CDH+HBase Indexer+Solr为HBase数据创建二级索引
CDH+HBase Indexer+Solr为HBase数据创建二级索引
文章目录
- 0.前期声明
- 1.HBase建表并添加数据,并且确定HBase表开启REPLICATION功能(1表示开启replication功能,0表示不开启,默认为0 )
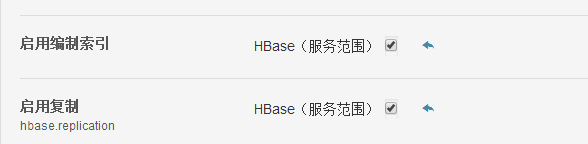
- 2.HBase启用复制(在CM的hbase上搜索复制,勾选启用复制)
- 3.准备中文分词包(如果需要中文分词的话)
- 4.创建的SolrCloud,生成实体配置文件
- 5.修改conf目录下的schema.xml文件,主要是name对应到HBase中存储的column内容。特别注意时间类型
- 6.初始化 collection实例并将配置文件上传到 zookeeper
- 7.创建collection
- 8.创建 Morphline 配置文件
- 9.创建 Lily HBase Indexer 配置
- 10.注册 Lily HBase Indexer Configuration 和 Lily HBase Indexer Service
- 11.同步数据
- 12.批量同步索引
- 13.设置多个indexer
- 14.扩展命令
- 15.问题
- 16.参考资料:
0.前期声明
本文章中有变量为用户自定义,为了行文方便,文章中使用安装环境时所使用的路径、命名。
- Collection名字:humanCollection
- 配置文件路径:/root/human
- 安装zookeeper的机器名:master,slave1,slave2,slave3,slave4
- CDH版本:5.15.0
- HBase版本:1.2.0
- Lily HBase Indexer版本:1.5
- Solr版本:4.10.3
1.HBase建表并添加数据,并且确定HBase表开启REPLICATION功能(1表示开启replication功能,0表示不开启,默认为0 )
- 创建表
create '表名', {NAME => '列族名',NUMREGIONS => 5,SPLITALGO => 'HexStringSplit',REPLICATION_SCOPE => 1}
- 表已存在:
disable '表名'
alter '表名',{NAME => '列族名', REPLICATION_SCOPE => 1}
enable '表名'
2.HBase启用复制(在CM的hbase上搜索复制,勾选启用复制)
3.准备中文分词包(如果需要中文分词的话)
1.根据solr和CDH的版本下载中文分词包,安装的solr是4.10.3,CDH版本是5.15.0,
lucene-analyzers-smartcn-4.10.3-cdh5.15.0.jar
2.将中文分词jar包分发到集群所有机器的Solr和YARN服务相关的目录
root@master:~# cp lucene-analyzers-smartcn-4.10.3-cdh5.15.0.jar /opt/cloudera/parcels/CDH/lib/hadoop-yarn
root@master:~# cp lucene-analyzers-smartcn-4.10.3-cdh5.15.0.jar /opt/cloudera/parcels/CDH/lib/solr/webapps/solr/WEB-INF/lib
3.重启才能生效
4.创建的SolrCloud,生成实体配置文件
solrctl --zk master:2181,slave1:2181,slave2:2181,slave3:2181,slave4:2181/solr instancedir --generate /root/human
**此时会在/root/human文件夹下生成一个conf文件夹
5.修改conf目录下的schema.xml文件,主要是name对应到HBase中存储的column内容。特别注意时间类型
关于schema.xml中的相关配置的详解
<schema name="example" version="1.5">
<fields>
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="_root_" type="string" indexed="true" stored="false"/>
<field name="name" type="text_general" indexed="true" stored="true"/>
<field name="content" type="text_general" indexed="false" stored="true" multiValued="true"/>
<field name="text" type="text_general" indexed="true" stored="false" multiValued="true"/>
<field name="_version_" type="long" indexed="true" stored="true"/>
<field name="数据库字段" type="text_ch" indexed="是否创建索引" stored="是否存储原始数据(如果不需要存储相应字段值,尽量设为false)" required="false" multiValued="false" />
fields>
<uniqueKey>iduniqueKey>
<types>
<fieldType name="date_range" class="solr.DateField"/>
<fieldType name="string" class="solr.StrField" sortMissingLast="true" />
<fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/>
<fieldType name="int" class="solr.TrieIntField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="float" class="solr.TrieFloatField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="double" class="solr.TrieDoubleField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
analyzer>
fieldType>
<fieldType name="text_en" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPossessiveFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPossessiveFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
analyzer>
fieldType>
<fieldType name="text_en_splitting" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="true">
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1" catenateNumbers="1" catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="0" catenateNumbers="0" catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
analyzer>
fieldType>
<fieldType name="text_ch" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.SmartChineseSentenceTokenizerFactory"/>
<filter class="solr.SmartChineseWordTokenFilterFactory"/>
analyzer>
fieldType>
types>
schema>
可选项:修改conf目录下的solrconfig.xml文件,将硬提交打开。会影响部分性能,根据需求去做。
<autoCommit>
<maxTime>${solr.autoCommit.maxTime:60000}</maxTime>
<openSearcher>true</openSearcher>
</autoCommit>
- 如果修改/root/human/conf下的配置文件schema.xml,需要重新上传加载,执行以下语句:
solrctl --zk master:2181,slave1:2181,slave2:2181,slave3:2181/solr instancedir --update humanCollection /root/human/conf
solrctl --zk master:2181,slave1:2181,slave2:2181,slave3:2181/solr collection --reload humanCollection
6.初始化 collection实例并将配置文件上传到 zookeeper
solrctl --zk master:2181,slave1:2181,slave2:2181,slave3:2181,slave4:2181/solr instancedir --create humanCollection /root/human/conf
登陆zk客户端查看节点:ls /solr/configs/humanCollection,该节点下有solrconfig.xml、scheme.xml等配置文件;ls /solr/collections/下有humanCollection
root@master:~# cd /opt/cloudera/parcels/CDH/lib/zookeeper/bin
root@master:/opt/cloudera/parcels/CDH/lib/zookeeper/bin# ./zkCli.sh
...
[zk: localhost:2181(CONNECTED) 0] ls /solr/configs/humanCollection
[mapping-FoldToASCII.txt, currency.xml, protwords.txt, scripts.conf, synonyms.txt, stopwords.txt, _schema_analysis_synonyms_english.json, velocity, admin-extra.html, solrconfig.xml.secure, update-script.js, _schema_analysis_stopwords_english.json, solrconfig.xml, admin-extra.menu-top.html, elevate.xml, schema.xml, clustering, spellings.txt, xslt, mapping-ISOLatin1Accent.txt, _rest_managed.json, lang, admin-extra.menu-bottom.html]
[zk: localhost:2181(CONNECTED) 1] ls /solr/collections
