android基础之创建和解析xml
Android 是最常用的智能手机平台,XML 是数据交换的标准媒介,Android 中可以使用标准的XML生成器、解析器、转换器 API,对 XML 进行解析和转换。
XML,相关有DOM、SAX、JDOM、DOM4J、Xerces、JAXP等一堆概念,但是很多人总是会弄混他们之间的关系,这对我们理解XML文件的创建和解析很不利。要挑选一个适合在Android平台上使用的XML解析方案,我们还是得先把这些概念厘清。
DOM(Document Object Model,文档对象模型)和SAX(Simple API for XML,简单XML应用接口),是JAXP(Java API for XML Processing,Java XML处理的应用接口)定义的2种不同的对XML文档进行分析、处理的方法。
DOM方法是用标准对象模型表示 XML 文档;SAX方法则使用事件模型来处理程序来处理XML。
JAXP完成了对SAX、DOM的包装,它向应用程序提供针对DOM的DocumentBuilderFactory、 DocumentBuilder;以及针对SAX的SAXParserFactory、SAXParser抽象工厂类。在Jave SE中JAXP对应javax.xml.parsers包,DOM对应org.w3c.dom,SAX对应org.xml.sax。
Xerces 首先继承并实现了javax.xml.parser包内的SAXParser、SAXParserFactory、DocumentBuilder、DocumentBuilderFactory等抽象类,并提供了JAXP中所定义的DOM、SAX(以及StAX,后面会介绍)这些XML解析方法的实现和相应的Parser。
JDOM和DOM4J,是因为有人觉得W3C的DOM标准API太过难用而着手开发的替代API,它们和JAXP一样都是对DOM、SAX的封装,不过JDOM、DOM4J做了更多的事情,相当于上面提到JAXP接口+Xerces DOM实现部分。JDOM并没有自己开发Parser,所以还是需要利用Xerces的Parser部分,而DOM4J自带一个名为Alfred2的Parser,当然也可以使用Xerces的Parser。看起来JAXP具备更好的可移植性,即我们可以通过修改配置文件切换不同的DOM实现和SAX、DOM Parser,JDOM、DOM4J虽然也可以切换Parser,但是DOM实现是无法切换的。(参考: Java XML API 漫谈 和 JAXP全面介绍)
XML创建与解析
XML创建主要四种方式:Dom、Sax、Pull、Dom4j
XML解析主要四种方式:Dom、Sax、Pull、Dom4j
其中,利用Dom、Sax、Pull、Dom4j创建的标准XML格式文件,可以由任何一种Dom、Sax、Pull、Dom4j解析方式进行解析。
Android中解析XML
DOM解析器, 是通过将XML文档解析成树状模型并将其放入内存来完成解析工作的,然后对文档的操作都是在这个树状模型上完成的。这个在内存中的文档树将是文档实际大小的几倍。这样做的好处是结构清晰、操作方便,而带来的麻烦就是极其耗费系统资源。SAX解析器 ,正好克服了DOM的缺点,分析能够立即开始,而不是等待所有的数据被处理。而且,由于应用程序只是在读取数据时检查数据,因此不需要将数据存储在内存中,这对于大型文档来说是个巨大的优点。事实上,应用程序甚至不必解析整个文档,它可以在某个条件得到满足时停止解析。
DOM与SAX比较
下面的表格列出了SAX和DOM在一些方面的对照:
| SAX | DOM |
| 顺序读入文档并产生相应事件,可以处理任何大小的XML文档 | 在内存中创建文档树,不适于处理大型XML文档。 |
| 只能对文档按顺序解析一遍,不支持对文档的随意访问。 | 可以随意访问文档树的任何部分,没有次数限制。 |
| 只能读取XML文档内容,而不能修改 | 可以随意修改文档树,从而修改XML文档。 |
| 开发上比较复杂,需要自己来实现事件处理器。 | 易于理解,易于开发。 |
| 对开发人员而言更灵活,可以用SAX创建自己的XML对象模型。 | 已经在DOM基础之上创建好了文档树。 |
通过对SAX和DOM的分析,它们各有自己的不同应用领域:
SAX适于处理下面的问题:- 对大型文档进行处理。
- 只需要文档的部分内容,或者只需要从文档中得到特定信息。
- 想创建自己的对象模型的时候。
DOM适于处理下面的问题:
- 需要对文档进行修改
- 需要随机对文档进行访问,例如XSLT解析器。
1、数据修改:如果打算 对数据作出更改并将它输出为 XML ,那么在大多数情况下,DOM 是适当的选择。并不是说使用 SAX 就不能更改数据,但是该过程要复杂得多,因为您必须对数据的一份拷贝而不是对数据本身作出更改。
2、数据容量: 对于 大型文件 ,SAX 是更好的选择。
3、数据使用:如果只有 数据中的少量部分会被使用 ,那么使用 SAX 来将该部分数据提取到应用程序中可能更好。 另一方面,如果您知道自己以后会回头引用已处理过的大量信息,那么 SAX 也许不是恰当的选择。
4、速度要求: SAX 实现通常要比 DOM 实现 速度更快 。
基于上面的分析,在基于Android系统的内存和CPU资源比较有限的手持设备上,只要我们不需要修改XML数据或者随机的访问XML数据,SAX尽管可能需要更多的编码工作,但是为了更小的内存和CPU消耗,还是值得的。
另外,Android SDK中已经包含了JAXP对应的javax.xml.parsers包,SAX对应org.xml.sax,DOM对应的org.w3c.dom包,加上Android还提供了android.sax这样的包来方便SAX Handle的开发,基于JAXP和SAX这样的标准方法来开发不仅复杂度不高,即使出现问题在讨论组中寻求解决方案也是比较容易的。(参考: 使用 SAX 处理 XML 文档 和 DOM SAX JAXP DOM4J JDOM xerces解析器 )
Android中解析XML实现
基于上面的分析,采用JAXP+SAX的方案是我比较看好的。我们首先需要又一个SAXParserFactory的实例,然后从工厂中得到一个SAXParser实例,进而获取一个XMLReader;接下来新建一个Handler类继承自SAX Helpler的DefaultHandler,并实现startDocument()、startElement()、endElement()以及endDocument()等方法,并把这个Handler作为XMLReader的Content Handler;最后以带解析的XML文档为参数调用XMLReader的parse方法即可。具体的代码参考:Android 上使用 XML 和 Android 3.0 平台上创建和解析 XML
Android SDK中包含了 JAXP 对应javax.xml.parsers包, SAX 对应的org.xml.sax, DOM 对应的org.w3c.dom包,所以我们就已经有了XML解析所需的JAXP——对SAX和DOM的封装(抽象类)以及SAX和DOM接口类,但是对于JAXP抽象类的实现,以及DOM和SAX接口类的实现在哪里呢?是和Java SE 5.0一样用了Xerces吗? 不!
通过查看Android 1.5的源代码,我看到这部分的代码来自Apache Harmony这个开源的Java SE实现,位于./dalvik/libcore/xml/src/main/java/org/apache/harmony/xml目录。这里包含有一个完整的DOM实现(dom目录),对于javax.xml.parser下的抽象类的实现(parser目录),以及对于SAX接口类的实现(除此以外还包括对XMLPullParser接口的实现)。
2、XmlPull 和 KXML2
XmlPull解析器, 提供了资源有限的环境(如J2ME)应用使用的XML解析API,XPP提供了非常简单的接口——包含一个接口、一个异常、一个建立解析器的factory。它采用了类似JAXP的工厂模式,把接口设计和实现分离,KXML2就是一个为J2ME环境优化的一个实现。在Android SDK中,已经包含了XmlPull(org.xmlpull.v1包)以及它的一个AddOn——SAX2 Driver——它使得我们可以通过SAX2的API来操纵XmlPull Parser。另外,通过sourcecode,我们可以看到Android SDK中的XmlPull的实现是KXML2,位于./dalvik/libcore/xml/src/main/java/org/kxml2目录。Apache Harmony的目录中同样有一个ExpatPullParser类实现了XMLPullParser接口,但是却没有XmlSerializer接口的实现,所以只能说Android中的Harmony也部分实现了XmlPull API。XmlPull+KXML2是下一步我要实践的方案,到时候还得学习一下如何“公平”的比较两者的性能。
3、StAX
尽管Android中还没有提供相应的支持,但是Streaming API for XML (StAX) 作为用Java语言处理 XML的最新标准,无论从性能还是可用性上都有出色的表现。它不仅提供了一个快捷、易用、占用内存少的 XML 解析器,它还提供了过滤器接口,允许程序员向应用程序业务逻辑隐藏不需要的文档细节。感兴趣的朋友可以看一看下面的文章。
使用 StAX 解析 XML,第 1 部分: Streaming API for XML (StAX) 简介
使用 StAX 解析 XML,第 2 部分: 拉式解析和事件
使用 StAX 解析 XML,第 3 部分: 使用定制事件和编写 XML
参考推荐:
Android中解析XML数据
android解析XML总结(SAX、Pull、Dom三种方式)
Android 解析XML文件的三种方式 DOM,SAX,PULL
android解析xml文件的方式(推荐,共三篇)
Android 上使用 XML
Android 上使用 XML 和 JSON
Android 3.0 平台上创建和解析 XML
Android XML解析学习——创建XML(共六篇,推荐)
Android 创建与解析XML(二)—— Dom方式
1. Dom概述
Dom方式创建XML,应用了标准xml构造器 javax.xml.parsers.DocumentBuilder 来创建 XML 文档,需要导入以下内容
javax.xml.parsers
javax.xml.transformjavax.xml.parsers.DocumentBuilder
javax.xml.parsers.DocumentBuilderFactory
javax.xml.parsers.ParserConfigurationException;
javax.xml.transform.TransformerFactory
javax.xml.transform.Transformer
javax.xml.transform.dom.DOMSource
javax.xml.transform.stream.StreamResult
javax.xml.transform.OutputKeys;
javax.xml.transform.TransformerFactoryConfigurationError;
javax.xml.transform.TransformerConfigurationException;
javax.xml.transform.TransformerException;
org.w3c.dom
org.w3c.dom.Document;
org.w3c.dom.Element;
org.w3c.dom.Node;
org.w3c.dom.DOMException;
org.w3c.dom.NodeList;
org.xml.sax.SAXException;
sdk源码查看路径(google code)
创建和解析xml的效果图:
2、Dom 创建 XML
Dom,借助 javax.xml.parsers.DocumentBuilder,可以创建 org.w3c.dom.Document 对象。
使用来自 DocumentBuilderFactory 的 DocumentBuilder 对象在 Android 设备上创建与解析 XML 文档。您将使用 XML pull 解析器的扩展来解析 XML 文档。
Code
- /** Dom方式,创建 XML */
- public String domCreateXML() {
- String xmlWriter = null;
- Person []persons = new Person[3]; // 创建节点Person对象
- persons[0] = new Person(1, "sunboy_2050", "http://blog.csdn.net/sunboy_2050");
- persons[1] = new Person(2, "baidu", "http://www.baidu.com");
- persons[2] = new Person(3, "google", "http://www.google.com");
- try {
- DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
- DocumentBuilder builder = factory.newDocumentBuilder();
- Document doc = builder.newDocument();
- Element eleRoot = doc.createElement("root");
- eleRoot.setAttribute("author", "homer");
- eleRoot.setAttribute("date", "2012-04-26");
- doc.appendChild(eleRoot);
- int personsLen = persons.length;
- for(int i=0; i
- Element elePerson = doc.createElement("person");
- eleRoot.appendChild(elePerson);
- Element eleId = doc.createElement("id");
- Node nodeId = doc.createTextNode(persons[i].getId() + "");
- eleId.appendChild(nodeId);
- elePerson.appendChild(eleId);
- Element eleName = doc.createElement("name");
- Node nodeName = doc.createTextNode(persons[i].getName());
- eleName.appendChild(nodeName);
- elePerson.appendChild(eleName);
- Element eleBlog = doc.createElement("blog");
- Node nodeBlog = doc.createTextNode(persons[i].getBlog());
- eleBlog.appendChild(nodeBlog);
- elePerson.appendChild(eleBlog);
- }
- Properties properties = new Properties();
- properties.setProperty(OutputKeys.INDENT, "yes");
- properties.setProperty(OutputKeys.MEDIA_TYPE, "xml");
- properties.setProperty(OutputKeys.VERSION, "1.0");
- properties.setProperty(OutputKeys.ENCODING, "utf-8");
- properties.setProperty(OutputKeys.METHOD, "xml");
- properties.setProperty(OutputKeys.OMIT_XML_DECLARATION, "yes");
- TransformerFactory transformerFactory = TransformerFactory.newInstance();
- Transformer transformer = transformerFactory.newTransformer();
- transformer.setOutputProperties(properties);
- DOMSource domSource = new DOMSource(doc.getDocumentElement());
- OutputStream output = new ByteArrayOutputStream();
- StreamResult result = new StreamResult(output);
- transformer.transform(domSource, result);
- xmlWriter = output.toString();
