ES内部分片处理机制
前阵子看了一下es文档中关于shards原理的介绍,于是按照自己的理解总结了一下,基本上是照着原文翻译的,个别部分是按照自己的理解写的。
逆向索引:
与传统的数据库不同,在es中,每个字段里面的每个单词都是可以被搜索的。如hobby:"dance,sing,swim,run",我们在搜索关键字swim时,所有包含swim的文档都会被匹配到,es的这个特性也叫做全文搜索。
为了支持这个特性,es中会维护一个叫做“invertedindex”(也叫逆向索引)的表,表内包含了所有文档中出现的所有单词,同时记录了这个单词在哪个文档中出现过。
例:
当前有3个文档
Doc1:"brown,fox,quick,the"
Doc2:"fox,quick"
Doc3:"brown,fox,the"
那么es会维护如下一个数据结构:

这样我们随意搜索任意一个单词,es只要遍历一下这个表,就可以知道有些文档被匹配到了。
逆向索引里面不止记录了单词与文档的对应关系,它还维护了很多其他有用的数据。如:每个文档一共包含了多少个单词,单词在不同文档中的出现频率,每个文档的长度,所有文档的总长度等等。这些数据用来给搜索结果进行打分,如搜索单词apple时,那么出现apple这个单词次数最多的文档会被优先返回,因为它匹配的次数最多,和我们的搜索条件关联性最大,因此得分也最多。
逆向索引是不可更改的,一旦它被建立了,里面的数据就不会再进行更改。这样做就带来了以下几个好处:
1. 没有必要给逆向索引加锁,因为不允许被更改,只有读操作,所以就不用考虑多线程导致互斥等问题。
2. 索引一旦被加载到了缓存中,大部分访问操作都是对内存的读操作,省去了访问磁盘带来的io开销。
3. 因为逆向索引的不可变性,所有基于该索引而产生的缓存也不需要更改,因为没有数据变更。
4. 使用逆向索引可以压缩数据,减少磁盘io及对内存的消耗。
Segment:
既然逆向索引是不可更改的,那么如何添加新的数据,删除数据以及更新数据?为了解决这个问题,lucene将一个大的逆向索引拆分成了多个小的段segment。每个segment本质上就是一个逆向索引。在lucene中,同时还会维护一个文件commit point,用来记录当前所有可用的segment,当我们在这个commit point上进行搜索时,就相当于在它下面的segment中进行搜索,每个segment返回自己的搜索结果,然后进行汇总返回给用户。
引入了segment和commit point的概念之后,数据的更新流程如下图:
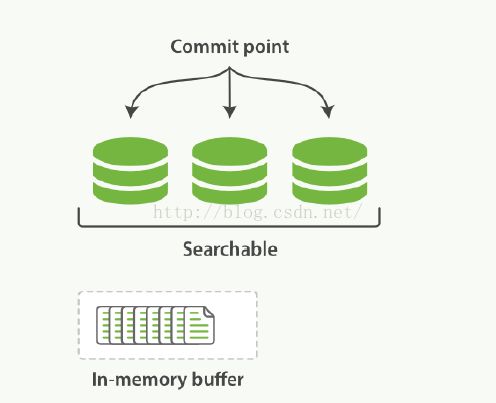
1. 新增的文档首先会被存放在内存的缓存中
2. 当文档数足够多或者到达一定时间点时,就会对缓存进行commit
a. 生成一个新的segment,并写入磁盘
b. 生成一个新的commit point,记录当前所有可用的segment
c. 等待所有数据都已写入磁盘
3. 打开新增的segment,这样我们就可以对新增的文档进行搜索了
4. 清空缓存,准备接收新的文档
文档的更新与删除:
segment是不能更改的,那么如何删除或者更新文档?
