring parameters。

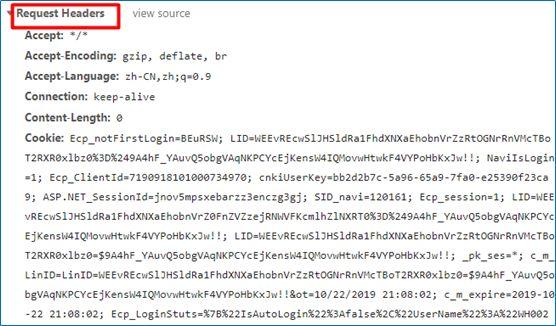
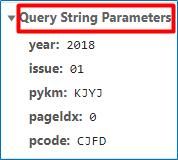
import requests #引入requests库爬取网页代码import json #引入json库处理data列表中的内容 url='https://navi.cnki.net/knavi/JournalDetail/GetArticleList?year=2018&issue=01&pykm=KJYJ&pageIdx=0&pcode=CJFD' headers={ 'Accept': '*/*', 'Accept-Encoding':'gzip, deflate, br', 'Accept-Language':'zh-CN,zh;q=0.9', 'Connection':'keep-alive', 'Content-Length':'0', 'Cookie':'Ecp_notFirstLogin=lGQkVH; Ecp_ClientId=7190918101000734970;cnkiUserKey=bb2d2b7c-5a96-65a9-7fa0-e25390f23ca9;LID=WEEvREcwSlJHSldRa1FhdXNXaEhobnVrZ0FnZVZzejRNWVFKcmlhZlNXRT0=$9A4hF_YAuvQ5obgVAqNKPCYcEjKensW4IQMovwHtwkF4VYPoHbKxJw!!;ASP.NET_SessionId=jnov5mpsxebarzz3enczg3gj; SID_navi=120161;c_m_LinID=LinID=WEEvREcwSlJHSldRa1FhdXNXaEhobnVrZ0FnZVZzejRNWVFKcmlhZlNXRT0=$9A4hF_YAuvQ5obgVAqNKPCYcEjKensW4IQMovwHtwkF4VYPoHbKxJw!!&ot=10/22/201919:34:18; c_m_expire=2019-10-22 19:34:18; Ecp_session=1; Ecp_LoginStuts=%7B%22IsAutoLogin%22%3Afalse%2C%22UserName%22%3A%22WH0023%22%2C%22ShowName%22%3A%22%25E4%25B8%25AD%25E5%258D%2597%25E8%25B4%25A2%25E7%25BB%258F%25E6%2594%25BF%25E6%25B3%2595%25E5%25A4%25A7%25E5%25AD%25A6%22%2C%22UserType%22%3A%22bk%22%2C%22r%22%3A%22lGQkVH%22%7D;Ecp_notFirstLogin=lGQkVH;LID=WEEvREcwSlJHSldRa1FhdXNXaEhobnVrZ0FnZVZzejRNWVFKcmlhZlNXRT0%3D%249A4hF_YAuvQ5obgVAqNKPCYcEjKensW4IQMovwHtwkF4VYPoHbKxJw!!;NaviIsLogin=1; _pk_ses=*', 'Host':'navi.cnki.net', 'Origin':'https://navi.cnki.net', 'Referer':'https://navi.cnki.net/knavi/JournalDetail?pcode=CJFD&pykm=KJYJ', 'Sec-Fetch-Mode':'cors', 'Sec-Fetch-Site':'same-origin', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, likeGecko) Chrome/75.0.3770.100 Safari/537.36', 'X-Requested-With':'XMLHttpRequest' }data={ 'year': '2018', 'issue': '01', 'pykm': 'KJYJ', 'pageIdx': '0', 'pcode': 'CJFD' }html=requests.post(url,headers=headers,data=json.dumps(data))
结果为:
说明网页爬取成功。至此我们就把2018年第一期期刊的网页源代码拿到了,接下来,使用xpath解析,得到目标信息。
