Neo4j 初识之springboot-neo4j示例
what noe4j
图数据库主要用于存储更多的连接数据。例如这样的数据。一个人的家庭群,和他的朋友圈模型。

像这样,这些应用程序包含大量的结构化,半结构化和非结构化的连接数据。 在RDBMS数据库中表示这种非结构化连接数据并不容易。使用RDBMS数据库来存储更多连接的数据,那么它们不能提供用于遍历大量数据的适当性能。 在这些情况下,Graph Database提高了应用程序性能。
Neo4j的特点
- SQL就像简单的查询语言Neo4j CQL
- 它遵循属性图数据模型
- 它通过使用Apache Lucence支持索引
- 它支持UNIQUE约束
- 它它包含一个用于执行CQL命令的UI:Neo4j数据浏览器
- 它支持完整的ACID(原子性,一致性,隔离性和持久性)规则
- 它采用原生图形库与本地GPE(图形处理引擎)
- 它支持查询的数据导出到JSON和XLS格式
- 它提供了REST API,可以被任何编程语言(如Java,Spring,Scala等)访问
- 它提供了可以通过任何UI MVC框架(如Node JS)访问的Java脚本
- 它支持两种Java API:Cypher API和Native Java API来开发Java应用程序
Neo4j的优点
- 它很容易表示连接的数据
- 检索/遍历/导航更多的连接数据是非常容易和快速的
- 它非常容易地表示半结构化数据
- Neo4j CQL查询语言命令是人性化的可读格式,非常容易学习
- 它使用简单而强大的数据模型
- 它不需要复杂的连接来检索连接的/相关的数据,因为它很容易检索它的相邻节点或关系细节没有连接或索引
Neo4j的缺点或限制
- AS的Neo4j 2.1.3最新版本,它具有支持节点数,关系和属性的限制。
- 它不支持Sharding。
属性图模型规则
Neo4j图数据库遵循属性图模型来存储和管理其数据。
- 节点和关系都包含属性
- 关系连接节点
- 属性是键值对(例如“name:abc”)
- 节点用圆圈表示,关系用方向键表示。
- 关系具有方向:单向和双向。
- 每个关系包含“开始节点”或“从节点”和“到节点”或“结束节点”
图形数据库数据模型的主要构建块是:
- 节点
- 关系
- 属性
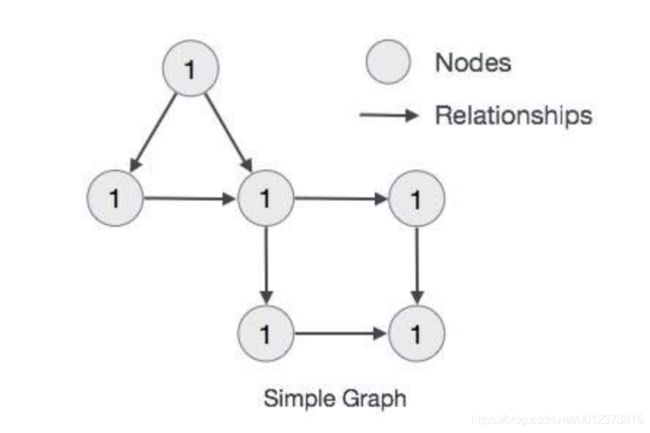
这里我们使用圆圈表示节点。 使用箭头的关系。 关系是有方向性的。 我们可以用Properties(键值对)来表示Node的数据。 在这个例子中,我们在Node的Circle中表示了每个Node的Id属性。
MAC 安装noe4j
下载 https://neo4j.com/download/
//解压
tar -xf neo4j-community-3.4.10-unix.tar.gz
//启动
/bin/neo4j start
//后台启动
nohup bin/neo4j start >> /tmp/neo4j.log 2>&1 &
操作
CQL代表Cypher查询语言。 像Oracle数据库具有查询语言SQL,Neo4j具有CQL作为查询语言。下面我们来实际操作一波。
访问http://localhost:7474/browser/ 进入控制台。
密码默认是neo4j,登录过后会让你修改密码
CREATE
CREATE (abel:Abel{name:"yang",age:26,phone:133333})
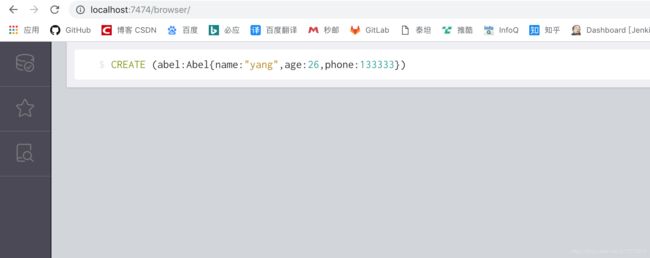

此命令已创建一个具有3个属性(“name”,“age”,“phone”)的节点名称“abel”,并分配了一个标签“Abel”。
可以创建多个 节点名称、节点标签、所有属性及属性值都相同的节点。
在Neo4j中,内部有个Id属性,“Id”是节点和关系的默认内部属性。 这意味着,当我们创建一个新的节点或关系时,Neo4j数据库服务器将为内部使用分配一个数字。 它会自动递增。
MATCH
我们需要使用MATCH命令与RETURN子句查询或更新子句
MATCH (abel:Abel) RETURN abel //查询节点全部信息
MATCH (abel:Abel) RETURN abel.name // 查询节点的name属性值
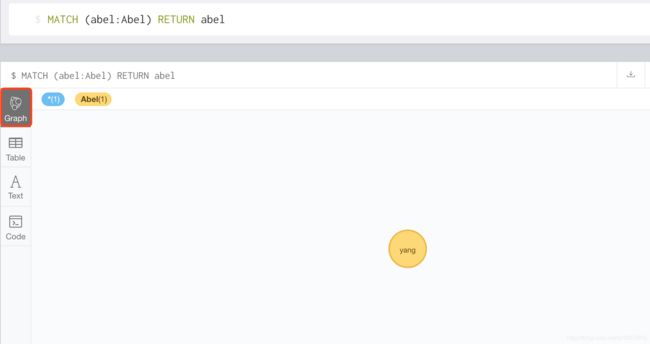
return
RETURN子句。我们应该既MATCH使用或CREATE命令。
关系
关系是定向的基于方向性,Neo4j关系被分为两种主要类型。
- 单向关系
- 双向关系
在以下场景中,我们可以使用Neo4j CQL CREATE命令来创建两个节点之间的关系。 这些情况适用于Uni和双向关系。
