【Python爬虫+js逆向】使用Python爬取腾讯漫画的逆向分析(典型签名验证反爬虫的解决方案)——以腾讯动漫《一人之下》第一话为例
前一段假期期间,博主已经自学完了Python反爬虫的相关内容,面对各大网站的反爬机制也都有了一战之力。可惜因实战经验不足,所以总体来说还是一个字——菜。前两天,在学习并实战爬取了博主最爱看的腾讯动漫后,博主对于js逆向的相关反爬技术有了更加深入的理解。
目录
- 目标网站爬取分析
- 反爬思路分析
- 反爬解密分析
- Python代码实战分析
- 解密数据获取
- JavaScript逆向
- 漫画数据解析
- 整体代码优化
- 整体代码
- Pyinstaller打包
- 效果展示
- 总结
目标网站爬取分析
反爬思路分析
首先打开腾讯漫画《一人之下》的第一话(目标网址:https://ac.qq.com/ComicView/index/id/531490/cid/1),打开开发者工具(F12),切换到网络选项卡(Network)下,下拉滚动漫画可以发现其中的图片不断地加载出来(类似微博的滚动机制)。
因此,初步判断腾讯动漫可能是动态加载的,所以此时切换至XHR标签下。
然而,在XHR标签下,我们只能通过Preview发现腾讯漫画中的弹幕信息,其他则是什么都没有。
此路不可行,那么我们复制图片的地址在全局进行搜索(CTRL+F)。
通过搜索可发现,除了Network中加载的图片自身,图片地址不存在于其他的任何地方。因此,我们得出这么一条结论:图片地址既没有动态加载,也没有在其他源代码中,说明图片地址被加密存放到了某个地方。除去图片、css、js这些,唯一剩下的可能性便是在主页了,所以我们直接切换到Element选项卡中去观察主页的源代码,并且重点关注script标签下的内容。
纵观整个主页的源代码,唯一可能存放加密数据的只有body结尾处的script标签下(显眼的DATA数据)。
反爬解密分析
经过上述分析后,我们确定了scrpit标签下的目标内容,初步判断DATA变量有可能就是加密后的数据。
var DATA = 'efyJjb21pYyIb6eyJpZCI6NTMxNDkwLCJ0aXRsZSI6Ilxdf1NGUwMFx1NGViYVx1NGU0Ylx1NGUwYiIsImNvbGxleY3QiOiIe1MjYxOTI3IiwiaXNKYXBhbkNvbWljIjpmYWxzZSwiaXNMaWdodE5vdmVsIjpmYWxzZSwiaXNMaWdodENvbWljIjpmYWxzZSwiaXNGaW5pc2giOmZhbHNlLCJpc1JvYXN0YWJsZSI6dHJ1ZSwiZUlkIjoiS2xCeacUFFVcEFWVlpYQXdvZkFRWUhBd0VKSEVFeSJ9LCJjaGFwdGVyIjp7ImNpZCI6MSwiY1RpdGxlIjoiMS5cdTU5ZDBcdTU5ZDAxIiwiY1NlcSI6IjEiLCJ2aXBTdGF0dXMiOjEsInByZXZDaWQiOjAsIm5leHRDaWQiOjIsImJsYW5rRmlyc3QiOjEsInZfY2x1Yl9zdGF0ZSI6IjEiLCJpc19hcHBfY2hhcHRlciI6ZmFsc2UsImNhblJlYWQiOnRydWV9LCJwaWN0dXJlIjpbeyJwaWQiOiIzMzIwMSIsIndpZHRoIjoxMjAwLCJoZWlnaHQiOjE5MDcsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMDhfMTJfNTlfYTYyZTk2ZDUxYmFiMmMxYWI0MGVkN2ZmNjU4OGY1NjUyXzExMjM3MTY4Ny5qcGdcLzAifSx7InBpZCI6Ijc3ODgiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTVfNGY5YzczMzIzOWI1ZjM4MTZmMjEyN2RlY2E5ZWY2ZjdfNzc4OC5qcGdcLzAifSx7InBpZCI6Ijc3ODkiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTVfY2U5YjM2YmM2MGUxNjFiNjRjNzI5MTA3YzI2OTEwOTVfNzc4OS5qcGdcLzAifSx7InBpZCI6Ijc3OTAiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfMjBmOWU0NWM5Zjk5NzBmNGNkMWJhYzc1NWI4MGNiNGZfNzc5MC5qcGdcLzAifSx7InBpZCI6Ijc3OTEiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfYTM0ODEyNGUyYzBlZTJkYjg5NTVmOWI4YTNhYjVkODhfNzc5MS5qcGdcLzAifSx7InBpZCI6Ijc3OTIiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfNzAyOWU5MjU4NTI3M2MzNzMwN2MyZTE5Mjk0OTEwNzdfNzc5Mi5qcGdcLzAifSx7InBpZCI6Ijc3OTMiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfMDUwNDAxYjdlNjMyNDFhODhhMjYwYzgxM2FlODIzNGZfNzc5My5qcGdcLzAifSx7InBpZCI6Ijc3OTQiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfZmYzMzNhNWRmYTA1NzdmMTExODE1ZDFiODVjMzdhM2NfNzc5NC5qcGdcLzAifSx7InBpZCI6Ijc3OTUiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfNDVhYTAwMTAyYTVjNzk0Yzg2ZWY1MDE3YzFhNDZkYWNfNzc5NS5qcGdcLzAifSx7InBpZCI6Ijc3OTYiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfNzZhNDI0MjM4NTUwNmZhMDE3MGY5M2E2YWNhYWQwMWRfNzc5Ni5qcGdcLzAifSx7InBpZCI6Ijc3OTciLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfZGNlMGM3YjU4NWQyMDhlNjY0Y2JhMjg1MDEzM2EwZWRfNzc5Ny5qcGdcLzAifSx7InBpZCI6Ijc3OTgiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfMGQ1NWUyOTFiZjgwMDU2YWRhMmZjYWU3N2ExMGE5ZTVfNzc5OC5qcGdcLzAifSx7InBpZCI6Ijc3OTkiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfYzhhZDNkMzI2OGYyMGVlNDU5YzU3NGU1NDRmYjQxMzVfNzc5OS5qcGdcLzAifSx7InBpZCI6Ijc4MDAiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfMjBkZTExNWNkZTNhYzlmOTJlMjc0MWQ0MzY3OWM4N2NfNzgwMC5qcGdcLzAifSx7InBpZCI6Ijc4MDEiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzEsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfNzBmMmEwNDE3NTViNjc2ODcwNjNmMzJlMTJlN2NkMWRfNzgwMS5qcGdcLzAifSx7InBpZCI6Ijc4MDIiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfYzQxZWI2M2JiNTZmNTRhNDcyMzk4ZjhlYjBlZGE4MmNfNzgwMi5qcGdcLzAifSx7InBpZCI6Ijc4MDMiLCJ3aWR0aCI6ODAwLCJoZWlnaHQiOjEyNzAsInVybCI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvbWFuaHVhX2RldGFpbFwvMFwvMTZfMTJfNTZfOTVlMzVlM2FiMGQ2OWY2NTk0NTMyZjA3NDAzZmYyZGZfNzgwMy5qcGdcLzAifV0sImFkcyI6eyJ0b3AiOnsidGl0bGUiOiJcdTUxNmNcdTc2Y2EiLCJ1cmwiOiJodHRwczpcL1wvd2VpYm8uY29tXC81NjE2NTQ5MzY5XC9KamNKNWI1aTU/ZnJvbT1wYWdlXzEwMDIwNjU2MTY1NDkzNjlfcHJvZmlsZSZ3dnI9NiZtb2Q9d2VpYm90aW1lJnR5cGU9Y29tbWVudCNfcm5kMTU5OTUzNDY0NTIwNSIsInBpYyI6Imh0dHBzOlwvXC9tYW5odWEucXBpYy5jblwvb3BlcmF0aW9uXC8wXC8wOF8xMV8yNV82MTk2ODNjMDYyNGNjNjhkYjExYmVjZTVhNzA2ZmYzOV8xNTk5NTM1NTUxNzMxLmpwZ1wvMCJ9LCJib3R0b20iOiIifSwiYXJ0aXN0Ijp7ImF2YXRhciI6Imh0dHBzOlwvXC9cL3EzLnFsb2dvLmNuXC9nP2I9cXEmaz01aHZlUkRSRGNxenZVeURFSE95TnFnJnM9MTAwJnQ9MTQ5NzcwMTk2NSIsIm5pY2siOiJcdTUyYThcdTZmMmJcdTU4MDJcdTVjMGZcdTRlZDkiLCJ1aW5DcnlwdCI6Ik1YZzFVRUZFY0RaS1lqWnBjSEZqYnl0ellrbG5kejA5In19',
PRELOAD_NUM = 2,
NOTICE_TIME = 15,
ROAST_SIZE = 1000,
ROAST_PRE = 20,
ROAST_VIEW = 20,
TUCAO_INTERVAL = 8000,
DANMU_INTERVAL = 2000,
DANMU_TIME = 10000;
我们需要想办法解密这段DATA数据。因此,切换到Network选项卡并继续在全局中搜素“DATA”,这里注意要区分大小写!