7.创建collection
- 默认参数
solrctl collection --create humanCollection
- 如果希望将数据分散到各个节点进行存储和检索,则需要创建多个shard,增加参数
solrctl --zk master:2181,slave1:2181,slave2:2181,slave3:2181,slave4:2181/solr collection --create humanCollection -s 4 -r 1 -m 10
其中:
-s表示设置分片Shard数为4,表示solrclound是4台机器
-r表示设置的replica数为1,表示1个副本
-m 默认值是1,表示最大shards数目
-c是指定zk上solr/configs节点下使用的配置文件名称
-a是允许添加副本
** 创建solr分片时,要根据实际情况定shard、replication,maxShardsPerNode,否则报错,注意三个数值:
numShards、replicationFactor、liveSolrNode,一个正常的solrCloud集群不容许同一个liveSolrNode上部署同
一个shard的多个replic,因此当maxShardsPerNode=1时,numShards*replicationFactor>liveSolrNode时,报
错。因此正确时因满足以下条件:numShards*replicationFactor s*r < liveSolrNode*m 以下是没有重启报错,所以一定要重启solr,否则中文分词会报错! 进入CM管理页面:http://IP:7180/——选择Key-Value Store Indexer——配置——Morphlines 文件 id:表示当前morphlines文件的ID名称。 importCommands:需要引入的命令包地址。 extractHBaseCells:该命令用来读取HBase列数据并写入到SolrInputDocument对象中,该命令必须包含零个或者 多个mappings命令对象。 mappings:用来指定HBase列限定符的字段映射。 inputColumn:需要写入到solr中的HBase列字段。值包含列族和列限定符,并用’:‘分开。其中列限定符也可以使用通配符’*'来表示。 outputField:用来表示morphline读取的记录需要输出的数据字段名称,该名称必须和solr中的schema.xml文件的字段名称保持一致,否则写入不正确。 type:用来定义读取HBase数据的数据类型,我们知道HBase中的数据都是以byte[]的形式保存,但是所有的内容在 Solr中索引为text形式,所以需要一个方法来把byte[]类型转换为实际的数据类型。type参数的值就是用来做这件 事情的。现在支持的数据类型有:byte,int,long,string,boolean,float,double,short和bigdecimal。当然你也可以指 定自定的数据类型,只需要实现com.ngdata.hbaseindexer.parse.ByteArrayValueMapper接口即可。 source:用来指定HBase的KeyValue那一部分作为索引输入数据,可选的有‘value’和’qualifier’,当为value的时候 表示使用HBase的列值作为索引输入,当为qualifier的时候表示使用HBase的列限定符作为索引输入。 在/root/human目录下创建一个morphline-hbase-mapper-humanCollection.xml文件,每个collection对应一个morphline-hbase-mapper-humanCollection.xml 文件,morphlineId不要和hbase的table名称相同。 当 Lily HBase Indexer 配置 XML文件的内容令人满意,将它注册到 Lily HBase Indexer Service。上传 Lily HBase Indexer 配置 XML文件至 ZooKeeper,由给定的 SolrCloud 集合完成此操作。 再次运行 问题: http://www.cnblogs.com/husky/p/solr.html 原因是zookeeper只设置了一个 错误示例: 正确示例 添加数据到HBASE,然后进入Solr的管理界面:http://IP:8983(CDH有可能为8984、8985)/solr 在q(query)里面输入HBase_Indexer_Test_cf1_name:xiaogang可以看到对应得HBase得rowkey 仔细观察11我们会发现一个问题,我们只记录了后面插入的数据,那原来就存在HBase的数据怎么办呢? 在运行命令的目录下必须有morphlines.conf文件,执行 那个process 。 如果没有morphlines.conf,则新建一个morphlines.conf文件,添加在CM中配置的morphline的文件内容: 然后,执行 参考:Lily HBase Batch Indexing for Cloudera Search 问题: 首先,命令中要指定morphlines.conf文件路径和morphline-hbase-mapper.xml文件路径。执行: 一般我们选择最新的那个process,我们将其拷贝或者添加到配置项中。进入到 /opt/cm-5.7.0/run/cloudera-scm-agent/process/1386-ks_indexer-HBASE_INDEXER/morphlines.conf 或者加上 执行下面的命令 加上reducers–reducers 0就可以了 每一个Hbase Table对应生成一个Solr的Collection索引,每个索引对应一个Lily HBase Indexer 配置文件morphlines.conf和morphline配置文件morphline-hbase-mapper.xml,其中morphlines.conf可由CDH的Key-Value Store Indexer控制台管理,以id区分 。