- } catch (ParserConfigurationException e) { // factory.newDocumentBuilder
- e.printStackTrace();
- } catch (DOMException e) { // doc.createElement
- e.printStackTrace();
- } catch (TransformerFactoryConfigurationError e) { // TransformerFactory.newInstance
- e.printStackTrace();
- } catch (TransformerConfigurationException e) { // transformerFactory.newTransformer
- e.printStackTrace();
- } catch (TransformerException e) { // transformer.transform
- e.printStackTrace();
- } catch (Exception e) {
- e.printStackTrace();
- }
- savedXML(fileName, xmlWriter.toString());
- return xmlWriter.toString();
- }
运行结果:
3、Dom 解析 XML
Dom方式,解析XML是创建XML的逆过程,主要用到了builder.parse(is)进行解析,然后通过Tag、NodeList、Element、childNotes等得到Element和Node属性或值。
Code
- /** Dom方式,解析 XML */
- public String domResolveXML() {
- StringWriter xmlWriter = new StringWriter();
- InputStream is= readXML(fileName);
- try {
- DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
- DocumentBuilder builder = factory.newDocumentBuilder();
- Document doc = builder.parse(is);
- doc.getDocumentElement().normalize();
- NodeList nlRoot = doc.getElementsByTagName("root");
- Element eleRoot = (Element)nlRoot.item(0);
- String attrAuthor = eleRoot.getAttribute("author");
- String attrDate = eleRoot.getAttribute("date");
- xmlWriter.append("root").append("\t\t");
- xmlWriter.append(attrAuthor).append("\t");
- xmlWriter.append(attrDate).append("\n");
- NodeList nlPerson = eleRoot.getElementsByTagName("person");
- int personsLen = nlPerson.getLength();
- Person []persons = new Person[personsLen];
- for(int i=0; i
- Element elePerson = (Element) nlPerson.item(i); // person节点
- Person person = new Person(); // 创建Person对象
- NodeList nlId = elePerson.getElementsByTagName("id");
- Element eleId = (Element)nlId.item(0);
- String id = eleId.getChildNodes().item(0).getNodeValue();
- person.setId(Integer.parseInt(id));
- NodeList nlName = elePerson.getElementsByTagName("name");
- Element eleName = (Element)nlName.item(0);
- String name = eleName.getChildNodes().item(0).getNodeValue();
- person.setName(name);
- NodeList nlBlog = elePerson.getElementsByTagName("blog");
- Element eleBlog = (Element)nlBlog.item(0);
- String blog = eleBlog.getChildNodes().item(0).getNodeValue();
- person.setBlog(blog);
- xmlWriter.append(person.toString()).append("\n");
- persons[i] = person;
- }
- } catch (ParserConfigurationException e) { // factory.newDocumentBuilder
- e.printStackTrace();
- } catch (SAXException e) { // builder.parse
- e.printStackTrace();
- } catch (IOException e) { // builder.parse
- e.printStackTrace();
- } catch (Exception e) {
- e.printStackTrace();
- }
- return xmlWriter.toString();
- }
运行结果:
4、Person类
Person类,是创建xml的单位实例,基于Java面向对象定义的一个类
- public class Person {
- private int id;
- private String name;
- private String blog;
- public Person() {
- this.id = -1;
- this.name = "";
- this.blog = "";
- }
- public Person(int id, String name, String blog) {
- this.id = id;
- this.name = name;
- this.blog = blog;
- }
- public Person(Person person) {
- this.id = person.id;
- this.name = person.name;
- this.blog = person.blog;
- }
- public Person getPerson(){
- return this;
- }
- public void setId(int id) {
- this.id = id;
- }
- public int getId(){
- return this.id;
- }
- public void setName(String name) {
- this.name = name;
- }
- public String getName() {
- return this.name;
- }
- public void setBlog(String blog) {
- this.blog = blog;
- }
- public String getBlog() {
- return this.blog;
- }
- public String toString() {
- return "Person \nid = " + id + "\nname = " + name + "\nblog = " + blog + "\n";
- }
- }
代码下载
参考推荐:
org.w3c.dom
javax.xml.parsers
javax.xml.transform
dom创建xml
java dom创建xml
Android 创建与解析XML(三)—— Sax方式
1. Sax概述
startDocument():当遇到文档的时候就触发这个事件 调用这个方法 可以在其中做些预处理工作,如:申请对象资源
startElement(String namespaceURI, String localName, String qName, Attributes atts):当遇开始标签的时候就会触发这个方法。
endElement(String uri, String localName, String name):当遇到结束标签时触发这个事件,调用此法可以做些善后工作。
charachers(char [] ch, int start, int length):当遇到xml内容时触发这个方法,用new String(ch,start,length)可以接受内容。
javax.xml.transform
javax.xml.transform.sax.SAXTransformerFactory;
javax.xml.transform.sax.TransformerHandler;
javax.xml.transform.Transformer;javax.xml.transform.TransformerConfigurationException;javax.xml.transform.TransformerFactoryConfigurationError;javax.xml.transform.OutputKeys;
javax.xml.transform.stream.StreamResult;
javax.xml.transform.sax.SAXTransformerFactory;
javax.xml.parsers
javax.xml.parsers.SAXParser;
javax.xml.parsers.SAXParserFactory;
javax.xml.parsers.FactoryConfigurationError;
javax.xml.parsers.ParserConfigurationException;
org.xml.sax
org.xml.sax.Attributes;org.xml.sax.SAXException;
org.xml.sax.helpers.AttributesImpl;
org.xml.sax.helpers.DefaultHandler;
sdk源码查看路径(google code)
Sax 创建和解析 XML 的效果图:
2、Sax 创建 XML
首先,SAXTransformerFactory.newInstance() 创建一个工厂实例 factory
接着,factory.newTransformerHandler() 获取 TransformerHandler 的 handler 对象
然后,通过 handler 事件创建handler.getTransformer()、 handler.setResult(result),以及 startDocument()、startElement、characters、endElement、endDocument()等
Code
- /** Sax方式,创建 XML */
- public String saxCreateXML(){
- StringWriter xmlWriter = new StringWriter();
- Person []persons = new Person[3]; // 创建节点Person对象
- persons[0] = new Person(1, "sunboy_2050", "http://blog.csdn.net/sunboy_2050");
- persons[1] = new Person(2, "baidu", "http://www.baidu.com");
- persons[2] = new Person(3, "google", "http://www.google.com");
- try {
- SAXTransformerFactory factory = (SAXTransformerFactory)SAXTransformerFactory.newInstance();
- TransformerHandler handler = factory.newTransformerHandler();
- Transformer transformer = handler.getTransformer(); // 设置xml属性
- transformer.setOutputProperty(OutputKeys.INDENT, "yes");
- transformer.setOutputProperty(OutputKeys.ENCODING, "utf-8");
- transformer.setOutputProperty(OutputKeys.VERSION, "1.0");
- StreamResult result = new StreamResult(xmlWriter); // 保存创建的xml
- handler.setResult(result);
- handler.startDocument();
- AttributesImpl attr = new AttributesImpl();
- attr.clear();
- attr.addAttribute("", "", "author", "", "homer");
- attr.addAttribute("", "", "date", "", "2012-04-27");
- handler.startElement("", "", "root", attr);
- int personsLen = persons.length;
- for(int i=0; i
- attr.clear();
- handler.startElement("", "", "person", attr);
- attr.clear();
- handler.startElement("", "", "id", attr);
- String id = persons[i].getId() + "";
- handler.characters(id.toCharArray(), 0, id.length());
- handler.endElement("", "", "id");
- attr.clear();
- handler.startElement("", "", "name", attr);
- String name = persons[i].getName();
- handler.characters(name.toCharArray(), 0, name.length());
- handler.endElement("", "", "name");
- attr.clear();
- handler.startElement("", "", "blog", attr);
- String blog = persons[i].getBlog();
- handler.characters(blog.toCharArray(), 0, blog.length());
- handler.endElement("", "", "blog");
- handler.endElement("", "", "person");
- }
- handler.endElement("", "", "root");
- handler.endDocument();
- } catch (TransformerFactoryConfigurationError e) { // SAXTransformerFactory.newInstance
- e.printStackTrace();
- } catch (TransformerConfigurationException e) { // factory.newTransformerHandler
- e.printStackTrace();
- } catch (IllegalArgumentException e) { // transformer.setOutputProperty
- e.printStackTrace();
- } catch (SAXException e) { // handler.startDocument
- e.printStackTrace();
- } catch (Exception e) {
- e.printStackTrace();
- }
- savedXML(fileName, xmlWriter.toString());
- return xmlWriter.toString();
- }
运行结果:
3、Sax解析XML
Code
- /** Sax方式,解析 XML */