观察发现,除了主页scrpit标签下的DATA变量自身之外,只剩下一个js文件内存在“DATA”(https://ac.gtimg.com/media/js/ac.page.chapter.view_v2.6.0.js?v=20200907)。因此,我们在Network选项卡中找到并进入这个js文件,切换到Preview下继续(CTRL+F)搜索“DATA”,同样注意要区分大小写!
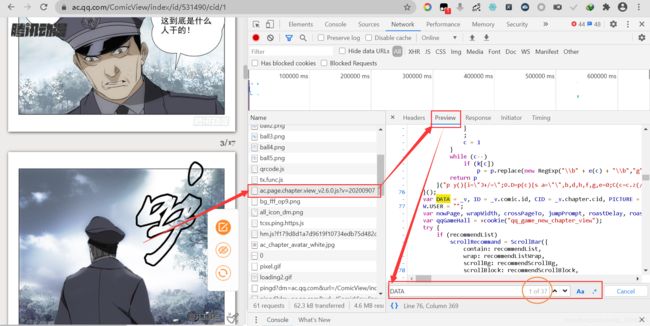
经过区分大小写搜索“DATA”后,我们发现有37处出现了“DATA”。全部浏览过后,发现除了第一个DATA进行了赋值以外,其他都是取的DATA变量的值。因此,判断关键之处便在于第一个DATA的变量。
但是还没有解密,那又要怎么取值呢?这里我们需要进行打断点分析取值。
为了方便打断点,这里我们右键点击Network中的js文件,选择Open in Sources panel从Sources选项卡打开,再通过点击Pretty-print将代码格式化。
我们重新搜索找到第一个DATA的位置,直接在第一次出现的DATA变量的那一行打上断点,然后刷新页面。
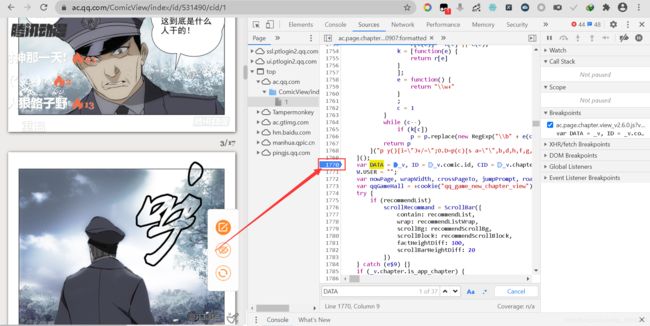
刷新页面后,我们将鼠标指针放在_v上,此时会显示出_v的相关数据。(下拉右边Scrope下的Local中的代码,同样观察可发现第一次出现的DATA赋值中“DATA = _v”里面的_v变量。)
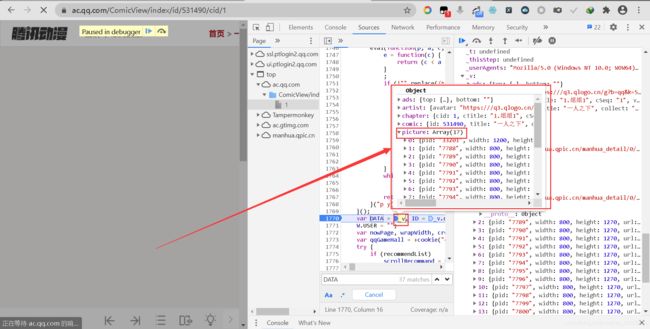
打开_v变量,可在picture下找到图片的url,双击复制并去掉左右双引号,在新的页面运行后可以看到漫画图片,证明所有的图片地址都存在于_v变量下面。
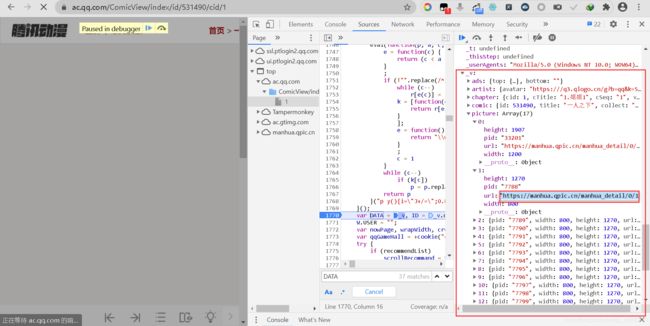
因此,接下来我们继续区分大小写搜索_v,可搜索到13个内容。

通过Search next简单看一遍所有的_v,发现除了取值、函数变量以及一些其他的字符串包含这个,剩下的一个在DATA = _v赋值语句上面的立即执行函数里面。立即执行函数如下所示:
eval(function(p, a, c, k, e, r) {
e = function(c) {
return (c < a ? "" : e(parseInt(c / a))) + ((c = c % a) > 35 ? String.fromCharCode(c + 29) : c.toString(36))
}
;
if (!"".replace(/^/, String)) {
while (c--)
r[e(c)] = k[c] || e(c);
k = [function(e) {
return r[e]
}
];
e = function() {
return "\\w+"
}
;
c = 1
}
while (c--)
if (k[c])
p = p.replace(new RegExp("\\b" + e(c) + "\\b","g"), k[c]);
return p
}("p y(){i=\"J+/=\";O.D=p(c){s a=\"\",b,d,h,f,g,e=0;C(c=c.z(/[^A-G-H-9\\+\\/\\=]/g,\"\");e>4,d=(d&15)<<4|f>>2,h=(f&3)<<6|g,a+=7.5(b),w!=f&&(a+=7.5(d)),w!=g&&(a+=7.5(h));v a=u(a)};u=p(c){C(s a=\"\",b=0,d=17=8=0;bd?(a+=7.5(d),b++):Rd?(8=c.o(b+1),a+=7.5((d&F)<<6|8&r),b+=2):(8=c.o(b+1),x=c.o(b+2),a+=7.5((d&15)<<12|(8&r)<<6|x&r),b+=3);v a}}s B=I y(),T=W['K'+'L'].M(''),N=W['n'+'P'+'e'],j,t,q;N=N.U(/\\d+[a-V-Z]+/g);j=N.k;X(j--){t=Y(N[j])&10;q=N[j].z(/\\d+/g,'');T.11(t,q.k)}T=T.13('');14=16.E(B.D(T));" , 62, 70, "|||||fromCharCode||String|c2||||||||||_keyStr|len|length|indexOf|charAt||charCodeAt|function|str|63|var|locate|_utf8_decode|return|64|c3|Base|replace|||for|decode|parse|31|Za|z0|new|ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789|DA|TA|split||this|onc|128|191|224||match|zA||while|parseInt||255|splice||join|_v||JSON|c1".split("|"), 0, {}))