但是我们在CDH中没办法配置多个morphlines.conf文件的,那我们怎么让indexer和collection关联呢? solrctl hbase-indexer 这个问题有很多原因。一个是前面说的mappine文件不匹配,另一种是由于内存溢出。 这里面可以看到错误日志,如果是内存溢出的问题,需要调大。 解决:配置-资源管理-堆栈大小(字节) 50MB改为1G 第一种是因为自己写的Spark同步和HBaseIndexer同时在跑,而数据是一直更新的,在批量插入的时候清空了数据会导致原本由HBaseIndexer的插入的数据删除掉了 第二种如HBase Indexer导致Solr与HBase数据不一致问题解决所说,由于HBase插入的WAL和实际数据是异步的,因此会产生“取不到数据”的情况,增加read-row=“never” 详情参考:stackoverflow 1.Solr官网文档 2.Solr Wiki 3.Solr Wiki DateRangeField 4.如何使用Lily HBase Indexer对HBase中的数据在Solr中建立索引 5.CDH使用Solr实现HBase二级索引 6.HBase+Solr 的 二级索引 实时查询 7.如何在CDH中使用Solr对HDFS中的JSON数据建立全文索引 8.hbase基于solr配置二级索引 9.HBase建立二级索引的一些解决方案(Solr+hbase方案等) 10.基于Solr的Hbase二级索引 11.我与solr(五)–关于schema.xml中的相关配置的详解 12.我与solr(六)–solr6.0配置中文分词器IK Analyzer
solrctl --zk master:2181,slave1:2181,slave2:2181,slave3:2181,slave4:2181/solr collection --list
<response>
<lst name="responseHeader">
<int name="status">0int>
<int name="QTime">1255int>
lst>
<lst name="failure">
<str>org.apache.solr.client.solrj.impl.HttpSolrServer$RemoteSolrException:Error CREATEing SolrCore 'humanCollection_shard1_replica1': Unable to create core [humanCollection_shard1_replica1] Caused by: solr.SmartChineseSentenceTokenizerFactorystr>
<str>org.apache.solr.client.solrj.impl.HttpSolrServer$RemoteSolrException:Error CREATEing SolrCore 'humanCollection_shard3_replica1': Unable to create core [humanCollection_shard3_replica1] Caused by: solr.SmartChineseSentenceTokenizerFactorystr>
<str>org.apache.solr.client.solrj.impl.HttpSolrServer$RemoteSolrException:Error CREATEing SolrCore 'humanCollection_shard4_replica1': Unable to create core [humanCollection_shard4_replica1] Caused by: solr.SmartChineseSentenceTokenizerFactorystr>
<str>org.apache.solr.client.solrj.impl.HttpSolrServer$RemoteSolrException:Error CREATEing SolrCore 'humanCollection_shard2_replica1': Unable to create core [humanCollection_shard2_replica1] Caused by: solr.SmartChineseSentenceTokenizerFactorystr>
lst>
response>
8.创建 Morphline 配置文件
SOLR_LOCATOR : {
collection : humanCollection
zkHost : "$ZK_HOST"
}
morphlines : [
{
id : morphlineOfHuman
importCommands : ["org.kitesdk.morphline.**", "com.ngdata.**"]
commands : [
{
extractHBaseCells {
mappings : [
{
inputColumn : "human:features_type"
outputField : "features_type"
type : string
source : value
},
{
inputColumn : "human:createTime"
outputField : "createTime"
type : string
source : value
}
]
}
}
{
convertTimestamp {
field : createTime
inputFormats : ["yyyy-MM-dd HH:mm:ss"]
inputTimezone : Asia/Shanghai
