MySQL Master High Available 源码篇
MasterFailover (Non-GTID)
MHA::MasterFailover::main()->do_master_failoverfailover_non_gtid
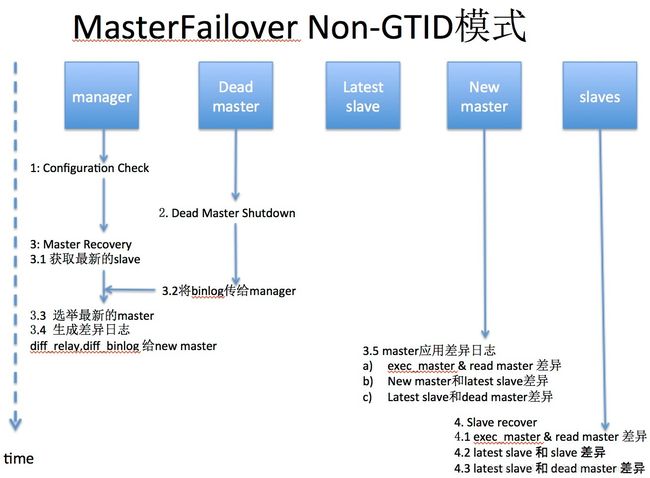
Phase 1: Configuration Check Phase
- init_config(): 初始化配置
- MHA::ServerManager::init_binlog_server: 初始化binlog server
- check_settings()
a. check_node_version(): 查看MHA的版本
b. connect_all_and_read_server_status(): 检测确认各个Node节点MySQL是否可以连接
c. get_dead_servers(),get_alive_servers(),get_alive_slaves():再次检测一次node节点的状态
d. print_dead_servers(): 是否挂掉的master是否是当前的master
e. MHA::DBHelper::check_connection_fast_util : 快速判断dead server,是否真的挂了,如果ping_type=insert,不会double check
f. MHA::NodeUtil::drop_file_if($_failover_error_file|$_failover_complete_file): 检测上次的failover文件
g. 如果上次failover的时间在8小时以内,那么这次就不会failover,除非配置了额外的参数
h. start_sql_threads_if(): 查看所有slave的Slave_SQL_Running是否为Yes,若不是则启动SQL thread- is_gtid_auto_pos_enabled(): 判断是否是GTID模式
Phase 2: Dead Master Shutdown Phase..
- force_shutdown($dead_master):
a. stop_io_thread(): stop所有slave的IO_thread
b. force_shutdown_internal($dead_master):
b_1. master_ip_failover_script: 如果有这个脚本,则执行里面的逻辑(比如:切换vip)
b_2. shutdown_script:如果有这个脚本,则执行里面的逻辑(比如:Power off 服务器)Phase 3: Master Recovery Phase..
- Phase 3.1: Getting Latest Slaves Phase..
* check_set_latest_slaves()
a. read_slave_status(): 获取所有show slave status 信息
b. identify_latest_slaves(): 找到最新的slave是哪个
c. identify_oldest_slaves(): 找到最老的slave是哪个- Phase 3.2: Saving Dead Master’s Binlog Phase..
* save_master_binlog($dead_master);
-> 如果dead master可以ssh,那么
b_1_1. save_master_binlog_internal: 用node节点save_binary_logs脚本拷贝相应binlog到manager
diff_binary_log 生产差异binlog日志
b_1_2. file_copy: 将差异binlog拷贝到manager节点的 manager_workdir目录下
-> 如果dead master不可以ssh
b_1_3. 那么差异日志就会丢失- Phase 3.3: Determining New Master Phase..
b. 如果GTID auto_pos没有打开,调用find_latest_base_slave()
b_1. find_latest_base_slave_internal: 寻找拥有所有relay-log的最新slave,如果没有,则failover失败
b_1_1. find_slave_with_all_relay_logs:
b_1_1_1. apply_diff_relay_logs: 查看最新的slave是否有其他slave缺失的relay-log
c. select_new_master: 选举new master
c_1. MHA::ServerManager::select_new_master:
#If preferred node is specified, one of active preferred nodes will be new master.
#If the latest server behinds too much (i.e. stopping sql thread for online backups), we should not use it as a new master, but we should fetch relay log there
#Even though preferred master is configured, it does not become a master if it's far behind
get_candidate_masters(): 获取配置中候选节点
get_bad_candidate_masters(): 以下条件不能成为候选master
# dead server
# no_master >= 1
# log_bin=0
# oldest_major_version=0
# check_slave_delay: 检查是否延迟非常厉害(可以通过设置no_check_delay忽略)
{Exec_Master_Log_Pos} + 100000000 只要binlog position不超过100000000 就行
选举流程: 先看candidate_master,然后找 latest slave, 然后再随机挑选- Phase 3.3(3.4): New Master Diff Log Generation Phase..