很明显,这一段js代码是加密过后的。因此,我们需要使用解密工具对这一段立即执行函数进行解密。这里,我们使用的解密工具是:JavaScript Eval 在线加密/解密, 编码/解码工具(https://wangye.org/tools/scripts/eval/)。经过解密,可以得到下面的js代码:
function Base() {
_keyStr = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=";
this.decode = function(c) {
var a = "",
b, d, h, f, g, e = 0;
for (c = c.replace(/[^A-Za-z0-9\+\/\=]/g, ""); e < c.length;) b = _keyStr.indexOf(c.charAt(e++)),
d = _keyStr.indexOf(c.charAt(e++)),
f = _keyStr.indexOf(c.charAt(e++)),
g = _keyStr.indexOf(c.charAt(e++)),
b = b << 2 | d >> 4,
d = (d & 15) << 4 | f >> 2,
h = (f & 3) << 6 | g,
a += String.fromCharCode(b),
64 != f && (a += String.fromCharCode(d)),
64 != g && (a += String.fromCharCode(h));
return a = _utf8_decode(a)
};
_utf8_decode = function(c) {
for (var a = "",
b = 0,
d = c1 = c2 = 0; b < c.length;) d = c.charCodeAt(b),
128 > d ? (a += String.fromCharCode(d), b++) : 191 < d && 224 > d ? (c2 = c.charCodeAt(b + 1), a += String.fromCharCode((d & 31) << 6 | c2 & 63), b += 2) : (c2 = c.charCodeAt(b + 1), c3 = c.charCodeAt(b + 2), a += String.fromCharCode((d & 15) << 12 | (c2 & 63) << 6 | c3 & 63), b += 3);
return a
}
}
var B = new Base(),
T = W['DA' + 'TA'].split(''),
N = W['n' + 'onc' + 'e'],
len,
locate,
str;
N = N.match(/\d+[a-zA-Z]+/g);
len = N.length;
while (len--) {
locate = parseInt(N[len]) & 255;
str = N[len].replace(/\d+/g, '');
T.splice(locate, str.length)
}
T = T.join('');
_v = JSON.parse(B.decode(T));
观察发现,第40行中的“_v = JSON.parse(B.decode(T));”便是解密后的_v变量,第27行“T = W[‘DA’ + ‘TA’].split(’’),”便是前面的DATA加密数据。那么,我们可以肯定这段js代码就是最为关键的解密函数。
分析这段代码,_v调用了B的decode方法(B是Base的对象),传入的参数是T,而T又是通过前面的T参数(T = W[‘DA’ + ‘TA’].split(’’))和N参数(N = W[‘n’ + ‘onc’ + ‘e’])计算出来的。
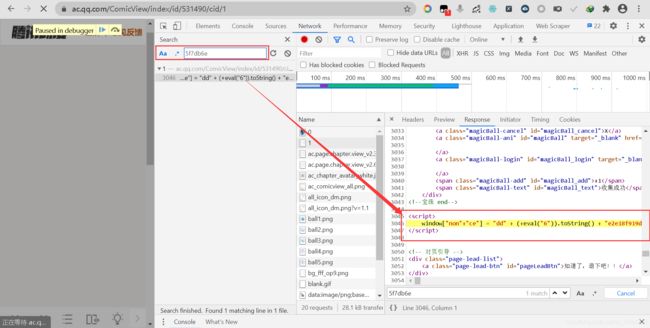
所以,我们切换到Console选项卡,在控制台Console界面分别输入W[‘DA’ + ‘TA’]和W[‘n’ + ‘onc’ + ‘e’]。注意:W在解密后的js里面,如果执行时报错,则可能是因为没有下断点,因此必须在断点断下的时候执行。
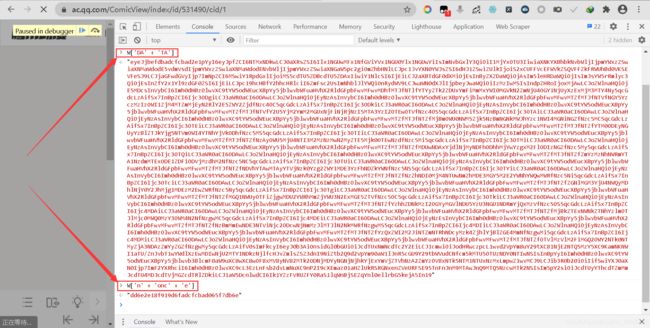
通过控制台输出后,我们通过搜索可以发现,W[‘DA’ + ‘TA’]就是前面的DATA加密数据,W[‘n’ + ‘onc’ + ‘e’]可以在主页源代码中找到(主页源代码中的字符串被拆分了,需要搜索部分字符串才能找到)。
分析完毕,接下来我们开始编写Python代码。
Python代码实战分析
解密数据获取
我们首先来获取以上所分析的T参数和N参数对应的两个数据:
import requests
import re