outputFormat : "yyyy-MM-dd'T'HH:mm:ss.SSS'Z'"
outputTimezone : Asia/Shanghai
}
}
{ logDebug { format : "output record: {}", args : ["@{}"] } }
]
}
]
9.创建 Lily HBase Indexer 配置
<indexer table="对应Hbase里的表名" mapper="com.ngdata.hbaseindexer.morphline.MorphlineResultToSolrMapper" mapping-type="row">
<param name="morphlineFile" value="morphlines.conf"/>
<param name="morphlineId" value="morphlineOfHuman"/>
indexer>
10.注册 Lily HBase Indexer Configuration 和 Lily HBase Indexer Service
hbase-indexer add-indexer \
--name humanIndexer \
--indexer-conf /root/human/morphline-hbase-mapper-humanCollection.xml \
--connection-param solr.zk=master:2181,slave1:2181,slave2:2181,slave3:2181/solr \
--connection-param solr.collection=humanCollection \
--zookeeper master:2181,slave1:2181,slave2:2181,slave3:2181
hbase-indexer list-indexers --zookeeper master:2181,slave1:2181,slave2:2181,slave3:2181,slave4:2181查看是否添加成功。root@master:/opt/cloudera/parcels/CDH/lib/zookeeper/bin# hbase-indexer list-indexers --zookeeper master:2181,slave1:2181,slave2:2181,slave3:2181,slave4:2181
Number of indexes: 1
humanCollectionIndexer
+ Lifecycle state: ACTIVE
+ Incremental indexing state: SUBSCRIBE_AND_CONSUME
+ Batch indexing state: INACTIVE
+ SEP subscription ID: Indexer_humanCollectionIndexer
+ SEP subscription timestamp: 2018-12-10T09:36:29.514+08:00
+ Connection type: solr
+ Connection params:
+ solr.zk = master:2181,slave1:2181,slave2:2181,slave3:2181,slave4:2181/solr
+ solr.collection = humanCollection
+ Indexer config:
270 bytes, use -dump to see content
+ Indexer component factory: com.ngdata.hbaseindexer.conf.DefaultIndexerComponentFactory
+ Additional batch index CLI arguments:
(none)
+ Default additional batch index CLI arguments:
(none)
+ Processes
+ 4 running processes
+ 0 failed processes
hbase-indexer delete-indexer --name $IndxerName --zookeeper master:2181,slave1:2181,slave2:2181,slave3:2181,slave4:2181删除原来的indexerhbase-indexer list-indexers --zookeeper master:2181,slave1:2181,slave2:2181,slave3:2181,slave4:2181命令,查看是否创建成功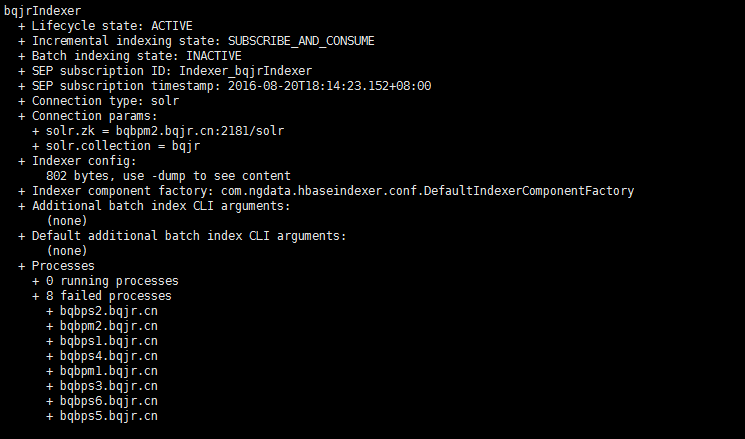
hbase-indexer add-indexer \
--name bqjrIndexer \
--indexer-conf $HOME/hbase-indexer/bqjr/morphline-hbase-mapper.xml \
--connection-param solr.zk=bqbpm2.bqjr.cn:2181/solr \
--connection-param solr.collection=bqjr \
--zookeeper bqbpm2.bqjr.cn:2181
hbase-indexer add-indexer \
--name bqjrIndexer \
--indexer-conf $HOME/hbase-indexer/bqjr/morphline-hbase-mapper.xml \
--connection-param solr.zk=bqbps1.bqjr.cn:2181,bqbpm1.bqjr.cn:2181,bqbpm2.bqjr.cn:2181/solr \