在两个现有节点之间创建无属性的关系
在两个现有节点之间创建与属性的关系
在两个新节点之间创建无属性的关系
在两个新节点之间创建与属性的关系
在具有WHERE子句的两个退出节点之间创建/不使用属性的关系
每个关系(→)包含两个节点
- 从节点
- 到节点
创建关系
先再创建一个节点 CREATE (an:an{name:“an”,sex:“女”})
//无属性的关系
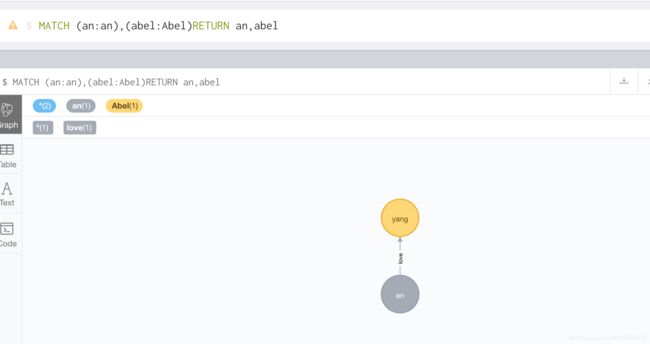
MATCH (an:an),(abel:Abel) CREATE (an) - [l:love] ->(abel)
//有属性的关系 stopdate 为属性名
MATCH (an:an),(abel:Abel) CREATE (an) - [l:love{stopdate:12/12/2100}] ->(abel)

已有两个节点 an 和 abel 创建关系,关系名称为love 关系标签为 l 方向为 an 到 abel
查询一下看一下
创建新节点同时创建关系
//无属性的新节点到已有节点创建无属性关系
MATCH(abel:Abel) CREATE (tian:tian)-[like:LIKES]->(abel)
//有属性的新节点到已有节点创建无属性关系
MATCH(abel:Abel) CREATE (tian:tian{name:"tians",age:23,sex:"女"})-[like:LIKES]->(abel)
//有属性的新节点到已有节点创建有属性的关系
MATCH(abel:Abel) CREATE (tian:tian{name:"tians",age:23,sex:"女"})-[like:LIKES{stopdate:12/12/2100}]->(abel)
//无属性的新节点到新节点创建无属性关系
CREATE (TT:tian)-[like:LIKES]->(long:LONG)
//有属性的新节点到新节点创建无属性关系
CREATE (TT:tian{name:"tians",age:24,sex:"女"})-[like:LIKES]->(long:LONG{name:"long",age:25,sex:"男"})
//无属性的新节点到新节点创建有属性关系
CREATE (TT:tian{name:"tians",age:24,sex:"女"})-[like:LIKES{stopdate:12/12/2100}]->(long:LONG{name:"long",age:25,sex:"男"})
where
支持的布尔运算符 AND,OR,NOT,XOR 支持以下的比较运算符 =,<>,<,>,<=,>=
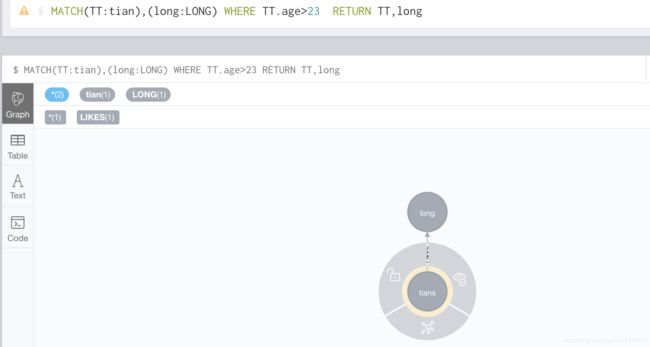
MATCH(TT:tian),(long:LONG) WHERE TT.age>23 RETURN TT,long
DELETE
如果删除的节点有关系的话得先删除关系
//删除关系
MATCH (TT:tian)-[like]-(long:LONG) DELETE like
//删除节点
MATCH(TT:tian) DELETE TT
//也可以与where 结合使用
MATCH(TT:tian) where TT.age>23 RETURN TT
REMOVE
有时基于我们的客户端要求,我们需要向现有节点或关系添加或删除属性。
我们使用Neo4j CQL SET子句向现有节点或关系添加新属性。
我们使用Neo4j CQL REMOVE子句来删除节点或关系的现有属性。
###DELETE和REMOVE命令之间的主要区别
两个命令都应该与MATCH命令一起使用。
- DELETE操作用于删除节点和关联关系。
- REMOVE操作用于删除标签和属性。
使用逗号(,)运算符来分隔标签名称列表。使用dot(。)运算符来分隔节点名称和标签名称。
//删除节点的属性sex
MATCH(TT:tian) REMOVE TT.sex RETURN TT
//
MATCH(long:LONG) REMOVE long:Picture
set
我们需要向现有节点或关系添加新属性。
//节点添加属性,多个属性中间用, 隔开
match(a:a) set a.phone =234324234234 return a
order by
//“ORDER BY”子句,对MATCH查询返回的结果进行排序。可以按升序或降序进行排序。
MATCH (abel:Abel) RETURN abel order by abel.age DESC