* recover_master_internal
recover_relay_logs:
判断new master是否为最新的slave,如果不是,则生产差异relay logs,并发送给新master
recover_master_internal:
将之前生产的dead master上的binlog传送给new master- Phase 3.4: Master Log Apply Phase..
* apply_diff:
a. wait_until_relay_log_applied: 直到new master完成所有relay log,否则一直等待
b. 判断Exec_Master_Log_Pos == Read_Master_Log_Pos, 如果不等,那么生产差异日志:
save_binary_logs --command=save
c. apply_diff_relay_logs --command=apply:对new master进行恢复
c_1. exec_diff:Exec_Master_Log_Pos和Read_Master_Log_Pos的差异日志
c_2. read_diff:new master与lastest slave的relay log的差异日志
c_3. binlog_diff:lastest slave与daed master之间的binlog差异日志
* 如果设置了master_ip_failover_script脚本,那么会执行这里面的脚本(一般用来漂移vip)
* disable_read_only(): 允许new master可写Phase 4: Slaves Recovery Phase..
recover_slaves_internal- Phase 4.1: Starting Parallel Slave Diff Log Generation Phase..
recover_all_slaves_relay_logs: 生成Slave与New Slave之间的差异日志,并将该日志拷贝到各Slave的工作目录下- Phase 4.2: Starting Parallel Slave Log Apply Phase..
* recover_slave:
对每个slave进行恢复,跟以上Phase 3.4: Master Log Apply Phase中的 apply_diff一样
* change_master_and_start_slave:
重新指向到new master,并且start slavePhase 5: New master cleanup phase..
- reset_slave_on_new_master
在new master上执行reset slave all;MasterFailover (GTID)
failover_gitd

Phase 1: Configuration Check Phase
- init_config(): 初始化配置
- MHA::ServerManager::init_binlog_server: 初始化binlog server
- check_settings()
a. check_node_version(): 查看MHA的版本
b. connect_all_and_read_server_status(): 检测确认各个Node节点MySQL是否可以连接
c. get_dead_servers(),get_alive_servers(),get_alive_slaves():再次检测一次node节点的状态
d. print_dead_servers(): 是否挂掉的master是否是当前的master
e. MHA::DBHelper::check_connection_fast_util : 快速判断dead server,是否真的挂了,如果ping_type=insert,不会double check
f. MHA::NodeUtil::drop_file_if($_failover_error_file|$_failover_complete_file): 检测上次的failover文件
g. 如果上次failover的时间在8小时以内,那么这次就不会failover,除非配置了额外的参数
h. start_sql_threads_if(): 查看所有slave的Slave_SQL_Running是否为Yes,若不是则启动SQL thread- is_gtid_auto_pos_enabled(): 判断是否是GTID模式
Phase 2: Dead Master Shutdown Phase completed.
- force_shutdown($dead_master):
a. stop_io_thread(): stop所有slave的IO_thread
b. force_shutdown_internal($dead_master):
b_1. master_ip_failover_script: 如果有这个脚本,则执行里面的逻辑(比如:切换vip)
b_2. shutdown_script:如果有这个脚本,则执行里面的逻辑(比如:Power off 服务器)Phase 3: Master Recovery Phase..
- Phase 3.1: Getting Latest Slaves Phase..
* check_set_latest_slaves()
a. read_slave_status(): 获取所有show slave status 信息
b. identify_latest_slaves(): 找到最新的slave是哪个
c. identify_oldest_slaves(): 找到最老的slave是哪个Phase 3.2: Saving Dead Master’s Binlog Phase.. (GTID 模式下没有这一步)
Phase 3.3: Determining New Master Phase..
get_most_advanced_latest_slave(): 获取最新的slave
c. select_new_master: 选举new master
c_1. MHA::ServerManager::select_new_master:
#If preferred node is specified, one of active preferred nodes will be new master.
#If the latest server behinds too much (i.e. stopping sql thread for online backups), we should not use it as a new master, but we should fetch relay log there
#Even though preferred master is configured, it does not become a master if it's far behind
get_candidate_masters(): 获取配置中候选节点
get_bad_candidate_masters(): 以下条件不能成为候选master
# dead server
# no_master >= 1
# log_bin=0
# oldest_major_version=0
# check_slave_delay: 检查是否延迟非常厉害(可以通过设置no_check_delay忽略)
{Exec_Master_Log_Pos} + 100000000 只要binlog position不超过100000000 就行
选举流程: 先看candidate_master,然后找 latest slave, 然后再随机挑选- Phase 3.3: New Master Recovery Phase..