--connection-param solr.collection=bqjr \
--zookeeper bqbps1.bqjr.cn:2181,bqbpm1.bqjr.cn:2181,bqbpm2.bqjr.cn:2181
hbase-indexer delete-indexer -n smsdayIndexer --zookeeper nn1.hadoop:2181
11.同步数据
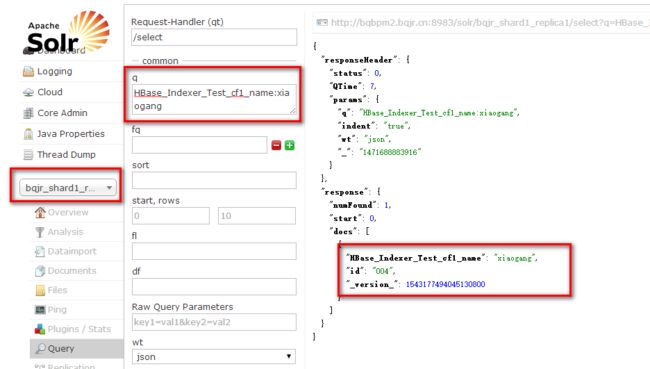
12.批量同步索引
find / |grep morphlines.conf$一般我们选择最新的morphlines : [
{
id : morphlineOfHuman
importCommands : ["org.kitesdk.morphline.**", "com.ngdata.**"]
commands : [
{
extractHBaseCells {
mappings : [
{
inputColumn : "human:features_type"
outputField : "features_type"
type : string
source : value
}
{
inputColumn : "human:createTime"
outputField : "createTime"
type : string
source : value
}
]
}
}
{
convertTimestamp {
field : createTime
inputFormats : ["yyyy-MM-dd HH:mm:ss"]
inputTimezone : Asia/Shanghai
outputFormat : "yyyy-MM-dd'T'HH:mm:ss.SSS'Z'"
outputTimezone : Asia/Shanghai
}
}
{ logDebug { format : "output record: {}", args : ["@{}"] } }
]
}
]
hadoop --config /etc/hadoop/conf.cloudera.yarn \
jar /opt/cloudera/parcels/CDH/lib/hbase-solr/tools/hbase-indexer-mr-*-job.jar \
-D 'mapred.child.java.opts=-Xmx1024m' \
--conf /etc/hbase/conf/hbase-site.xml \
--log4j /opt/cloudera/parcels/CDH/share/doc/search*/examples/solr-nrt/log4j.properties \
--hbase-indexer-file /root/human/morphline-hbase-mapper-humanCollection.xml \
--morphline-file /root/human/morphlines.conf \
--verbose \
--go-live \
--zk-host master:2181,slave1:2181,slave2:2181,slave3:2181/solr \
--collection humanCollection
-- 中文分词需要加上的,不用分词则不用加上这一句
-libjars /home/hadoop/package/lucene-analyzers-smartcn-4.10.3-cdh5.15.0.jar \
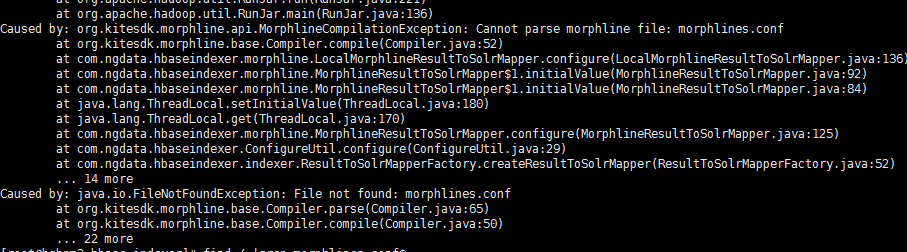
find / |grep morphlines.conf$--morphline-file /opt/cm-5.7.0/run/cloudera-scm-agent/process/1501-ks_indexer-HBASE_INDEXER/morphlines.confhadoop --config /etc/hadoop/conf \
jar /opt/cloudera/parcels/CDH/lib/hbase-solr/tools/hbase-indexer-mr-1.5-cdh5.7.0-job.jar \
--conf /etc/hbase/conf/hbase-site.xml \
--hbase-indexer-file $HOME/hbase-indexer/bqjr/morphline-hbase-mapper.xml \
--morphline-file /opt/cm-5.7.0/run/cloudera-scm-agent/process/1629-ks_indexer-HBASE_INDEXER/morphlines.conf \
--zk-host bqbpm1.bqjr.cn:2181,bqbps1.bqjr.cn:2181,bqbpm2.bqjr.cn:2181/solr \
--collection bqjr \
--go-live

hadoop --config /etc/hadoop/conf \
jar /opt/cloudera/parcels/CDH/lib/hbase-solr/tools/hbase-indexer-mr-job.jar \
--conf /etc/hbase/conf/hbase-site.xml \
--hbase-indexer-file $HOME/hbase-indexer/bqjr/morphline-hbase-mapper.xml \
--morphline-file /opt/cm-5.7.0/run/cloudera-scm-agent/process/1501-ks_indexer-HBASE_INDEXER/morphlines.conf \
--zk-host bqbpm2.bqjr.cn:2181/solr \
--collection bqjr \
--reducers 0 \