url = 'https://ac.qq.com/ComicView/index/id/531490/cid/1'
res = requests.get(url).text
data = re.findall("(?<=var DATA = ').*?(?=')", res)[0] # 提取DATA
nonce = re.findall('window\[".+?(?<=;)', res)[0] # 提取window["no"+"nce"]
print(data)
print(nonce)
但是,经过输出测试后而可发现,nonce仍旧是一段js代码而不是字符串。nonce的输出内容如下所示:
window["non"+"ce"] = "c477c" + (+eval("1/2 + 5/2")).toString() + "59" + (+eval("1 * (!window.Array) + 1")).toString() + "354" + (+eval("0 * 0")).toString() + "6" + (+eval("Math.pow(1,3)+1+1")).toString() + "a78e474" + (+eval("2 + 2")).toString() + "e919dea2d";
这里我们具有两种解决方式:① 调用nodejs来计算;② 使用python第三方库execjs模块来计算。
我们主要来介绍第二种方式,因此首先需要安装Python的第三方库:
pip install PyExecJS
然后,对nonce的js代码段进行“掐头去尾”,即分别删去“window[“non”+“ce”] = ”和“;”,最后通过execjs模块计算js代码。
import requests
import re
import execjs
url = 'https://ac.qq.com/ComicView/index/id/531490/cid/1'
res = requests.get(url).text
data = re.findall("(?<=var DATA = ').*?(?=')", res)[0] # 提取DATA
nonce = re.findall('window\[".+?(?<=;)', res)[0] # 提取window["no"+"nce"]
nonce = '='.join(nonce.split('=')[1:])[:-1] # 掐头去尾
nonce = execjs.eval(nonce) # 通过execjs模块计算js代码
print(data)
print(nonce)
注意:因为nonce是经过计算得来的,所以每次的值并不相同。有时execjs计算可能也会报错抛出异常,再次重新执行请求即可。
JavaScript逆向
成功获取到T参数和N参数两个重要的参数后,可以根据js代码进行逆向。我们可以通过nodejs调用解密,也可以模仿js的逻辑用python进行改写。这里我们使用python代码,对前面解密出来的js代码进行改写:
import requests
import re
import execjs
import json
url = 'https://ac.qq.com/ComicView/index/id/531490/cid/1'
res = requests.get(url).text
data = re.findall("(?<=var DATA = ').*?(?=')", res)[0] # 提取DATA
nonce = re.findall('window\[".+?(?<=;)', res)[0] # 提取window["no"+"nce"]
nonce = '='.join(nonce.split('=')[1:])[:-1] # 掐头去尾
nonce = execjs.eval(nonce) # 通过execjs模块计算js代码
# js逆向
T = list(data)
N = re.findall('\d+[a-zA-Z]+', nonce)
jlen = len(N)
while jlen:
jlen -= 1
jlocate = int(re.findall('\d+', N[jlen])[0]) & 255
jstr = re.sub('\d+', '', N[jlen])
del T[jlocate:jlocate + len(jstr)]
T = ''.join(T)
keyStr = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/="
a = []
e = 0
while e < len(T):
b = keyStr.index(T[e])
e += 1
d = keyStr.index(T[e])
e += 1
f = keyStr.index(T[e])
e += 1
g = keyStr.index(T[e])
e += 1
b = b << 2 | d >> 4
d = (d & 15) << 4 | f >> 2
h = (f & 3) << 6 | g
a.append(b)
if 64 != f:
a.append(d)
if 64 != g:
a.append(h)
_v = json.loads(bytes(a))
print(_v)
此时,解密后的地址都在_v变量里面了。
针对execjs计算时可能会报错抛出异常的问题,需要重新获取源代码请求处理。与此同时,我们用函数对代码段进行封装:
import requests
import re
import execjs
import json
def getdata():
url = 'https://ac.qq.com/ComicView/index/id/531490/cid/1'
while True:
try:
res = requests.get(url).text
data = re.findall("(?<=var DATA = ').*?(?=')", res)[0] # 提取DATA
nonce = re.findall('window\[".+?(?<=;)', res)[0] # 提取window["no"+"nce"]
nonce = '='.join(nonce.split('=')[1:])[:-1] # 掐头去尾
nonce = execjs.eval(nonce) # 通过execjs模块计算js代码
break
except:
pass
# js逆向
T = list(data)
N = re.findall('\d+[a-zA-Z]+', nonce)
jlen = len(N)
while jlen:
jlen -= 1
jlocate = int(re.findall('\d+', N[jlen])[0]) & 255
jstr = re.sub('\d+', '', N[jlen])
del T[jlocate:jlocate + len(jstr)]
T = ''.join(T)
keyStr = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/="
a = []
e = 0
while e < len(T):
b = keyStr.index(T[e])
e += 1
d = keyStr.index(T[e])
e += 1
f = keyStr.index(T[e])
e += 1
g = keyStr.index(T[e])
e += 1
b = b << 2 | d >> 4
d = (d & 15) << 4 | f >> 2
h = (f & 3) << 6 | g
a.append(b)
if 64 != f:
a.append(d)
if 64 != g:
a.append(h)
_v = json.loads(bytes(a))
print(_v)
if __name__ == '__main__':
getdata()
漫画数据解析
在前面的步骤中,通过_v变量已经可以获取到腾讯漫画的url了,所以接下来我们需要对腾讯漫画进行解析。
def parseData(alldata): # 漫画数据解析函数
title = alldata['comic']['title']
chapter = alldata['chapter']['cTitle']
pictures = alldata['picture'] # 取出漫画列表
print(f"腾讯漫画【{title}】-{chapter}")
for picture in pictures:
print(picture['url']) # 输出每个漫画的url
其中,我们需要将腾讯漫画保存到指定的文件夹中,因此需要对文件夹是否存在进行判定,不存在则创建文件夹。最后将爬取到的腾讯漫画url通过二进制形式进行保存:
def parseData(alldata): # 漫画数据解析函数
i = 0
title = alldata['comic']['title']
chapter = alldata['chapter']['cTitle']
pictures = alldata['picture'] # 取出漫画列表
# print(f"腾讯漫画【{title}】-{chapter}")
folder = f"D://WorkSpace/腾讯漫画/{title}/{chapter}"
if not os.path.exists(folder):
os.makedirs(folder)
for picture in pictures:
i = i + 1
f = open(f'{folder}/{title}-{chapter}-{i}.jpg', 'wb')
f.write(requests.get(picture['url']).content) # 二进制图片下载用content
f.close()
print(f"腾讯漫画《{title}》-[{chapter}]下载成功!")