from lxml import etree #引入lxml库totitlename=[] #首先定义空列表以盛放结果信息toauthor=[] tree=etree.HTML(html.text) #使用xpath进行解析titlename=tree.xpath("/html/body//span[@class='name']/a/text()")#得到这一节点对应的文本内容即为文章题目author=tree.xpath("/html/body//span[@class='author']/text()")#得到这一节点对应的文本内容即为作者totitlename.extend(titlename[0:len(author)]) #没有作者的文章题目,如征文启事,不保留toauthor.extend(author)print(totitlename)print(toauthor)
结果为:

至此我们成功得到了2018年第一期期刊所有的文章题目和作者。
(二)12期期刊
接下来,对于12期期刊,我们将用于单个期刊的程序封装进一个循环。其中关于f-string的用法参见往期推文《格式化字符串方法的比较》。
import requestsfrom lxml import etreeimport jsonimport re totitlename=[]toauthor=[]for issue in range(1,13): url=f'https://navi.cnki.net/knavi/JournalDetail/GetArticleList?year=2018&issue={issue:0>2d}&pykm=KJYJ&pageIdx=0&pcode=CJFD' #使用f-string实现{}内依次为两位数字01-12 headers={ 'Accept':'*/*', 'Accept-Encoding':'gzip, deflate, br', 'Accept-Language':'zh-CN,zh;q=0.9', 'Connection':'keep-alive', 'Content-Length':'0', 'Cookie':'Ecp_notFirstLogin=lGQkVH; Ecp_ClientId=7190918101000734970;cnkiUserKey=bb2d2b7c-5a96-65a9-7fa0-e25390f23ca9;LID=WEEvREcwSlJHSldRa1FhdXNXaEhobnVrZ0FnZVZzejRNWVFKcmlhZlNXRT0=$9A4hF_YAuvQ5obgVAqNKPCYcEjKensW4IQMovwHtwkF4VYPoHbKxJw!!;ASP.NET_SessionId=jnov5mpsxebarzz3enczg3gj; SID_navi=120161;c_m_LinID=LinID=WEEvREcwSlJHSldRa1FhdXNXaEhobnVrZ0FnZVZzejRNWVFKcmlhZlNXRT0=$9A4hF_YAuvQ5obgVAqNKPCYcEjKensW4IQMovwHtwkF4VYPoHbKxJw!!&ot=10/22/201919:34:18; c_m_expire=2019-10-22 19:34:18; Ecp_session=1;Ecp_LoginStuts=%7B%22IsAutoLogin%22%3Afalse%2C%22UserName%22%3A%22WH0023%22%2C%22ShowName%22%3A%22%25E4%25B8%25AD%25E5%258D%2597%25E8%25B4%25A2%25E7%25BB%258F%25E6%2594%25BF%25E6%25B3%2595%25E5%25A4%25A7%25E5%25AD%25A6%22%2C%22UserType%22%3A%22bk%22%2C%22r%22%3A%22lGQkVH%22%7D;Ecp_notFirstLogin=lGQkVH;LID=WEEvREcwSlJHSldRa1FhdXNXaEhobnVrZ0FnZVZzejRNWVFKcmlhZlNXRT0%3D%249A4hF_YAuvQ5obgVAqNKPCYcEjKensW4IQMovwHtwkF4VYPoHbKxJw!!;NaviIsLogin=1; _pk_ses=*', 'Host':'navi.cnki.net', 'Origin':'https://navi.cnki.net', 'Referer': 'https://navi.cnki.net/knavi/JournalDetail?pcode=CJFD&pykm=KJYJ', 'Sec-Fetch-Mode':'cors', 'Sec-Fetch-Site':'same-origin', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, likeGecko) Chrome/75.0.3770.100 Safari/537.36', 'X-Requested-With':'XMLHttpRequest' } data={ 'year':'2018', 'issue':f'{issue:0>2d}', 'pykm':'KJYJ', 'pageIdx':'0', 'pcode':'CJFD' } html=requests.post(url,headers=headers,data=json.dumps(data)) tree=etree.HTML(html.text) titlename=tree.xpath("/html/body//span[@class='name']/a/text()") author=tree.xpath("/html/body//span[@class='author']/text()") totitlename.extend(titlename[0:len(author)])#没有作者的文章题目,如征文启事,不保留 toauthor.extend(author)print(len(totitlename))print(len(toauthor))
结果为:


说明我们一共抓取到了157条信息。接下来我们将结果写入文件,保存下来。其中关于re.sub的使用参见往期推文《妙用正则表达式--Python中的re模块》。
with open('g:\\会计研究.csv','w',encoding='gb18030') as f: for i in range(0,len(toauthor)): f.write(totitlename[i].strip()+','+re.sub(";",",",toauthor[i])+'\n') #strip函数把文章题目中的空白字符删掉,re.sub把作者中的分号替换为逗号。写入文章题目+作者姓名
结果如下:
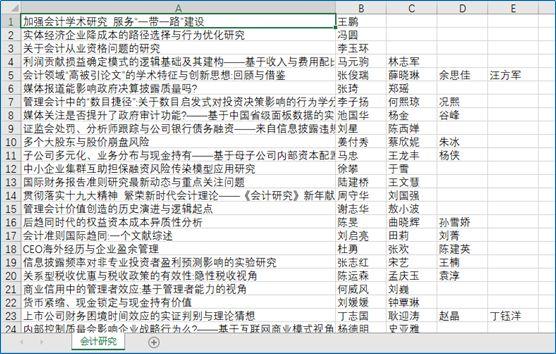
现在我们就成功使用Python得到了《会计研究》2018年12期期刊的文章题目和对应作者,达到了迅速浏览目录的效果。
三、小结
学术的路上,道阻且长,希望小编的这段程序可以帮助大家在学术道路上走得稍微容易一点,望大家多读文献、多发文献,把学术做得更好!
![]()
二、案例实操
(一)单个期刊
我们打开开发者模式,选择network,在name中寻找到网页信息,发现其网页获取方式是post,接着我们模拟人工浏览网页的行为写入headers对应的信息:url,request headers和querystring parameters。
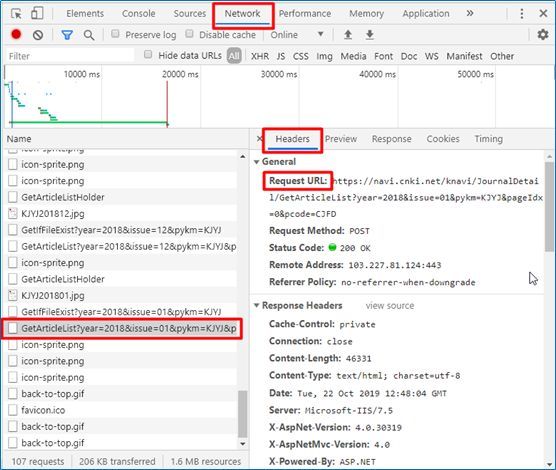
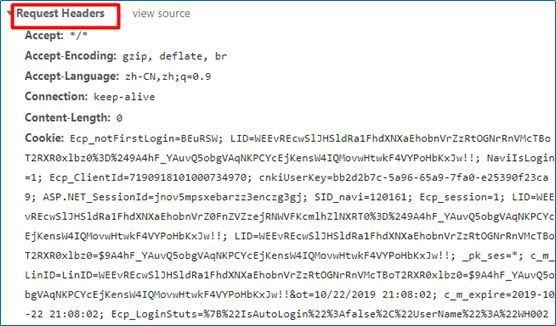
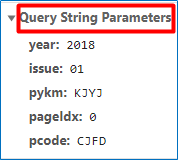
import requests #引入requests库爬取网页代码import json #引入json库处理data列表中的内容url='https://navi.cnki.net/knavi/JournalDetail/GetArticleList?year=2018&issue=01&pykm=KJYJ&pageIdx=0&pcode=CJFD'headers={'Accept': '*/*','Accept-Encoding':'gzip, deflate, br','Accept-Language':'zh-CN,zh;q=0.9','Connection':'keep-alive','Content-Length':'0','Cookie':'Ecp_notFirstLogin=lGQkVH; Ecp_ClientId=7190918101000734970;cnkiUserKey=bb2d2b7c-5a96-65a9-7fa0-e25390f23ca9;LID=WEEvREcwSlJHSldRa1FhdXNXaEhobnVrZ0FnZVZzejRNWVFKcmlhZlNXRT0=$9A4hF_YAuvQ5obgVAqNKPCYcEjKensW4IQMovwHtwkF4VYPoHbKxJw!!;ASP.NET_SessionId=jnov5mpsxebarzz3enczg3gj; SID_navi=120161;c_m_LinID=LinID=WEEvREcwSlJHSldRa1FhdXNXaEhobnVrZ0FnZVZzejRNWVFKcmlhZlNXRT0=$9A4hF_YAuvQ5obgVAqNKPCYcEjKensW4IQMovwHtwkF4VYPoHbKxJw!!&ot=10/22/201919:34:18; c_m_expire=2019-10-22 19:34:18; Ecp_session=1; Ecp_LoginStuts=%7B%22IsAutoLogin%22%3Afalse%2C%22UserName%22%3A%22WH0023%22%2C%22ShowName%22%3A%22%25E4%25B8%25AD%25E5%258D%2597%25E8%25B4%25A2%25E7%25BB%258F%25E6%2594%25BF%25E6%25B3%2595%25E5%25A4%25A7%25E5%25AD%25A6%22%2C%22UserType%22%3A%22bk%22%2C%22r%22%3A%22lGQkVH%22%7D;Ecp_notFirstLogin=lGQkVH;LID=WEEvREcwSlJHSldRa1FhdXNXaEhobnVrZ0FnZVZzejRNWVFKcmlhZlNXRT0%3D%249A4hF_YAuvQ5obgVAqNKPCYcEjKensW4IQMovwHtwkF4VYPoHbKxJw!!;NaviIsLogin=1; _pk_ses=*','Host':'navi.cnki.net','Origin':'https://navi.cnki.net','Referer':'https://navi.cnki.net/knavi/JournalDetail?pcode=CJFD&pykm=KJYJ','Sec-Fetch-Mode':'cors','Sec-Fetch-Site':'same-origin','User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, likeGecko) Chrome/75.0.3770.100 Safari/537.36','X-Requested-With':'XMLHttpRequest'}data={'year': '2018','issue': '01','pykm': 'KJYJ','pageIdx': '0','pcode': 'CJFD'}html=requests.post(url,headers=headers,data=json.dumps(data))
结果为:
说明网页爬取成功。至此我们就把2018年第一期期刊的网页源代码拿到了,接下来,使用xpath解析,得到目标信息。
from lxml import etree #引入lxml库totitlename=[] #首先定义空列表以盛放结果信息toauthor=[]tree=etree.HTML(html.text) #使用xpath进行解析titlename=tree.xpath("/html/body//span[@class='name']/a/text()")#得到这一节点对应的文本内容即为文章题目author=tree.xpath("/html/body//span[@class='author']/text()")#得到这一节点对应的文本内容即为作者totitlename.extend(titlename[0:len(author)]) #没有作者的文章题目,如征文启事,不保留toauthor.extend(author)print(totitlename)print(toauthor)
结果为:

至此我们成功得到了2018年第一期期刊所有的文章题目和作者。
(二)12期期刊
接下来,对于12期期刊,我们将用于单个期刊的程序封装进一个循环。其中关于f-string的用法参见往期推文《格式化字符串方法的比较》。
import requestsfrom lxml import etreeimport jsonimport retotitlename=[]toauthor=[]for issue in range(1,13):url=f'https://navi.cnki.net/knavi/JournalDetail/GetArticleList?year=2018&issue={issue:0>2d}&pykm=KJYJ&pageIdx=0&pcode=CJFD' #使用f-string实现{}内依次为两位数字01-12headers={'Accept':'*/*','Accept-Encoding':'gzip, deflate, br','Accept-Language':'zh-CN,zh;q=0.9','Connection':'keep-alive','Content-Length':'0','Cookie':'Ecp_notFirstLogin=lGQkVH; Ecp_ClientId=7190918101000734970;cnkiUserKey=bb2d2b7c-5a96-65a9-7fa0