--go-live
13.设置多个indexer
SOLR_LOCATOR :{
# ZooKeeper ensemble
zkHost :"$ZK_HOST"
}
morphlines :[
{
id : XDGL_ACCT_FEE_Map
importCommands :["org.kitesdk.**","com.ngdata.**"]
commands :[
{
extractHBaseCells {
mappings :[
{
inputColumn :"cf1:ETL_IN_DT"
outputField :"XDGL_ACCT_FEE_cf1_ETL_IN_DT"
type :string
source : value
}
]
}
}
{ logDebug { format :"output record: {}", args :["@{}"]}}
]
},
{
id : XDGL_ACCT_PAYMENT_LOG_Map
importCommands :["org.kitesdk.**","com.ngdata.**"]
commands :[
{
extractHBaseCells {
mappings :[
{
inputColumn :"cf1:ETL_IN_DT"
outputField :"XDGL_ACCT_PAYMENT_LOG_cf1_ETL_IN_DT"
type :string
source : value
}
]
}
}
{ logDebug { format :"output record: {}", args :["@{}"]}}
]
}
]
14.扩展命令
solrctl instancedir --list
solrctl collection --list
solrctl instancedir --update User \$HOME/hbase-indexer/User
solrctl collection --reload User
solrctl --zk master:2181,slave1:2181,slave2:2181,slave3:2181,slave4:2181/solr instancedir --delete humanCollection
solrctl --zk master:2181,slave1:2181,slave2:2181,slave3:2181,slave4:2181/solr collection --delete humanCollection
solrctl collection --deletedocs User
rm -rf $HOME/hbase-indexer/User
hbase-indexer update-indexer -n userIndexer
hbase-indexer delete-indexer -n userIndexer --zookeeper master:2181,slave:2181
hbase-indexer list-indexers
[hadoop@db1 lib]$ solrctl --help
usage: /opt/cloudera/parcels/CDH-5.5.1-1.cdh5.5.1.p0.11/bin/../lib/solr/bin/solrctl.sh [options] command [command-arg] [command [command-arg]]
solrctl [options] command [command-arg] [command [command-arg]] ...
可选参数有:
--solr:指定 SolrCloud 的 web API,如果在 SolrCloud 集群之外的节点运行命令,就需要指定该参数。
--zk:指定 zk 集群solr目录。
--help:打印帮助信息。
--quiet:静默模式运行。
command 命令有:
init [--force]:初始化配置。
instancedir:维护实体目录。可选的参数有:
--generate path
--create name path
--update name path
--get name path
--delete name
--list
collection:维护 collections。可选的参数有:
[--create name -s <numShards>
[-a Create collection with autoAddReplicas=true]
[-c <collection.configName>]
[-r <replicationFactor>]
[-m <maxShardsPerNode>]
[-n <createNodeSet>]]
--delete name: Deletes a collection.
--reload name: Reloads a collection.
--stat name: Outputs SolrCloud specific run-time information fora collection.
`--list: Lists all collections registered in SolrCloud.
--deletedocs name: Purges all indexed documents from a collection.
core:维护 cores。可选的参数有:
--create name [-p name=value]]
--reload name: Reloads a core.
--unload name: Unloads a core.
--status name: Prints status of a core.
cluster:维护集群配置信息。可选的参数有:
--get-solrxml file
--put-solrxml file
15.问题

16.参考资料: