mysql数据库的小结
经过挺长时间的自我探索和学习,我看了好多的东西,书籍?博文?或者是一些技术博客上面的问答,但是由于能了解的东西还真的是不少,导致我总会忘记一些东西,所以我先简单写一点然后随着看随着进行记录。
首先说一些关于mysql数据库的相关问题,首先说一下mysql服务器的逻辑架构图:
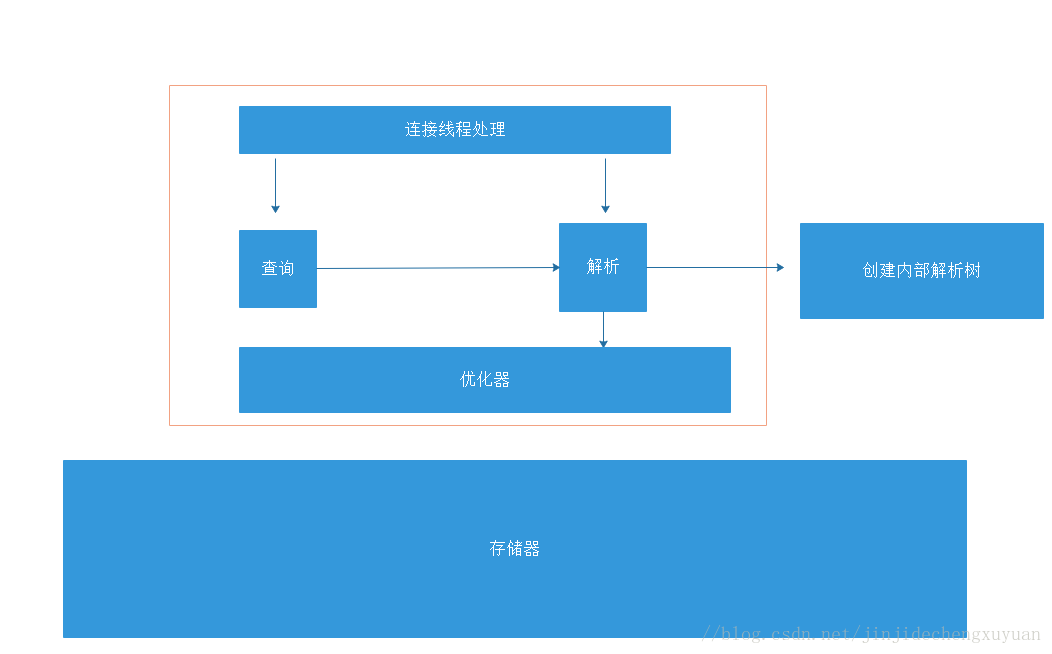
可以看到里面的东西除了外部的客户端访问,其余的图片已经体现出来,里面基本分为了两个部分,底层是存储引擎,上层则是一些优化器,解析器的东西。
在读数据方面一般分为共享锁,已经排他锁,不过,排他锁主要还是以写数据时为主,而锁大体比较常常提到的也是两个,一个是表锁,另一个则是行锁,行级别的锁一般在存储引擎层面就已经实现,另一个就是表锁了,在逻辑层就已经赋予。
谈到锁就可能涉及一些和粒度有关的问题,合理的粒度分配能够提高数据库在查询作业方面的性能,通常来说锁越少,并发性能也就变得越高,将粒度控制在一个相对准确的范围内准确的利用行级别的锁可以有效的改善并发效率,而数据库引擎的行级锁可以被覆盖,举个例子:alter table 这是一个sql语句,非常的常用,它这个语句执行之时执行的就是表锁,说明这个语句将行级锁在底层的实现给覆盖掉了。
有关事务方面,一个原子性的sql查询,要么全部成功,要么全部失败,这只是一个感念。
使用start transcation 开启事务,要么commit,要么rollback,整体进行返回。事务本身消耗大量的资源。
下面可能提及一些比较细节的问题,回顾一下概念,ACID ,这个概念应该相当的简单,就是原子性,一致性,隔离性,持久性。
事务的几种级别:
1.readuncommit:未提交可读:脏读现象频繁,基本不会有什么系统采纳这种方案
2.read commit:提交可读,即提交改动后才会真正让别人看见,但是不能重复读取。否则会出现不一致,大多数默认
3.repeatable:可重复读。幻读的问题出现。
4serializable:串行化,不用太细致说明也明白。这个在项目中使用有可能让任务排队到天荒地老。
mysql中的事务存储引擎熟知的有两个,一个是Innodb,一个是ndbcluster.
基本都是默认使用自动提交的方式;
然后为简单解释一下集中隔离级别出现现象的形象解释,避免错误理解:
1.脏读:简单来说有人在写入a和b,结果它刚写完a,你这边就读,而且你比他快,你一下都读完了,那么你了解的就是新的a 和旧的b,这样的数据是没有价值的。在readuncommit的事务情况下经常出现,当然一般没人用这种级别的事务。
2.不可重复读:就是假设你访问一个数据在一个事务中访问两次,而在此期间出现了另一个事务,对数据修改,很快完成了,那么你这两次的访问把修改的情况夹在中间,使得两次结果不同。
3幻读:就是当两个事务,一个是插入,一个是修改,修改过程中插入了新的,这就让看的觉得怎么没全部修改,实际是因为,修改过的地方被插入了数据。
啊,最后在简单聊聊范式吧,嗯,多么久远基础的知识,上研究生以后都没再看过了。
1NF: 典型的原子性,列不可再分:这是建立表的基本要求。
2NF:就是消除部分依赖,也比较常见,一个表有那么几个重要的决定全局的就够了,别出现部分传递性的依赖,出现就再拆一个表。
3NF:要求较高,在1nf 和2nf的基础上,表中不可再出现其他表中的非主属性值
BCNF:要求更特别:即使是码中也不要哟传递或者部分依赖。
顺带说一下,sql中or这个指令实际远不如in,原因也是因为in在底层的实现是二叉树查找O(logn)级别的复杂度,好了,唠叨完成,想必这么长的唠叨也很少有人看,如果有的话可以交流一下数据库调优方面的事情。