至此,我们已经完成了腾讯漫画的爬取和存储了。
整体代码优化
为了方便用户进行体验、并且能够爬取任意自己想看的腾讯漫画,写死的数据是肯定不行的。所以,我们需要将数据写活,即:死去活来法。
通过对多个不同漫画的url进行分析,我们可以找到相应的规律:
https://ac.qq.com/ComicView/index/id/漫画编号/cid/章节编号
所以,我们可以先对腾讯漫画按照热门人气榜单爬取指定页面的漫画名称和漫画编号,以便于用户一键下载所需要的漫画和章节。
from pyquery import PyQuery as pq
def popularlist(popularity): # 热门人气漫画榜函数
for popularity_i in range(1, int(popularity) + 1):
url = f'https://ac.qq.com/Comic/all/page/{popularity_i}'
res = requests.get(url).text
# print(res)
doc = pq(res)
comics_li = doc('.ret-search-item.clearfix .ret-works-info .ret-works-title.clearfix a').items()
for li in comics_li:
comics_title = li.attr.title # 腾讯漫画名称
comics_href = li.attr.href # 漫画短链接
comics_id = re.match('.*?(\d+)', comics_href) # 漫画id匹配
print(f"{comics_title}: {comics_id.group(1)}")
由于pyinstaller不支持打包pyquery解析库,所以博主后来又将这部分代码用正则表达式进行了改写:
def popularlist(popularity): # 热门人气漫画榜函数
for popularity_i in range(1, int(popularity) + 1):
url = f'https://ac.qq.com/Comic/all/page/{popularity_i}'
res = requests.get(url).text
# print(res)
comics_lists = re.findall('', res)
for comics_list in comics_lists:
print(f"《{comics_list[1]}》漫画编号: {comics_list[0]}")
最后,我们再对调用各个函数的主函数进行优化:
def main(): # 主函数
while True:
scan = input("是否需要查询腾讯动漫的热门人气排行榜?(y/n)")
if scan == "y":
popularity = input("请输入您所需查询的腾讯动漫热门人气榜的页数:")
print("="*30)
print("腾讯动漫热门排行榜如下所示:(漫画名称:漫画ID)")
print("-"*30)
popularlist(popularity)
print("-" * 30)
comics_id = input("请输入漫画编号:") # 漫画ID(一人之下531490)
chapter_id = input("请输入章节ID:") # 章节ID
url = f'https://ac.qq.com/ComicView/index/id/{comics_id}/cid/{chapter_id}'
url_title = re.findall("《(.*?)》(.*?)-.*? ", requests.get(url).text)
if input(f'温馨提示:您想要下载的[{url_title[0][0]}]的章节名称是:[{url_title[0][1]}]。\n按回车键可继续,输入Q可取消下载!') == "Q":
break
alldata = getData(url)
parseData(alldata)
print("="*30)
cont = input("是否继续?(y/n)")
if cont == "n":
break
elif cont == "y":
pass
else:
print("警告:请输入正确的选项!(y/n)")
整体代码
import requests
import re
import execjs
import json
import os
def getData(url): # 漫画数据获取函数
# url = f'https://ac.qq.com/ComicView/index/id/{comics_id}/cid/{chapter_id}'
while True:
try:
res = requests.get(url).text
data = re.findall("(?<=var DATA = ').*?(?=')", res)[0] # 提取DATA
nonce = re.findall('window\[".+?(?<=;)', res)[0] # 提取window["no"+"nce"]
nonce = '='.join(nonce.split('=')[1:])[:-1] # 掐头去尾
nonce = execjs.eval(nonce) # 通过execjs模块计算js代码
break
except:
pass
# js逆向
T = list(data)
N = re.findall('\d+[a-zA-Z]+', nonce)
jlen = len(N)
while jlen:
jlen -= 1
jlocate = int(re.findall('\d+', N[jlen])[0]) & 255