- public String saxResolveXML(){
- StringWriter xmlWriter = new StringWriter();
- InputStream is = readXML(fileName);
- try {
- SAXParserFactory factory = SAXParserFactory.newInstance();
- SAXParser saxParser = factory.newSAXParser();
- PersonHandler handler = new PersonHandler(); // person处理Handler
- saxParser.parse(is, handler); // handler解析xml
- // 获取解析的xml
- String xmlHeader = handler.getXMLHeader();
- xmlWriter.append(xmlHeader);
- List
personsList = handler.getPersons(); - int personsLen = personsList.size();
- for(int i=0; i
- xmlWriter.append(personsList.get(i).toString()).append("\n");
- }
- } catch (FactoryConfigurationError e) { // SAXParserFactory.newInstance
- e.printStackTrace();
- } catch (ParserConfigurationException e) { // factory.newSAXParser
- e.printStackTrace();
- } catch (SAXException e) { // factory.newSAXParser
- e.printStackTrace();
- } catch (IllegalArgumentException e) { // saxParser.parse
- e.printStackTrace();
- } catch (IOException e) { // saxParser.parse
- e.printStackTrace();
- } catch (Exception e) {
- e.printStackTrace();
- }
- return xmlWriter.toString();
- }
- /** Handler处理类 */
- private final class PersonHandler extends DefaultHandler{
- private List
personsList = null; // 保存person - private Person person = null;
- private StringBuffer xmlHeader; // 保存xml头部信息
- private String tag = null; // xml Element
- /** 返回解析的xml头部信息 */
- public String getXMLHeader(){
- return xmlHeader.toString();
- }
- /** 返回解析的Person实例数组 */
- public List
getPersons(){ - return personsList;
- }
- @Override
- public void startDocument() throws SAXException{
- super.startDocument();
- personsList = new ArrayList
(); - xmlHeader = new StringBuffer();
- }
- @Override
- public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException{
- super.startElement(uri, localName, qName, attributes);
- if("root".equals(localName)) {
- String attrAuthor = attributes.getValue(0);
- String attrDate = attributes.getValue(1);
- xmlHeader.append("root").append("\t\t");
- xmlHeader.append(attrAuthor).append("\t");
- xmlHeader.append(attrDate).append("\n");
- } else if("person".equals(localName)) {
- person = new Person();
- }
- tag = localName;
- }
- @Override
- public void characters(char[] ch, int start, int length) throws SAXException {
- super.characters(ch, start, length);
- if (null != tag) {
- String value = new String(ch, start, length);
- System.out.println("value = " + value);
- if ("id".equals(tag)) {
- person.setId(new Integer(value));
- } else if ("name".equals(tag)) {
- person.setName(value);
- } else if ("blog".equals(tag)) {
- person.setBlog(value);
- }
- }
- }
- @Override
- public void endElement(String uri, String localName, String qName) throws SAXException {
- if("person".equals(qName)) {
- personsList.add(person);
- person = null;
- }
- tag = null;
- super.endElement(uri, localName, qName);
- }
- @Override
- public void endDocument() throws SAXException{
- // personsList = null;
- super.endDocument();
- }
- }
运行结果:
4、Person类
请参见前面博客 Android 创建与解析XML(二)—— Dom方式 【4、Person类】
Android 创建与解析XML(四)—— Pull方式
1、Pull概述
Android系统中和创建XML相关的包为org.xmlpull.v1,在这个包中不仅提供了用于创建XML的 XmlSerializer,还提供了用来解析XML的Pull方式解析器 XmlPullParser
XmlSerializer没有像XmlPullParser那样提取XML事件,而是把它们推出到数据流OutputStream或Writer中。
XmlSerializer提供了很直观的API,即使用startDocument开始文档,endDocument结束文档,startTag开始元素,endTag结束元素,text添加文本等。
Pull方式创建XML,应用了标准xml构造器 org.xmlpull.v1.XmlSerializer来创建 XML ,org.xmlpull.v1.XmlPullParser来解析XML,需要导入以下内容
org.xmlpull.v1
org.xmlpull.v1.XmlPullParser;
org.xmlpull.v1.XmlPullParserException;
org.xmlpull.v1.XmlPullParserFactory;
org.xmlpull.v1.XmlSerializer;
sdk源码查看路径(google code)
Pull 创建和解析 XML 的效果图:
2、Pull 创建 XML
pull方式,创建xml是通过 XmlSerializer 类实现
首先,通过XmlSerializer得到创建xml的实例 xmlSerializer
接着,通过 xmlSerializer 设置输出 xmlSerializer.setOutput,xmlSerializer.startDocument("utf-8", null)设置xml属性等
然后,通过 xmlSerializer 创建 startDocument、startTag、text、endTag、endDocument等
Code
- /** Pull方式,创建 XML */
- public String pullXMLCreate(){
- StringWriter xmlWriter = new StringWriter();
- Person []persons = new Person[3]; // 创建节点Person对象
- persons[0] = new Person(1, "sunboy_2050", "http://blog.csdn.net/sunboy_2050");
- persons[1] = new Person(2, "baidu", "http://www.baidu.com");
- persons[2] = new Person(3, "google", "http://www.google.com");
- try {
- // // 方式一:使用Android提供的实用工具类android.util.Xml
- // XmlSerializer xmlSerializer = Xml.newSerializer();
- // 方式二:使用工厂类XmlPullParserFactory的方式
- XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
- XmlSerializer xmlSerializer = factory.newSerializer();
- xmlSerializer.setOutput(xmlWriter); // 保存创建的xml
- xmlSerializer.setFeature("http://xmlpull.org/v1/doc/features.html#indent-output", true);
- // xmlSerializer.setProperty("http://xmlpull.org/v1/doc/properties.html#serializer-indentation", " "); // 设置属性
- // xmlSerializer.setProperty("http://xmlpull.org/v1/doc/properties.html#serializer-line-separator", "\n");
- xmlSerializer.startDocument("utf-8", null); //
- xmlSerializer.startTag("", "root");
- xmlSerializer.attribute("", "author", "homer");
- xmlSerializer.attribute("", "date", "2012-04-28");
- int personsLen = persons.length;
- for(int i=0; i
- xmlSerializer.startTag("", "person"); // 创建person节点
- xmlSerializer.startTag("", "id");
- xmlSerializer.text(persons[i].getId()+"");
- xmlSerializer.endTag("", "id");
- xmlSerializer.startTag("", "name");
- xmlSerializer.text(persons[i].getName());
- xmlSerializer.endTag("", "name");
- xmlSerializer.startTag("", "blog");
- xmlSerializer.text(persons[i].getBlog());
- xmlSerializer.endTag("", "blog");
- xmlSerializer.endTag("", "person");
- }
- xmlSerializer.endTag("", "root");
- xmlSerializer.endDocument();
- } catch (XmlPullParserException e) { // XmlPullParserFactory.newInstance
- e.printStackTrace();
- } catch (IllegalArgumentException e) { // xmlSerializer.setOutput
- e.printStackTrace();
- } catch (IllegalStateException e) { // xmlSerializer.setOutput
- e.printStackTrace();
- } catch (IOException e) { // xmlSerializer.setOutput
- e.printStackTrace();
- } catch (Exception e) {
- e.printStackTrace();
- }
- savedXML(fileName, xmlWriter.toString());
- return xmlWriter.toString();
- }
运行结果:
3、Pull 解析 XML
pull方式,解析xml是通过 XmlPullParser 类实现
首先,通过XmlPullParser得到解析xml的实例 xpp
接着,通过 xpp设置输入 xpp.setInput(is, "utf-8"),声明定义保存xml信息的数据结构(如:Person数组)
然后,通过 xpp 解析 START_DOCUMENT、START_TAG、TEXT、END_TAG、END_DOCUMENT等
Code
- /** Pull方式,解析 XML */
- public String pullXMLResolve(){
- StringWriter xmlWriter = new StringWriter();
- InputStream is = readXML(fileName);
- try {
- // // 方式一:使用Android提供的实用工具类android.util.Xml
- // XmlPullParser xpp = Xml.newPullParser();
- // 方式二:使用工厂类XmlPullParserFactory的方式
- XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
- XmlPullParser xpp = factory.newPullParser();
- xpp.setInput(is, "utf-8");
- List
personsList = null; // 保存xml的person节点 - Person person = null;
- StringBuffer xmlHeader = null; // 保存xml头部
- String ele = null; // Element flag
- int eventType = xpp.getEventType();
- while(XmlPullParser.END_DOCUMENT != eventType) {
- switch (eventType) {
- case XmlPullParser.START_DOCUMENT:
- personsList = new ArrayList
(); // 初始化persons - xmlHeader = new StringBuffer(); // 初始化xmlHeader
- break;
- case XmlPullParser.START_TAG:
- if("root".equals(xpp.getName())) {
- String attrAuthor = xpp.getAttributeValue(0);
- String attrDate = xpp.getAttributeValue(1);
- xmlHeader.append("root").append("\t\t");
- xmlHeader.append(attrAuthor).append("\t");
- xmlHeader.append(attrDate).append("\n");
- } else if("person".equals(xpp.getName())) {
- person = new Person(); // 创建person实例