* recover_master_gtid_internal:
wait_until_relay_log_applied: 候选master等待所有relay-log都应用完
如果候选master不是最新的slave:
$latest_slave->wait_until_relay_log_applied($log): 最新的slave应用完所有的relay-log
change_master_and_start_slave : 让候选master同步到latest master,追上latest slave
获取候选master此时此刻的日志信息,以便后面切换
如果候选master是最新的slave:
获取候选master此时此刻的日志信息,以便后面切换
save_from_binlog_server:
如果配置了binlog server,那么在binlogsever 能连的情况下,将binlog 拷贝到Manager,并生成差异日志diff_binlog(save_binary_logs --command=save)
apply_binlog_to_master:
Applying differential binlog: 应用差异的binlog到new masterPhase 4: Slaves Recovery Phase..
- Phase 4.1: Starting Slaves in parallel..
* recover_slaves_gtid_internal:
change_master_and_start_slave: 因为master已经恢复,那么slave直接change master auto_pos=1 的模式就可以恢复
gtid_wait:用此等待同步全部追上Phase 5: New master cleanup phase..
- reset_slave_on_new_master
在new master上执行reset slave all;MasterRotate (Non-GTID)
Phase 1: Configuration Check Phase
- do_master_online_switch
- identify_orig_master
* read_config():
Reading default configuration from /etc/masterha_default.cnf..
Reading application default configuration from /etc/app1.cnf..
Reading server configuration from /etc/app1.cnf..
* connect_all_and_read_server_status:
connect_check: 首先进行connect check,确保各个server的MySQL服务都正常
connect_and_get_status:
获取MySQL实例的server_id/mysql_version/log_bin..等信息
通过执行show slave status,获取当前的master节点。如果输出为空,说明当前节点是master节点( 0.56已经不是这么判断了,已经支持multi master)
validate_current_master:取得master节点的信息,并判断配置的正确性
check是否有server down,若有则退出rotate
check master alive or not,若dead则退出rotate
check_repl_priv:
查看用户是否有replication的权限
获取monitor_advisory_lock,以保证当前没有其他的monitor进程在master上运行
执行:SELECT GET_LOCK('MHA_Master_High_Availability_Monitor', ?) AS Value
获取failover_advisory_lock,以保证当前没有其他的failover进程在slave上运行
执行:SELECT GET_LOCK('MHA_Master_High_Availability_Failover', ?) AS Value
check_replication_health:
执行:SHOW SLAVE STATUS来判断如下状态:current_slave_position/has_replication_problem
其中,has_replication_problem具体check如下内容:IO线程/SQL线程/Seconds_Behind_Master(1s)
get_running_update_threads:
使用show processlist来查询当前有没有执行update的线程存在,若有则退出switch
$self->validate_current_master():
检查是否是GTID模式- identify_new_master
set_latest_slaves:当前的slave节点都是latest slave
select_new_master: 选举new master
c_1. MHA::ServerManager::select_new_master:
#If preferred node is specified, one of active preferred nodes will be new master.
#If the latest server behinds too much (i.e. stopping sql thread for online backups), we should not use it as a new master, but we should fetch relay log there
#Even though preferred master is configured, it does not become a master if it's far behind
get_candidate_masters(): 获取配置中候选节点
get_bad_candidate_masters(): 以下条件不能成为候选master
# dead server
# no_master >= 1
# log_bin=0
# oldest_major_version=0
# check_slave_delay: 检查是否延迟非常厉害(可以通过设置no_check_delay忽略)
{Exec_Master_Log_Pos} + 100000000 只要binlog position不超过100000000 就行
选举流程: 先看candidate_master,然后找 latest slave, 然后再随机挑选Phase 2: Rejecting updates Phase
- reject_update
* lock table来reject write binlog
调用master_ip_online_change_script --command=stop
如果MHA的配置文件中设置了"master_ip_online_change_script"参数,则执行该脚本来disable writes on the current master
该脚本在使用了vip的时候,在origin master上删除vip{可选}
reconnect:确保当前与master的连接正常
lock_all_tables:执行FLUSH TABLES WITH READ LOCK,来lock table
check_binlog_stop:连续两次show master status,来判断写binlog是否已经停止- read_slave_status
get_alive_slaves:
check_slave_status:调用"SHOW SLAVE STATUS"来取得slave的信息:- switch_master
switch_master_internal:
master_pos_wait:调用select master_pos_wait函数,等待主从同步完成
get_new_master_binlog_position:通过'show master status'来获取
Allow write access on the new master:
调用master_ip_online_change_script --command=start ...,将vip指向new master
disable_read_only:
在新master上执行:SET GLOBAL read_only=0- switch_slaves
switch_slaves_internal:
change_master_and_start_slave
change_master:
start_slave:
unlock_tables:在orig master上执行unlock tablePhase 5: New master cleanup phase
- reset_slave_on_new_master
- release_failover_advisory_lock
MasterRotate (GTID)
GTID模式的online switch 和 non-GTID 流程一样,除了在change_master_and_start_slave 不一样之外
GTID的小问题
今天测试了一把GTID的在线切换,遇到的问题非常诡异
- 问题:新搭建了一组group,做MHA在线切换,结果却导致环境混乱。
命令:masterha_master_switch --master_state=alive --conf=/etc/app1.cnf --orig_master_is_new_slave --interactive=0
A(master),B(candidate master),C 一组复制环境,执行在线切换后,C竟然还同步在A上
B(master)
-> A(slave) -> C(slave) --错误案例
正确的结果应该是:
B(master)
-> A(slave)
-> C(slave)
看了MHA的切换日志,都是正常的,Switching master to xx completed successfully.