与SQL一样,Neo4j CQL有两个子句,将两个不同的结果合并成一组结果
neo4j 还支持 UNION ,UNION ALL,LIMIT,skip,MERGE,IS NOT NULL,in等关键字
更多操作示例
-
创建节点
//创建两个节点无属性,创建关系无属性, $ CREATE (abel:NAME)-[name:colleague]->(eiva:NAME) RETURN abel,eiva //创建节点有属性,创建关系有属性 $ CREATE (abel:column{id:2,name:'abel'})-[name:colleague{id:1,name:'colleague'}]->(eiva:NAME{id:221,name:'eiva'}) RETURN abel,eiva -
查询指定节点
//查询节点类型为 column ,id =221的节点 $ MATCH (n:column) where n.id = 221 RETURN n LIMIT 1 //查询节点类型为 column ,id =221节点的名字属性 $ MATCH (n:column{id:221}) RETURN n.name LIMIT 1 //查询节点类型为 column ,id =222 和 id =2 的节点 $ MATCH (n:column{id:2}), (y:column{id:222}) RETURN n,y LIMIT 1 -
查询两个现有节点创建关系
//现有节点 创建无属性关系 //查询两个类型为column且 id = 2 和 id =221 的节点,并创建 n -> x 的关系 dataRel,关系类型为 DATA。并返回 n 和 x 节点 $ MATCH (n:column{id:2}), (x:column{id:221}) create (n)-[dataRel:DATA]->(x) RETURN n,x LIMIT 1 //当然也可以只创建不返回 $ MATCH (n:column{id:2}), (x:column{id:221}) create (n)-[dataRel:DATA]->(x) //现有节点 创建有属性关系 //查询两个类型为column且 id = 2 和 id =221 的节点,并创建 n -> x 的关系 dataRel,关系类型为 DATA,属性为 id 和 name。并返回 n 和 x 节点 $ MATCH (n:column{id:2}), (x:column{id:222}) create (n)-[dataRel:DATA{id:1,name:'数据'}]->(x) RETURN n,x LIMIT 1 //查询多层节点关系,通过当前国王的名字查询下一任国王和皇后 match p=(a:King)-[r:`传位`]->(b:King)-[r2:`皇后`*1..]->(c:Queen) where a.name ='朱祁镇' return p -
更新信息
//更新节点信息 MATCH (n:column{id:2}) SET n.comment = '测试数据' //更新关系 (关系有唯一id) MATCH (n)-[r:BusinessRelation{id:'rel_col_88'}]->(y) set r.comment= '测试2' RETURN n,y LIMIT 25 //更新关系 多个属性 MATCH (n)-[r:BusinessRelation{id:'rel_col_88'}]->(y) set r.comment= '测试2', r.type= 2 RETURN n,y LIMIT 25 //更新关系信息,关系无唯一id MATCH (n:BusinessColumn{id:'col_1'}),(y:BusinessColumn{id:'col_2'}) MATCH (n)-[r:BusinessRelation{name:'测试'}]->(y) set r.comment= '测试1' RETURN n,y LIMIT 25 -
删除关系
//删除一个关系 Match (n)-[r:BusinessRelation{id:'rel_col_88'}]-(y) delete r -
清空数据库
//删除节点 MATCH (n:King) DELETE n //删除关系和节点 MATCH (n:King)-[r]-() DELETE n,r
springboot-neo4j 示例代码 点我
包含 springboot-data-neo4j 和 Cypher 语言操作两种方式
参考:https://www.w3cschool.cn/neo4j/neo4j_id_property.html