- } else if("id".equals(xpp.getName())) {
- ele = "id";
- } else if("name".equals(xpp.getName())) {
- ele = "name";
- } else if("blog".equals(xpp.getName())) {
- ele = "blog";
- } else {
- ele = null;
- }
- break;
- case XmlPullParser.TEXT:
- if(null != ele) {
- if("id".equals(ele)) {
- person.setId(Integer.parseInt(xpp.getText()));
- } else if("name".equals(ele)) {
- person.setName(xpp.getText());
- } else if("blog".equals(ele)) {
- person.setBlog(xpp.getText());
- }
- }
- break;
- case XmlPullParser.END_TAG:
- if("person".equals(xpp.getName())){
- personsList.add(person);
- person = null;
- }
- ele = null;
- break;
- }
- eventType = xpp.next(); // 下一个事件类型
- }
- xmlWriter.append(xmlHeader);
- int personsLen = personsList.size();
- for(int i=0; i
- xmlWriter.append(personsList.get(i).toString());
- }
- } catch (XmlPullParserException e) { // XmlPullParserFactory.newInstance
- e.printStackTrace();
- } catch (Exception e) {
- e.printStackTrace();
- }
- return xmlWriter.toString();
- }
运行结果:
4、Person类
请参见前面博客 Android 创建与解析XML(二)—— Dom方式 【4、Person类】
代码下载
参考推荐:
org.xmlpull.v1
pull创建xml
Android 创建与解析XML(五)—— Dom4j方式
1、Dom4j概述
dom4j is an easy to use, open source library for working with XML, XPath and XSLT on the Java platform using the Java Collections Framework and with full support for DOM, SAX and JAXP.
dom4j官方网址:dom4j
dom4j源码下载:dom4j download
本示例中,需要导入dom4j.jar包,才能引用dom4j相关类,dom4j源码和jar包,请见本示例【源码下载】或访问 dom4j
org.dom4j包,不仅包含创建xml的构建器类DocumentHelper、Element,而且还包含解析xml的解析器SAXReader、Element,包含类如下:
org.dom4j
org.dom4j.DocumentHelper;
org.dom4j.Element;
org.dom4j.io.SAXReader;
org.dom4j.io.XMLWriter;
org.dom4j.DocumentException;
sdk源码查看路径(google code)
创建和解析xml的效果图:

2、Dom4j 创建 XML
Dom4j,创建xml主要用到了org.dom4j.DocumentHelper、org.dom4j.Document、org.dom4j.io.OutputFormat、org.dom4j.io.XMLWriter
首先,DocumentHelper.createDocument(),创建 org.dom4j.Document 的实例 doc
接着,通过doc,设置xml属性doc.setXMLEncoding("utf-8")、doc.addElement("root")根节点,以及子节点等
然后,定义xml格式并输出,new XMLWriter(xmlWriter, outputFormat)
Code
- /** Dom4j方式,创建 XML */
- public String dom4jXMLCreate(){
- StringWriter xmlWriter = new StringWriter();
- Person []persons = new Person[3]; // 创建节点Person对象
- persons[0] = new Person(1, "sunboy_2050", "http://blog.csdn.net/sunboy_2050");
- persons[1] = new Person(2, "baidu", "http://www.baidu.com");
- persons[2] = new Person(3, "google", "http://www.google.com");
- try {
- org.dom4j.Document doc = DocumentHelper.createDocument();
- doc.setXMLEncoding("utf-8");
- org.dom4j.Element eleRoot = doc.addElement("root");
- eleRoot.addAttribute("author", "homer");
- eleRoot.addAttribute("date", "2012-04-25");
- eleRoot.addComment("dom4j test");
- int personsLen = persons.length;
- for(int i=0; i
- Element elePerson = eleRoot.addElement("person"); // 创建person节点,引用类为 org.dom4j.Element
- Element eleId = elePerson.addElement("id");
- eleId.addText(persons[i].getId()+"");
- Element eleName = elePerson.addElement("name");
- eleName.addText(persons[i].getName());
- Element eleBlog = elePerson.addElement("blog");
- eleBlog.addText(persons[i].getBlog());
- }
- org.dom4j.io.OutputFormat outputFormat = new org.dom4j.io.OutputFormat(); // 设置xml输出格式
- outputFormat.setEncoding("utf-8");
- outputFormat.setIndent(false);
- outputFormat.setNewlines(true);
- outputFormat.setTrimText(true);
- org.dom4j.io.XMLWriter output = new XMLWriter(xmlWriter, outputFormat); // 保存xml
- output.write(doc);
- output.close();
- } catch (Exception e) {
- e.printStackTrace();
- }
- savedXML(fileName, xmlWriter.toString());
- return xmlWriter.toString();
- }
运行结果:
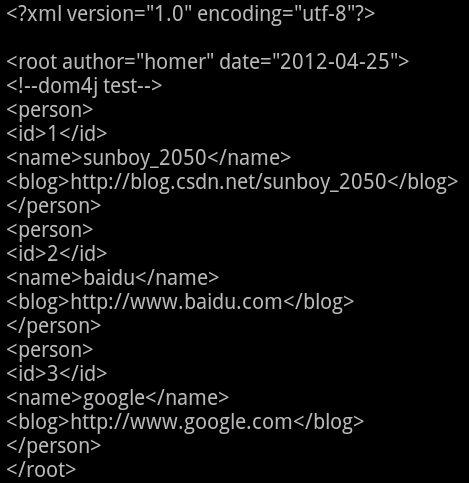
3、Dom4j 解析 XML
Dom4j,解析xml主要用到了org.dom4j.io.SAXReader、org.dom4j.Document、doc.getRootElement(),以及ele.getName()、ele.getText()等
首先,创建SAXReader的实例reader,读入xml字节流 reader.read(is)
接着,通过doc.getRootElement()得到root根节点,利用迭代器取得root下一级的子节点eleRoot.elementIterator()等
然后,得到解析的xml内容xmlWriter.append(xmlHeader)、xmlWriter.append(personsList.get(i).toString())
解析一:标准解析(Iterator 迭代)
Code
- /** Dom4j方式,解析 XML */
- public String dom4jXMLResolve(){
- StringWriter xmlWriter = new StringWriter();
- InputStream is = readXML(fileName);
- try {
- SAXReader reader = new SAXReader();
- org.dom4j.Document doc = reader.read(is);
- List
personsList = null; - Person person = null;
- StringBuffer xmlHeader = new StringBuffer();
- Element eleRoot = doc.getRootElement(); // 获得root根节点,引用类为 org.dom4j.Element
- String attrAuthor = eleRoot.attributeValue("author");
- String attrDate = eleRoot.attributeValue("date");
- xmlHeader.append("root").append("\t\t");
- xmlHeader.append(attrAuthor).append("\t");
- xmlHeader.append(attrDate).append("\n");
- personsList = new ArrayList
(); - // 获取root子节点,即person
- Iterator
iter = eleRoot.elementIterator(); - for(; iter.hasNext(); ) {
- Element elePerson = (Element)iter.next();
- if("person".equals(elePerson.getName())){
- person = new Person();
- // 获取person子节点,即id、name、blog
- Iterator
innerIter = elePerson.elementIterator(); - for(; innerIter.hasNext();) {
- Element ele = (Element)innerIter.next();
- if("id".equals(ele.getName())) {
- String id = ele.getText();
- person.setId(Integer.parseInt(id));
- } else if("name".equals(ele.getName())) {
- String name = ele.getText();
- person.setName(name);
- } else if("blog".equals(ele.getName())) {
- String blog = ele.getText();
- person.setBlog(blog);
- }
- }
- personsList.add(person);
- person = null;
- }
- }
- xmlWriter.append(xmlHeader);
- int personsLen = personsList.size();
- for(int i=0; i
- xmlWriter.append(personsList.get(i).toString());
- }
- } catch (DocumentException e) {
- e.printStackTrace();
- } catch (Exception e) {
- e.printStackTrace();
- }
- return xmlWriter.toString();
- }
运行结果:

解析二:选择性解析(XPath路径)
Dom4j+XPath,选择性只解析id,doc.selectNodes("//root//person//id")
Code
- /** Dom4j方式,解析 XML(方式二) */
- public String dom4jXMLResolve2(){
- StringWriter xmlWriter = new StringWriter();
- InputStream is = readXML(fileName);
- try {
- org.dom4j.io.SAXReader reader = new org.dom4j.io.SAXReader();
- org.dom4j.Document doc = reader.read(is);
- List
personsList = null; - Person person = null;
- StringBuffer xmlHeader = new StringBuffer();
- Element eleRoot = doc.getRootElement(); // 获得root根节点,引用类为 org.dom4j.Element
- String attrAuthor = eleRoot.attributeValue("author");
- String attrDate = eleRoot.attributeValue("date");
- xmlHeader.append("root").append("\t\t");
- xmlHeader.append(attrAuthor).append("\t");
- xmlHeader.append(attrDate).append("\n");
- personsList = new ArrayList
(); - @SuppressWarnings("unchecked")
- List
idList = (List ) doc.selectNodes("//root//person//id"); // 选择性获取全部id - Iterator
idIter = idList.iterator(); - while(idIter.hasNext()){
- person = new Person();
- Element idEle = (Element)idIter.next();
- String id = idEle.getText();
- person.setId(Integer.parseInt(id));
- personsList.add(person);
- }
- xmlWriter.append(xmlHeader);
- int personsLen = personsList.size();
- for(int i=0; i
- xmlWriter.append("id = ").append(personsList.get(i).getId()+"").append("\n");
- }
- } catch (DocumentException e) {
- e.printStackTrace();
- } catch (Exception e) {
- e.printStackTrace();
- }
- return xmlWriter.toString();
- }
注:借助 XPath 解析 XML 时,需要导入 jaxen;本示例需要导入的是最新的jaxen包jaxen-1.1.3.jar,可以下载本示例下面【源码下载】或 访问 jaxen jar
Jaxen is an open source XPath library written in Java. It is adaptable to many different object models, including DOM, XOM, dom4j, and JDOM. Is it also possible to write adapters that treat non-XML trees such as compiled Java byte code or Java beans as XML, thus enabling you to query these trees with XPath too.