这样只能翻翻源码,果然,很快就找到了问题所在:
MHA::ServerManager->is_gtid_auto_pos_enabled->get_gtid_status()
sub get_gtid_status($) {
my $self = shift;
my @servers = $self->get_alive_servers();
my @slaves = $self->get_alive_slaves();
return 0 if ( $#servers < 0 );
foreach (@servers) {
return 0 unless ( $_->{has_gtid} );
}
foreach (@slaves) {
return 0 unless ( $_->{Executed_Gtid_Set} ); -- 如果show slave status中没有执行过任何Executed_Gtid_Set,那么会认为是非GTID模式
}
foreach (@slaves) {
return 1
if ( defined( $_->{Auto_Position} )
&& $_->{Auto_Position} == 1 );
return 1 if ( $_->{use_gtid_auto_pos} );
}
return 2;
}
* 解决方案也很简单:
1)因为没有执行过任何事物,那就执行一条呗
2)修改源码,将这一步验证独钓即可。
实时证明,以上两种都可以验证通过重点需要注意的地方
- mha with not binlog server
* 根据上述源码分析得到,如果没有配置binlog server的 GTID 模式failover,会导致数据丢失,即使master ssh可达
* 通过测试,的确在old master SSH可达的情况下,它也不会去save binlog,所以GTID和non-GTID模式的区别比较大。
* 解决的方案就是: 配置Binlog Server
/etc/app1.cnf
[server default]
remote_workdir=/var/log/masterha/app1
manager_workdir=/var/log/masterha/app1
manager_log=/var/log/masterha/app1/app1.log
[server1]
hostname=host1
candidate_master=1
check_repl_delay=0
[server2]
hostname=host2
candidate_master=1
check_repl_delay=0
[server3]
hostname=host3
no_master=1
check_repl_delay=0
[binlog1]
hostname=host1 --注意:这里既可以设置master为binlog server,也可以设置其他专用的binlog server- 常用配置
/etc/app1.cnf
[server default]
remote_workdir=/var/log/masterha/app1
manager_workdir=/var/log/masterha/app1
manager_log=/var/log/masterha/app1/app1.log
[server1]
hostname=host1
candidate_master=1 --表示候选 master
check_repl_delay=0 --当 slave 有延迟的时候,如果没有这个参数,会失败
[server2]
hostname=host2
candidate_master=1
check_repl_delay=0
[server3]
hostname=host3
no_master=1 --永远不会成为new master
check_repl_delay=0
ignore_fail=1 -- 如果不设置为1,那么如果server3有问题,切换会失败
[binlog1]
hostname=host1 --注意:这里既可以设置master为binlog server,也可以设置其他专用的binlog server- 常用命令
masterha_check_repl --conf=/etc/app1.cnf
masterha_check_status --conf=/etc/app1.cnf
masterha_stop --conf=/etc/app1.cnf
masterha_ssh_check --conf=/etc/app1.cnf
masterha_master_switch --master_state=dead --conf=/etc/app1.cnf --dead_master_host=host_1 --interactive=1 --ignore_last_failover
masterha_master_switch --master_state=dead --conf=/etc/app1.cnf --dead_master_host=host_1 --interactive=0 --ignore_last_failover
masterha_master_switch --master_state=alive --conf=/etc/app1.cnf --orig_master_is_new_slave --interactive=0 --running_updates_limit=10000
masterha_master_switch --master_state=dead --conf=/etc/app1.cnf --dead_master_host=host_1 --interactive=1 --ignore_last_failover --new_master_host=host_2
nohup masterha_manager --conf=/etc/app1.cnf --last_failover_minute=1 --ignore_last_failover &原文地址:MySQL Master High Available 源码篇
https://yq.aliyun.com/articles/59233?spm=5176.100239.blogcont58920.12.wGfswA