-e25390f23ca9;LID=WEEvREcwSlJHSldRa1FhdXNXaEhobnVrZ0FnZVZzejRNWVFKcmlhZlNXRT0=$9A4hF_YAuvQ5obgVAqNKPCYcEjKensW4IQMovwHtwkF4VYPoHbKxJw!!;ASP.NET_SessionId=jnov5mpsxebarzz3enczg3gj; SID_navi=120161;c_m_LinID=LinID=WEEvREcwSlJHSldRa1FhdXNXaEhobnVrZ0FnZVZzejRNWVFKcmlhZlNXRT0=$9A4hF_YAuvQ5obgVAqNKPCYcEjKensW4IQMovwHtwkF4VYPoHbKxJw!!&ot=10/22/201919:34:18; c_m_expire=2019-10-22 19:34:18; Ecp_session=1;Ecp_LoginStuts=%7B%22IsAutoLogin%22%3Afalse%2C%22UserName%22%3A%22WH0023%22%2C%22ShowName%22%3A%22%25E4%25B8%25AD%25E5%258D%2597%25E8%25B4%25A2%25E7%25BB%258F%25E6%2594%25BF%25E6%25B3%2595%25E5%25A4%25A7%25E5%25AD%25A6%22%2C%22UserType%22%3A%22bk%22%2C%22r%22%3A%22lGQkVH%22%7D;Ecp_notFirstLogin=lGQkVH;LID=WEEvREcwSlJHSldRa1FhdXNXaEhobnVrZ0FnZVZzejRNWVFKcmlhZlNXRT0%3D%249A4hF_YAuvQ5obgVAqNKPCYcEjKensW4IQMovwHtwkF4VYPoHbKxJw!!;NaviIsLogin=1; _pk_ses=*','Host':'navi.cnki.net','Origin':'https://navi.cnki.net','Referer': 'https://navi.cnki.net/knavi/JournalDetail?pcode=CJFD&pykm=KJYJ','Sec-Fetch-Mode':'cors','Sec-Fetch-Site':'same-origin','User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, likeGecko) Chrome/75.0.3770.100 Safari/537.36','X-Requested-With':'XMLHttpRequest'}data={'year':'2018','issue':f'{issue:0>2d}','pykm':'KJYJ','pageIdx':'0','pcode':'CJFD'}html=requests.post(url,headers=headers,data=json.dumps(data))tree=etree.HTML(html.text)titlename=tree.xpath("/html/body//span[@class='name']/a/text()")author=tree.xpath("/html/body//span[@class='author']/text()")totitlename.extend(titlename[0:len(author)])#没有作者的文章题目,如征文启事,不保留toauthor.extend(author)print(len(totitlename))print(len(toauthor))
结果为:

说明我们一共抓取到了157条信息。接下来我们将结果写入文件,保存下来。其中关于re.sub的使用参见往期推文《妙用正则表达式--Python中的re模块》。
with open('g:\\会计研究.csv','w',encoding='gb18030') as f:for i in range(0,len(toauthor)):f.write(totitlename[i].strip()+','+re.sub(";",",",toauthor[i])+'\n') #strip函数把文章题目中的空白字符删掉,re.sub把作者中的分号替换为逗号。写入文章题目+作者姓名
结果如下:

现在我们就成功使用Python得到了《会计研究》2018年12期期刊的文章题目和对应作者,达到了迅速浏览目录的效果。
三、小结
学术的路上,道阻且长,希望小编的这段程序可以帮助大家在学术道路上走得稍微容易一点,望大家多读文献、多发文献,把学术做得更好!