jaxen 官方网址:jaxen
jaxen下载jar包:jaxen jar 或 jaxen jar
jaxen源码查看:jaxen src 或 jaxen trunk
运行结果:

4、Person类
请参见前面博客 Android 创建与解析XML(二)—— Dom方式 【4、Person类】
Android 创建与解析XML(六)—— 比较与使用
目录(?)[+]
前面介绍了四种创建、解析XML的方式:
0、 Android 创建与解析XML(一)—— 概述
1、 Android 创建与解析XML(二)—— Dom方式
2、 Android 创建与解析XML(三)—— Sax方式
3、 Android 创建与解析XML(四)—— Pull方式
4、 Android 创建与解析XML(五)—— Dom4j方式其中,从处理方式看,有的采用了Java处理XML的标准方式,有的是经过第三方改进后的XML处理方式;从事件角度看,有的是基于Dom树节点,有的基于事件处理
为什么创建、解析XML会产生这么多方法呢?四种处理方式的特点各是什么?它们分别更适合什么样的使用场景呢?
一、 XML 通用标准
XML 世界非常庞大,而且还在不断成长,存在大量不同的标准和技术,它们以复杂的方式互相影响。
XML 正在变得越来越强大,并且得到了迅速的发展,它已经证明自己是一种非常有价值的技术,但可能也是一种令人害怕的技术,如果考虑到挂在“XML”一词下面不断变化的各个部分,新手很难确定哪些是 XML 最重要的方面,用户也难以跟踪这个领域出现的新生事物和变化。
标准,有各种各样的形式,而且在同一个领域中常常有多种标准互相竞争,此处把标准定义为:被不同的供应商大量采用的或者有影响的、独立于供应商的组织推荐的规范。
1) XML 1.0 ,W3C 推荐的标准,衍生出 XML 技术大树的主干。它在 Unicode [Unicode Consortium 技术报告和 ISO 标准]的基础上定义了文本格式的严格规则,以及 DTD (文档类型定义,Document Type Definition)验证语言。该规范的当前版本(第 2 版)包含了规范的历次修订。它被 翻译成多种语言,尽管英语版本是唯一的规范版本,就是说只有这个版本被认为具有标准的效力。
2) XML 1.1 ,正在开发中,是改变了结构良好的 XML 文档的定义的第一个修订版。主要的变化是修订了 XML 规范中对字符的处理,使其更自然地适应 Unicode 规范的变化,并通过引用 万维网字符模型(Character Model for the World Wide Web 1.0)[开发中],提供了不同 Unicode 版本字符的规范化。XML 1.1 还增加了行结束字符列表,新增加的 NEL 用于在 IBM 大型机系统中表示行结束(EOL)。这种变化存在争议,有人认为对大型机用户带来的有限好处不值得做这种基础性的改变。还有一些其他的争论,因为一些评论者发现所有的修改都太稳妥了,在 XML 版本变换中不会造成各种可能的互操作性问题。
XML 是基于 Standard Generalized Markup Language(标准通用标记语言,SGML)的,后者由 ISO 8879:1986 [ISO 标准]定义。它在很大程度上简化了 SGML,包括一些调整使其更适合于 Web 环境。
二、 XML处理方式
大多数与XML 相关的Java API 在Android 上得到了完全支持,在Android 上可以创建功能强大的移动应用程序,而在Android 上解析XML的技术有三种DOM、SAX、PULL。
1) DOM 解析技术
DOM(Document Object Model,文档对象模型),Android 完全支持DOM 解析,利用DOM 中的对象,可以对XML 文档进行读取、搜索、修改、添加和删除等操作。
使用DOM 对XML 文件进行操作时,首先要解析文件,将文件分为独立的元素、属性和注释等,然后以节点树的形式在内存中对XML 文件进行表示,就可以通过节点树访问文档的内容,并根据需要修改文档——这就是DOM的工作原理。DOM 实现时首先为XML 文档的解析定义一组接口,解析器读入整个文档,然后构造一个驻留内存的树结构,这样代码就可以使用DOM接口来操作整个树结构。
DOM 解析流程:
2) SAX 解析技术
SAX(Simple API for XML,XML 简单应用程序接口),是一个公共的基于事件的XML 文档解析标准。它以事件作为解析XML 文件的模式,它将XML 文件转化成一系列的事件,由不同的事件处理器来决定如何处理。SAX是一个解析速度快并且占用内存少的xml解析器,非常适合android等移动设备,SAX解析XML文件采用的是事件驱动,也就是说,它并不需要解析完整个文档,在按内容顺序解析文档的过程中,SAX会判断当前读取到的字符是否合法xml语法中的某部分,如果符合就会触发事件。
SAX解析流程:
3) PULL解析技术
Android API 中,另外提供了Android.util.Xml 类,同样可以解析XML 文件,使用方法类似SAX,也都需编写Handler来处理XML 的解析,但是在使用上却比SAX 来得简单。它允许用户的应用程序代码从解析器中获取事件,这与SAX 解析器自动将事件推入处理程序相反。Pull解析器运行方式与SAX解析器类似,它提供了类似ide事件,如:开始元素和结束元素,使用parser.next()可以进入下一个元素并触发相应的事件。事件作为数值代码被发送,因此可以使用一个switch对感兴趣的事件进行处理。当元素开始解析时,调用parser.nextText()方法获取一个Text类型的节点的值。
PULL解析流程:
三、 XML性能比较
- 处理时间
- 占用内存
四、 使用场景
DOM解析器,是通过将XML文档解析成树状模型并将其放入内存来完成解析工作的,而后对文档的操作都是在这个树状模型上完成的。这个在内存中的文档树将是文档实际大小的几倍。这样做的好处是结构清除、操作方便,而带来的麻烦就是极其耗费系统资源。
SAX解析器,正好克服了DOM的缺点,分析能够立即开始,而不是等待所有的数据被处理。而且,由于应用程序只是在读取数据时检查数据,因此不需要将数据存储在内存中,这对于大型文档来说是个巨大的优点。事实上,应用程序甚至不必解析整个文档;它可以在某个条件得到满足时停止解析。
选择何种XML解析技术,取决于下面几个因素:
(1) 应用目的:如果打算对数据作出更改并将它输出为 XML,那么在大多数情况下,DOM 是适当的选择。并不是说使用 SAX和PULL 就不能更改数据,但是该过程要复杂得多,因为您必须对数据的一份拷贝而不是对数据本身作出更改。
(2) 数据容量: 对于大型文件,SAX和PULL 是更好的选择。
(3) 数据使用:如果只有数据中的少量部分会被使用,那么使用 SAX,PULL来将该部分数据提取到应用程序中可能更好。另一方面,如果您知道自己以后会回头引用已处理过的大量信息,那么 SAX,PULL也许不是恰当的选择。
(4) 速度需要: SAX,PULL实现通常要比 DOM 实现更快。
(5) 添加节点:为了能动态给xml添加节点,推荐使用DOM。
(6) 在SAX和PULL都可以使用的情况下,建议使用PULL来解析。
五、 总结
对于Android 的移动设备而言,因为设备的资源比较宝贵,内存是有限的,所以我们需要选择适合的技术来解析XML,这样有利于提高访问的速度。
(1) DOM 在处理XML 文件时,将XML 文件解析成树状结构并放入内存中进行处理。当XML 文件较小时,我们可以选DOM,因为它简单、直观。
(2) SAX 则是以事件作为解析XML 文件的模式,它将XML 文件转化成一系列的事件,由不同的事件处理器来决定如何处理。XML 文件较大时,选择SAX 技术是比较合理的。虽然代码量有些大,但是它不需要将所有的XML 文件加载到内存中。这样对于有限的Android 内存更有效,而且Android 提供了一种传统的SAX 使用方法以及一个便捷的SAX 包装器。使用Android.util.Xml 类。
(3) PULL解析并未像SAX 解析那样监听元素的结束,而是在开始处完成了大部分处理。这有利于提早读取XML 文件,可以极大的减少解析时间,这种优化对于连接速度较慢的移动设备而言尤为重要。对于XML 文档较大但只需要文档的一部分时,PULL解析器则是更为有效的方法。
Android 是最常用的智能手机平台,XML 是数据交换的标准媒介,Android 中可以使用标准的XML生成器、解析器、转换器 API,对 XML 进行解析和转换。
XML,相关有DOM、SAX、JDOM、DOM4J、Xerces、JAXP等一堆概念,但是很多人总是会弄混他们之间的关系,这对我们理解XML文件的创建和解析很不利。要挑选一个适合在Android平台上使用的XML解析方案,我们还是得先把这些概念厘清。
DOM(Document Object Model,文档对象模型)和SAX(Simple API for XML,简单XML应用接口),是JAXP(Java API for XML Processing,Java XML处理的应用接口)定义的2种不同的对XML文档进行分析、处理的方法。
DOM方法是用标准对象模型表示 XML 文档;SAX方法则使用事件模型来处理程序来处理XML。
JAXP完成了对SAX、DOM的包装,它向应用程序提供针对DOM的DocumentBuilderFactory、 DocumentBuilder;以及针对SAX的SAXParserFactory、SAXParser抽象工厂类。在Jave SE中JAXP对应javax.xml.parsers包,DOM对应org.w3c.dom,SAX对应org.xml.sax。
Xerces 首先继承并实现了javax.xml.parser包内的SAXParser、SAXParserFactory、DocumentBuilder、DocumentBuilderFactory等抽象类,并提供了JAXP中所定义的DOM、SAX(以及StAX,后面会介绍)这些XML解析方法的实现和相应的Parser。
JDOM和DOM4J,是因为有人觉得W3C的DOM标准API太过难用而着手开发的替代API,它们和JAXP一样都是对DOM、SAX的封装,不过JDOM、DOM4J做了更多的事情,相当于上面提到JAXP接口+Xerces DOM实现部分。JDOM并没有自己开发Parser,所以还是需要利用Xerces的Parser部分,而DOM4J自带一个名为Alfred2的Parser,当然也可以使用Xerces的Parser。看起来JAXP具备更好的可移植性,即我们可以通过修改配置文件切换不同的DOM实现和SAX、DOM Parser,JDOM、DOM4J虽然也可以切换Parser,但是DOM实现是无法切换的。(参考: Java XML API 漫谈 和 JAXP全面介绍)
XML创建与解析
XML创建主要四种方式:Dom、Sax、Pull、Dom4j
XML解析主要四种方式:Dom、Sax、Pull、Dom4j
其中,利用Dom、Sax、Pull、Dom4j创建的标准XML格式文件,可以由任何一种Dom、Sax、Pull、Dom4j解析方式进行解析。
Android中解析XML
DOM解析器, 是通过将XML文档解析成树状模型并将其放入内存来完成解析工作的,然后对文档的操作都是在这个树状模型上完成的。这个在内存中的文档树将是文档实际大小的几倍。这样做的好处是结构清晰、操作方便,而带来的麻烦就是极其耗费系统资源。SAX解析器 ,正好克服了DOM的缺点,分析能够立即开始,而不是等待所有的数据被处理。而且,由于应用程序只是在读取数据时检查数据,因此不需要将数据存储在内存中,这对于大型文档来说是个巨大的优点。事实上,应用程序甚至不必解析整个文档,它可以在某个条件得到满足时停止解析。
DOM与SAX比较
下面的表格列出了SAX和DOM在一些方面的对照:
| SAX | DOM |
| 顺序读入文档并产生相应事件,可以处理任何大小的XML文档 | 在内存中创建文档树,不适于处理大型XML文档。 |
| 只能对文档按顺序解析一遍,不支持对文档的随意访问。 | 可以随意访问文档树的任何部分,没有次数限制。 |
| 只能读取XML文档内容,而不能修改 | 可以随意修改文档树,从而修改XML文档。 |
| 开发上比较复杂,需要自己来实现事件处理器。 | 易于理解,易于开发。 |
| 对开发人员而言更灵活,可以用SAX创建自己的XML对象模型。 | 已经在DOM基础之上创建好了文档树。 |
通过对SAX和DOM的分析,它们各有自己的不同应用领域:
SAX适于处理下面的问题:- 对大型文档进行处理。
- 只需要文档的部分内容,或者只需要从文档中得到特定信息。
- 想创建自己的对象模型的时候。
DOM适于处理下面的问题:
- 需要对文档进行修改
- 需要随机对文档进行访问,例如XSLT解析器。
1、数据修改:如果打算 对数据作出更改并将它输出为 XML ,那么在大多数情况下,DOM 是适当的选择。并不是说使用 SAX 就不能更改数据,但是该过程要复杂得多,因为您必须对数据的一份拷贝而不是对数据本身作出更改。
2、数据容量: 对于 大型文件 ,SAX 是更好的选择。
3、数据使用:如果只有 数据中的少量部分会被使用 ,那么使用 SAX 来将该部分数据提取到应用程序中可能更好。 另一方面,如果您知道自己以后会回头引用已处理过的大量信息,那么 SAX 也许不是恰当的选择。
4、速度要求: SAX 实现通常要比 DOM 实现 速度更快 。
基于上面的分析,在基于Android系统的内存和CPU资源比较有限的手持设备上,只要我们不需要修改XML数据或者随机的访问XML数据,SAX尽管可能需要更多的编码工作,但是为了更小的内存和CPU消耗,还是值得的。
另外,Android SDK中已经包含了JAXP对应的javax.xml.parsers包,SAX对应org.xml.sax,DOM对应的org.w3c.dom包,加上Android还提供了android.sax这样的包来方便SAX Handle的开发,基于JAXP和SAX这样的标准方法来开发不仅复杂度不高,即使出现问题在讨论组中寻求解决方案也是比较容易的。(参考: 使用 SAX 处理 XML 文档 和 DOM SAX JAXP DOM4J JDOM xerces解析器 )
Android中解析XML实现