jstr = re.sub('\d+', '', N[jlen])
del T[jlocate:jlocate + len(jstr)]
T = ''.join(T)
keyStr = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/="
a = []
e = 0
while e < len(T):
b = keyStr.index(T[e])
e += 1
d = keyStr.index(T[e])
e += 1
f = keyStr.index(T[e])
e += 1
g = keyStr.index(T[e])
e += 1
b = b << 2 | d >> 4
d = (d & 15) << 4 | f >> 2
h = (f & 3) << 6 | g
a.append(b)
if 64 != f:
a.append(d)
if 64 != g:
a.append(h)
_v = json.loads(bytes(a))
# print(_v)
return _v
def parseData(alldata): # 漫画数据解析函数
i = 0
title = alldata['comic']['title']
chapter = alldata['chapter']['cTitle']
pictures = alldata['picture'] # 取出漫画列表
# print(f"腾讯漫画【{title}】-{chapter}")
folder = f"D://WorkSpace/腾讯漫画/{title}/{chapter}"
if not os.path.exists(folder):
os.makedirs(folder)
for picture in pictures:
# print(requests.get(picture['url']).text.encode())
i = i + 1
f = open(f'{folder}/{title}-{chapter}-{i}.jpg', 'wb')
f.write(requests.get(picture['url']).content) # 二进制图片下载用content
f.close()
print(f"腾讯漫画《{title}》-[{chapter}]下载成功!")
def popularlist(popularity): # 热门人气漫画榜函数
for popularity_i in range(1, int(popularity) + 1):
url = f'https://ac.qq.com/Comic/all/page/{popularity_i}'
res = requests.get(url).text
# print(res)
comics_lists = re.findall('', res)
for comics_list in comics_lists:
print(f"《{comics_list[1]}》漫画编号: {comics_list[0]}")
def main(): # 主函数
while True:
scan = input("是否需要查询腾讯动漫的热门人气排行榜?(y/n)")
if scan == "y":
popularity = input("请输入您所需查询的腾讯动漫热门人气榜的页数:")
print("="*30)
print("腾讯动漫热门排行榜如下所示:(漫画名称:漫画ID)")
print("-"*30)
popularlist(popularity)
print("-" * 30)
comics_id = input("请输入漫画编号:") # 漫画ID(一人之下531490)
chapter_id = input("请输入章节ID:") # 章节ID
url = f'https://ac.qq.com/ComicView/index/id/{comics_id}/cid/{chapter_id}'
url_title = re.findall("《(.*?)》(.*?)-.*? ", requests.get(url).text)
if input(f'温馨提示:您想要下载的[{url_title[0][0]}]的章节名称是:[{url_title[0][1]}]。\n按回车键可继续,输入Q可取消下载!') == "Q":
break
alldata = getData(url)
parseData(alldata)
print("="*30)
cont = input("是否继续?(y/n)")
if cont == "n":
break
elif cont == "y":
pass
else:
print("警告:请输入正确的选项!(y/n)")
if __name__ == '__main__':
main()
Pyinstaller打包
使用命令提示行,可在腾讯漫画爬取程序(TencentComics.py)程序所在文件夹内输入以下指令对Python代码进行打包:
pyinstaller.exe -F TencentComics.py
效果展示

总结
本次爬虫实战所遭遇的反爬虫应该算是典型的签名验证反爬虫了。签名验证反爬虫原理:由客户端生成一些随机值和不可逆的MD5加密字符串,并在发起请求时将这些值发送给服务器端。服务器端使用相同的方式对随机值进行计算以及MD5加密,如果服务器端得到的MD5值与前端提交的MD5值相等,就代表是正常请求,否则返回403。
爬虫学习者面对签名验证反爬虫,必须具备javascript的基础知识。哪怕是博主两年前已经自学完了javascript,面对js逆向还是很容易一脸懵逼。爬虫学习,任重而道远啊!