基于上面的分析,采用JAXP+SAX的方案是我比较看好的。我们首先需要又一个SAXParserFactory的实例,然后从工厂中得到一个SAXParser实例,进而获取一个XMLReader;接下来新建一个Handler类继承自SAX Helpler的DefaultHandler,并实现startDocument()、startElement()、endElement()以及endDocument()等方法,并把这个Handler作为XMLReader的Content Handler;最后以带解析的XML文档为参数调用XMLReader的parse方法即可。具体的代码参考:Android 上使用 XML 和 Android 3.0 平台上创建和解析 XML
Android SDK中包含了 JAXP 对应javax.xml.parsers包, SAX 对应的org.xml.sax, DOM 对应的org.w3c.dom包,所以我们就已经有了XML解析所需的JAXP——对SAX和DOM的封装(抽象类)以及SAX和DOM接口类,但是对于JAXP抽象类的实现,以及DOM和SAX接口类的实现在哪里呢?是和Java SE 5.0一样用了Xerces吗? 不!
通过查看Android 1.5的源代码,我看到这部分的代码来自Apache Harmony这个开源的Java SE实现,位于./dalvik/libcore/xml/src/main/java/org/apache/harmony/xml目录。这里包含有一个完整的DOM实现(dom目录),对于javax.xml.parser下的抽象类的实现(parser目录),以及对于SAX接口类的实现(除此以外还包括对XMLPullParser接口的实现)。
2、XmlPull 和 KXML2
XmlPull解析器, 提供了资源有限的环境(如J2ME)应用使用的XML解析API,XPP提供了非常简单的接口——包含一个接口、一个异常、一个建立解析器的factory。它采用了类似JAXP的工厂模式,把接口设计和实现分离,KXML2就是一个为J2ME环境优化的一个实现。在Android SDK中,已经包含了XmlPull(org.xmlpull.v1包)以及它的一个AddOn——SAX2 Driver——它使得我们可以通过SAX2的API来操纵XmlPull Parser。另外,通过sourcecode,我们可以看到Android SDK中的XmlPull的实现是KXML2,位于./dalvik/libcore/xml/src/main/java/org/kxml2目录。Apache Harmony的目录中同样有一个ExpatPullParser类实现了XMLPullParser接口,但是却没有XmlSerializer接口的实现,所以只能说Android中的Harmony也部分实现了XmlPull API。XmlPull+KXML2是下一步我要实践的方案,到时候还得学习一下如何“公平”的比较两者的性能。
3、StAX
尽管Android中还没有提供相应的支持,但是Streaming API for XML (StAX) 作为用Java语言处理 XML的最新标准,无论从性能还是可用性上都有出色的表现。它不仅提供了一个快捷、易用、占用内存少的 XML 解析器,它还提供了过滤器接口,允许程序员向应用程序业务逻辑隐藏不需要的文档细节。感兴趣的朋友可以看一看下面的文章。
使用 StAX 解析 XML,第 1 部分: Streaming API for XML (StAX) 简介
使用 StAX 解析 XML,第 2 部分: 拉式解析和事件
使用 StAX 解析 XML,第 3 部分: 使用定制事件和编写 XML
参考推荐:
Android中解析XML数据
android解析XML总结(SAX、Pull、Dom三种方式)
Android 解析XML文件的三种方式 DOM,SAX,PULL
android解析xml文件的方式(推荐,共三篇)
Android 上使用 XML
Android 上使用 XML 和 JSON
Android 3.0 平台上创建和解析 XML
Android XML解析学习——创建XML(共六篇,推荐)
Android 创建与解析XML(二)—— Dom方式
1. Dom概述
Dom方式创建XML,应用了标准xml构造器 javax.xml.parsers.DocumentBuilder 来创建 XML 文档,需要导入以下内容
javax.xml.parsers
javax.xml.transformjavax.xml.parsers.DocumentBuilder
javax.xml.parsers.DocumentBuilderFactory
javax.xml.parsers.ParserConfigurationException;
javax.xml.transform.TransformerFactory
javax.xml.transform.Transformer
javax.xml.transform.dom.DOMSource
javax.xml.transform.stream.StreamResult
javax.xml.transform.OutputKeys;
javax.xml.transform.TransformerFactoryConfigurationError;
javax.xml.transform.TransformerConfigurationException;
javax.xml.transform.TransformerException;
org.w3c.dom
org.w3c.dom.Document;
org.w3c.dom.Element;
org.w3c.dom.Node;
org.w3c.dom.DOMException;
org.w3c.dom.NodeList;
org.xml.sax.SAXException;
sdk源码查看路径(google code)
创建和解析xml的效果图:
2、Dom 创建 XML
Dom,借助 javax.xml.parsers.DocumentBuilder,可以创建 org.w3c.dom.Document 对象。
使用来自 DocumentBuilderFactory 的 DocumentBuilder 对象在 Android 设备上创建与解析 XML 文档。您将使用 XML pull 解析器的扩展来解析 XML 文档。
Code
- /** Dom方式,创建 XML */
- public String domCreateXML() {
- String xmlWriter = null;
- Person []persons = new Person[3]; // 创建节点Person对象
- persons[0] = new Person(1, "sunboy_2050", "http://blog.csdn.net/sunboy_2050");
- persons[1] = new Person(2, "baidu", "http://www.baidu.com");
- persons[2] = new Person(3, "google", "http://www.google.com");
- try {
- DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
- DocumentBuilder builder = factory.newDocumentBuilder();
- Document doc = builder.newDocument();
- Element eleRoot = doc.createElement("root");
- eleRoot.setAttribute("author", "homer");
- eleRoot.setAttribute("date", "2012-04-26");
- doc.appendChild(eleRoot);
- int personsLen = persons.length;
- for(int i=0; i
- Element elePerson = doc.createElement("person");
- eleRoot.appendChild(elePerson);
- Element eleId = doc.createElement("id");
- Node nodeId = doc.createTextNode(persons[i].getId() + "");
- eleId.appendChild(nodeId);
- elePerson.appendChild(eleId);
- Element eleName = doc.createElement("name");
- Node nodeName = doc.createTextNode(persons[i].getName());
- eleName.appendChild(nodeName);
- elePerson.appendChild(eleName);
- Element eleBlog = doc.createElement("blog");
- Node nodeBlog = doc.createTextNode(persons[i].getBlog());
- eleBlog.appendChild(nodeBlog);
- elePerson.appendChild(eleBlog);
- }
- Properties properties = new Properties();
- properties.setProperty(OutputKeys.INDENT, "yes");
- properties.setProperty(OutputKeys.MEDIA_TYPE, "xml");
- properties.setProperty(OutputKeys.VERSION, "1.0");
- properties.setProperty(OutputKeys.ENCODING, "utf-8");
- properties.setProperty(OutputKeys.METHOD, "xml");
- properties.setProperty(OutputKeys.OMIT_XML_DECLARATION, "yes");
- TransformerFactory transformerFactory = TransformerFactory.newInstance();
- Transformer transformer = transformerFactory.newTransformer();
- transformer.setOutputProperties(properties);
- DOMSource domSource = new DOMSource(doc.getDocumentElement());
- OutputStream output = new ByteArrayOutputStream();
- StreamResult result = new StreamResult(output);
- transformer.transform(domSource, result);
- xmlWriter = output.toString();
- } catch (ParserConfigurationException e) { // factory.newDocumentBuilder
- e.printStackTrace();
- } catch (DOMException e) { // doc.createElement
- e.printStackTrace();
- } catch (TransformerFactoryConfigurationError e) { // TransformerFactory.newInstance
- e.printStackTrace();
- } catch (TransformerConfigurationException e) { // transformerFactory.newTransformer
- e.printStackTrace();
- } catch (TransformerException e) { // transformer.transform
- e.printStackTrace();
- } catch (Exception e) {
- e.printStackTrace();
- }
- savedXML(fileName, xmlWriter.toString());
- return xmlWriter.toString();
- }
运行结果:
3、Dom 解析 XML
Dom方式,解析XML是创建XML的逆过程,主要用到了builder.parse(is)进行解析,然后通过Tag、NodeList、Element、childNotes等得到Element和Node属性或值。
Code
- /** Dom方式,解析 XML */
- public String domResolveXML() {
- StringWriter xmlWriter = new StringWriter();
- InputStream is= readXML(fileName);
- try {
- DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
- DocumentBuilder builder = factory.newDocumentBuilder();
- Document doc = builder.parse(is);
- doc.getDocumentElement().normalize();
- NodeList nlRoot = doc.getElementsByTagName("root");
- Element eleRoot = (Element)nlRoot.item(0);
- String attrAuthor = eleRoot.getAttribute("author");
- String attrDate = eleRoot.getAttribute("date");
- xmlWriter.append("root").append("\t\t");
- xmlWriter.append(attrAuthor).append("\t");
- xmlWriter.append(attrDate).append("\n");
- NodeList nlPerson = eleRoot.getElementsByTagName("person");
- int personsLen = nlPerson.getLength();
- Person []persons = new Person[personsLen];
- for(int i=0; i
- Element elePerson = (Element) nlPerson.item(i); // person节点
- Person person = new Person(); // 创建Person对象
- NodeList nlId = elePerson.getElementsByTagName("id");
- Element eleId = (Element)nlId.item(0);
- String id = eleId.getChildNodes().item(0).getNodeValue();
- person.setId(Integer.parseInt(id));
- NodeList nlName = elePerson.getElementsByTagName("name");
- Element eleName = (Element)nlName.item(0);
- String name = eleName.getChildNodes().item(0).getNodeValue();
- person.setName(name);
- NodeList nlBlog = elePerson.getElementsByTagName("blog");
- Element eleBlog = (Element)nlBlog.item(0);
- String blog = eleBlog.getChildNodes().item(0).getNodeValue();
- person.setBlog(blog);
- xmlWriter.append(person.toString()).append("\n");
- persons[i] = person;
- }
- } catch (ParserConfigurationException e) { // factory.newDocumentBuilder
- e.printStackTrace();
- } catch (SAXException e) { // builder.parse
- e.printStackTrace();
- } catch (IOException e) { // builder.parse
- e.printStackTrace();
- } catch (Exception e) {
- e.printStackTrace();
- }
- return xmlWriter.toString();
- }
运行结果:
4、Person类
Person类,是创建xml的单位实例,基于Java面向对象定义的一个类
- public class Person {
- private int id;
- private String name;
- private String blog;
- public Person() {
- this.id = -1;
- this.name = "";
- this.blog = "";
- }
- public Person(int id, String name, String blog) {
- this.id = id;
- this.name = name;
- this.blog = blog;
- }
- public Person(Person person) {
- this.id = person.id;
- this.name = person.name;
- this.blog = person.blog;
- }
- public Person getPerson(){
- return this;
- }
- public void setId(int id) {
- this.id = id;
- }
- public int getId(){
- return this.id;
- }
- public void setName(String name) {
- this.name = name;
- }
- public String getName() {
- return this.name;
- }
- public void setBlog(String blog) {
- this.blog = blog;
- }
- public String getBlog() {
- return this.blog;
- }
- public String toString() {
- return "Person \nid = " + id + "\nname = " + name + "\nblog = " + blog + "\n";
- }
- }
代码下载
参考推荐:
org.w3c.dom
javax.xml.parsers
javax.xml.transform
dom创建xml
java dom创建xml
Android 创建与解析XML(三)—— Sax方式
1. Sax概述
startDocument():当遇到文档的时候就触发这个事件 调用这个方法 可以在其中做些预处理工作,如:申请对象资源
startElement(String namespaceURI, String localName, String qName, Attributes atts):当遇开始标签的时候就会触发这个方法。
endElement(String uri, String localName, String name):当遇到结束标签时触发这个事件,调用此法可以做些善后工作。
charachers(char [] ch, int start, int length):当遇到xml内容时触发这个方法,用new String(ch,start,length)可以接受内容。
javax.xml.transform
javax.xml.transform.sax.SAXTransformerFactory;
javax.xml.transform.sax.TransformerHandler;
javax.xml.transform.Transformer;javax.xml.transform.TransformerConfigurationException;javax.xml.transform.TransformerFactoryConfigurationError;javax.xml.transform.OutputKeys;
javax.xml.transform.stream.StreamResult;
javax.xml.transform.sax.SAXTransformerFactory;
javax.xml.parsers
javax.xml.parsers.SAXParser;
javax.xml.parsers.SAXParserFactory;
javax.xml.parsers.FactoryConfigurationError;
javax.xml.parsers.ParserConfigurationException;
org.xml.sax
org.xml.sax.Attributes;org.xml.sax.SAXException;
org.xml.sax.helpers.AttributesImpl;
org.xml.sax.helpers.DefaultHandler;
sdk源码查看路径(google code)
Sax 创建和解析 XML 的效果图:
2、Sax 创建 XML
首先,SAXTransformerFactory.newInstance() 创建一个工厂实例 factory
接着,factory.newTransformerHandler() 获取 TransformerHandler 的 handler 对象
然后,通过 handler 事件创建handler.getTransformer()、 handler.setResult(result),以及 startDocument()、startElement、characters、endElement、endDocument()等
Code
- /** Sax方式,创建 XML */
- public String saxCreateXML(){
- StringWriter xmlWriter = new StringWriter();
- Person []persons = new Person[3]; // 创建节点Person对象
- persons[0] = new Person(1, "sunboy_2050", "http://blog.csdn.net/sunboy_2050");
- persons[1] = new Person(2, "baidu", "http://www.baidu.com");
- persons[2] = new Person(3, "google", "http://www.google.com");
- try {
- SAXTransformerFactory factory = (SAXTransformerFactory)SAXTransformerFactory.newInstance();
- TransformerHandler handler = factory.newTransformerHandler();
- Transformer transformer = handler.getTransformer(); // 设置xml属性
- transformer.setOutputProperty(OutputKeys.INDENT, "yes");
- transformer.setOutputProperty(OutputKeys.ENCODING, "utf-8");
- transformer.setOutputProperty(OutputKeys.VERSION, "1.0");
- StreamResult result = new StreamResult(xmlWriter); // 保存创建的xml
- handler.setResult(result);
- handler.startDocument();
- AttributesImpl attr = new AttributesImpl();
- attr.clear();
- attr.addAttribute("", "", "author", "", "homer");
- attr.addAttribute("", "", "date", "", "2012-04-27");
- handler.startElement("", "", "root", attr);
- int personsLen = persons.length;
- for(int i=0; i
- attr.clear();
- handler.startElement("", "", "person", attr);
- attr.clear();
- handler.startElement("", "", "id", attr);
- String id = persons[i].getId() + "";
- handler.characters(id.toCharArray(), 0, id.length());
- handler.endElement("", "", "id");
- attr.clear();
- handler.startElement("", "", "name", attr);
- String name = persons[i].getName();
- handler.characters(name.toCharArray(), 0, name.length());
- handler.endElement("", "", "name");
- attr.clear();
- handler.startElement("", "", "blog", attr);
- String blog = persons[i].getBlog();
- handler.characters(blog.toCharArray(), 0, blog.length());
- handler.endElement("", "", "blog");
- handler.endElement("", "", "person");
- }
- handler.endElement("", "", "root");
- handler.endDocument();
- } catch (TransformerFactoryConfigurationError e) { // SAXTransformerFactory.newInstance
- e.printStackTrace();
- } catch (TransformerConfigurationException e) { // factory.newTransformerHandler
- e.printStackTrace();
- } catch (IllegalArgumentException e) { // transformer.setOutputProperty
- e.printStackTrace();
- } catch (SAXException e) { // handler.startDocument
- e.printStackTrace();
- } catch (Exception e) {
- e.printStackTrace();
- }
- savedXML(fileName, xmlWriter.toString());
- return xmlWriter.toString();
- }
运行结果:
3、Sax解析XML
Code
- /** Sax方式,解析 XML */
- public String saxResolveXML(){
- StringWriter xmlWriter = new StringWriter();
- InputStream is = readXML(fileName);
- try {
- SAXParserFactory factory = SAXParserFactory.newInstance();
- SAXParser saxParser = factory.newSAXParser();
- PersonHandler handler = new PersonHandler(); // person处理Handler
- saxParser.parse(is, handler); // handler解析xml
- // 获取解析的xml
- String xmlHeader = handler.getXMLHeader();
- xmlWriter.append(xmlHeader);
- List
personsList = handler.getPersons(); - int personsLen = personsList.size();
- for(int i=0; i
- xmlWriter.append(personsList.get(i).toString()).append("\n");
- }
- } catch (FactoryConfigurationError e) { // SAXParserFactory.newInstance
- e.printStackTrace();
- } catch (ParserConfigurationException e) { // factory.newSAXParser
- e.printStackTrace();
- } catch (SAXException e) { // factory.newSAXParser
- e.printStackTrace();
- } catch (IllegalArgumentException e) { // saxParser.parse
- e.printStackTrace();
- } catch (IOException e) { // saxParser.parse
- e.printStackTrace();
- } catch (Exception e) {
- e.printStackTrace();
- }
- return xmlWriter.toString();
- }
- /** Handler处理类 */
- private final class PersonHandler extends DefaultHandler{
- private List
personsList = null; // 保存person - private Person person = null;
- private StringBuffer xmlHeader; // 保存xml头部信息
- private String tag = null; // xml Element
- /** 返回解析的xml头部信息 */
- public String getXMLHeader(){
- return xmlHeader.toString();
- }
- /** 返回解析的Person实例数组 */
- public List
getPersons(){ - return personsList;
- }
- @Override
- public void startDocument() throws SAXException{
- super.startDocument();
- personsList = new ArrayList
(); - xmlHeader = new StringBuffer();
- }
- @Override
- public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException{
- super.startElement(uri, localName, qName, attributes);
- if("root".equals(localName)) {
- String attrAuthor = attributes.getValue(0);
- String attrDate = attributes.getValue(1);
- xmlHeader.append("root").append("\t\t");
- xmlHeader.append(attrAuthor).append("\t");
- xmlHeader.append(attrDate).append("\n");
- } else if("person".equals(localName)) {
- person = new Person();
- }
- tag = localName;
- }
- @Override
- public void characters(char[] ch, int start, int length) throws SAXException {
- super.characters(ch, start, length);
- if (null != tag) {
- String value = new String(ch, start, length);
- System.out.println("value = " + value);
- if ("id".equals(tag)) {
- person.setId(new Integer(value));
- } else if ("name".equals(tag)) {
- person.setName(value);
- } else if ("blog".equals(tag)) {
- person.setBlog(value);
- }
- }
- }
- @Override
- public void endElement(String uri, String localName, String qName) throws SAXException {
- if("person".equals(qName)) {
- personsList.add(person);
- person = null;
- }
- tag = null;
- super.endElement(uri, localName, qName);
- }
- @Override
- public void endDocument() throws SAXException{
- // personsList = null;
- super.endDocument();
- }
- }
运行结果:
4、Person类
请参见前面博客 Android 创建与解析XML(二)—— Dom方式 【4、Person类】
Android 创建与解析XML(四)—— Pull方式
1、Pull概述
Android系统中和创建XML相关的包为org.xmlpull.v1,在这个包中不仅提供了用于创建XML的 XmlSerializer,还提供了用来解析XML的Pull方式解析器 XmlPullParser
XmlSerializer没有像XmlPullParser那样提取XML事件,而是把它们推出到数据流OutputStream或Writer中。
XmlSerializer提供了很直观的API,即使用startDocument开始文档,endDocument结束文档,startTag开始元素,endTag结束元素,text添加文本等。
Pull方式创建XML,应用了标准xml构造器 org.xmlpull.v1.XmlSerializer来创建 XML ,org.xmlpull.v1.XmlPullParser来解析XML,需要导入以下内容
org.xmlpull.v1
org.xmlpull.v1.XmlPullParser;
org.xmlpull.v1.XmlPullParserException;
org.xmlpull.v1.XmlPullParserFactory;
org.xmlpull.v1.XmlSerializer;
sdk源码查看路径(google code)
Pull 创建和解析 XML 的效果图:
2、Pull 创建 XML
pull方式,创建xml是通过 XmlSerializer 类实现
首先,通过XmlSerializer得到创建xml的实例 xmlSerializer
接着,通过 xmlSerializer 设置输出 xmlSerializer.setOutput,xmlSerializer.startDocument("utf-8", null)设置xml属性等
然后,通过 xmlSerializer 创建 startDocument、startTag、text、endTag、endDocument等
Code
- /** Pull方式,创建 XML */
- public String pullXMLCreate(){
- StringWriter xmlWriter = new StringWriter();
- Person []persons = new Person[3]; // 创建节点Person对象
- persons[0] = new Person(1, "sunboy_2050", "http://blog.csdn.net/sunboy_2050");
- persons[1] = new Person(2, "baidu", "http://www.baidu.com");
- persons[2] = new Person(3, "google", "http://www.google.com");
- try {
- // // 方式一:使用Android提供的实用工具类android.util.Xml
- // XmlSerializer xmlSerializer = Xml.newSerializer();
- // 方式二:使用工厂类XmlPullParserFactory的方式
- XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
- XmlSerializer xmlSerializer = factory.newSerializer();
- xmlSerializer.setOutput(xmlWriter); // 保存创建的xml
- xmlSerializer.setFeature("http://xmlpull.org/v1/doc/features.html#indent-output", true);
- // xmlSerializer.setProperty("http://xmlpull.org/v1/doc/properties.html#serializer-indentation", " "); // 设置属性
- // xmlSerializer.setProperty("http://xmlpull.org/v1/doc/properties.html#serializer-line-separator", "\n");
- xmlSerializer.startDocument("utf-8", null); //
- xmlSerializer.startTag("", "root");
- xmlSerializer.attribute("", "author", "homer");
- xmlSerializer.attribute("", "date", "2012-04-28");
- int personsLen = persons.length;
- for(int i=0; i
- xmlSerializer.startTag("", "person"); // 创建person节点
- xmlSerializer.startTag("", "id");
- xmlSerializer.text(persons[i].getId()+"");
- xmlSerializer.endTag("", "id");
- xmlSerializer.startTag("", "name");
- xmlSerializer.text(persons[i].getName());
- xmlSerializer.endTag("", "name");
- xmlSerializer.startTag("", "blog");
- xmlSerializer.text(persons[i].getBlog());
- xmlSerializer.endTag("", "blog");
- xmlSerializer.endTag("", "person");
- }
- xmlSerializer.endTag("", "root");
- xmlSerializer.endDocument();
- } catch (XmlPullParserException e) { // XmlPullParserFactory.newInstance
- e.printStackTrace();
- } catch (IllegalArgumentException e) { // xmlSerializer.setOutput
- e.printStackTrace();
- } catch (IllegalStateException e) { // xmlSerializer.setOutput
- e.printStackTrace();
- } catch (IOException e) { // xmlSerializer.setOutput
- e.printStackTrace();
- } catch (Exception e) {
- e.printStackTrace();
- }
- savedXML(fileName, xmlWriter.toString());
- return xmlWriter.toString();
- }
运行结果:
3、Pull 解析 XML
pull方式,解析xml是通过 XmlPullParser 类实现
首先,通过XmlPullParser得到解析xml的实例 xpp
接着,通过 xpp设置输入 xpp.setInput(is, "utf-8"),声明定义保存xml信息的数据结构(如:Person数组)
然后,通过 xpp 解析 START_DOCUMENT、START_TAG、TEXT、END_TAG、END_DOCUMENT等
Code
- /** Pull方式,解析 XML */
- public String pullXMLResolve(){
- StringWriter xmlWriter = new StringWriter();
- InputStream is = readXML(fileName);
- try {