每个commit point都会维护一个.del文件,文件内记录了在某个segment内某个文档已经被删除。在segment中,被删除的文档依旧是能够被搜索到的,不过在返回搜索结果前,会根据.del把那些已经删除的文档从搜索结果中过滤掉。
对于文档的更新,采用和删除文档类似的实现方式。当一个文档发生更新时,首先会在.del中声明这个文档已经被删除,同时新的文档会被存放到一个新的segment中。这样在搜索时,虽然新的文档和老的文档都会被匹配到,但是.del会把老的文档过滤掉,返回的结果中只包含更新后的文档。
Refresh:
ES的一个特性就是提供实时搜索,新增加的文档可以在很短的时间内就被搜索到。在创建一个commit point时,为了确保所有的数据都已经成功写入磁盘,避免因为断电等原因导致缓存中的数据丢失,在创建segment时需要一个fsync的操作来确保磁盘写入成功。但是如果每次新增一个文档都要执行一次fsync就会产生很大的性能影响。在文档被写入segment之后,segment首先被写入了文件系统的缓存中,这个过程仅使用很少的资源。之后segment会从文件系统的缓存中逐渐flush到磁盘,这个过程时间消耗较大。但是实际上存放在文件缓存中的文件同样可以被打开读取。ES利用这个特性,在segment被commit到磁盘之前,就打开对应的segment,这样存放在这个segment中的文档就可以立即被搜索到了。
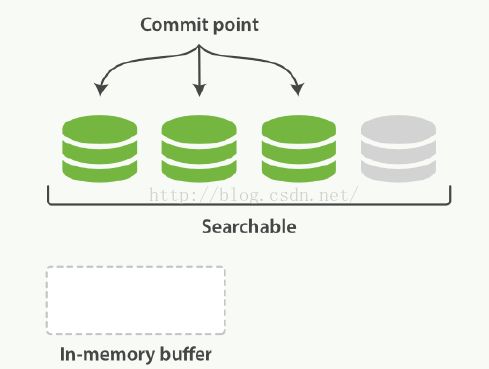
上图中灰色部分即存放在缓存中,还没有被commit到磁盘的segment。此时这个segment已经可以进行搜索。
在ES中,将缓存中的文档写入segment,并打开segment使之可以被搜索的过程叫做refresh。默认情况下,分片的refresh频率是每秒1次。这就解释了为什么es声称提供实时搜索功能,新增加的文档会在1s内就可以进行搜索了。
Refresh的频率通过index.refresh_interval:100s参数控制,一条新写入es的日志,在进行refresh之前,是在es中不能立即搜索不到的。
通过执行curl -XPOST127.0.0.1:9200/_refresh,可以手动触发refresh行为。
flush与translog
前面讲到,refresh行为会立即把缓存中的文档写入segment中,但是此时新创建的segment是写在文件系统的缓存中的。如果出现断电等异常,那么这部分数据就丢失了。所以es会定期执行flush操作,将缓存中的segment全部写入磁盘并确保写入成功,同时创建一个commit point,整个过程就是一个完整的commit过程。
但是如果断电的时候,缓存中的segment还没有来得及被commit到磁盘,那么数据依旧会产生丢失。为了防止这个问题,es中又引入了translog文件。
1. 每当es接收一个文档时,在把文档放在buffer的同时,都会把文档记录在translog中。
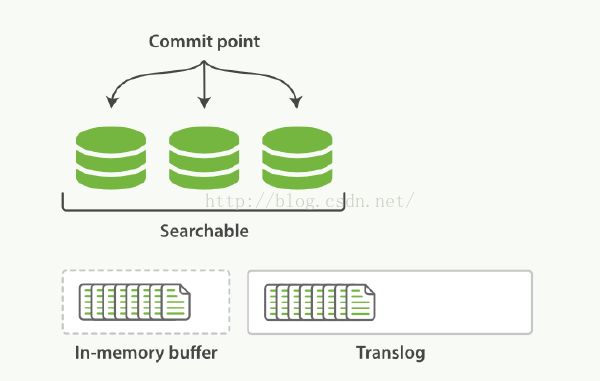
2. 执行refresh操作时,会将缓存中的文档写入segment中,但是此时segment是放在缓存中的,并没有落入磁盘,此时新创建的segment是可以进行搜索的。
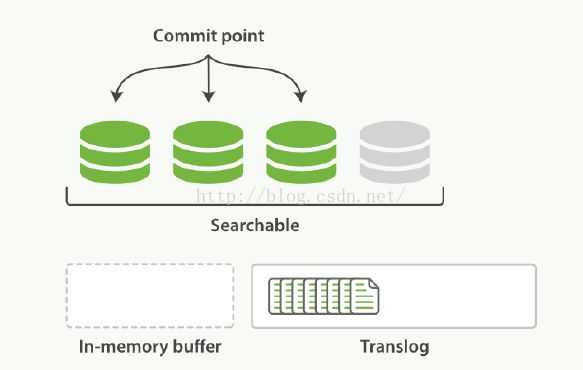
3. 按照如上的流程,新的segment继续被创建,同时这期间新增的文档会一直被写到translog中。
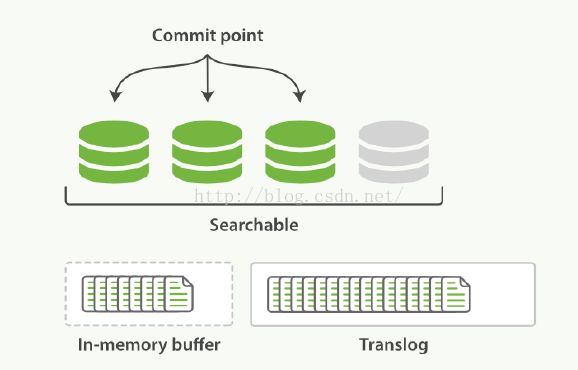
4. 当达到一定的时间间隔,或者translog足够大时,就会执行commit行为,将所有缓存中的segment写入磁盘。确保写入成功后,translog就会被清空。
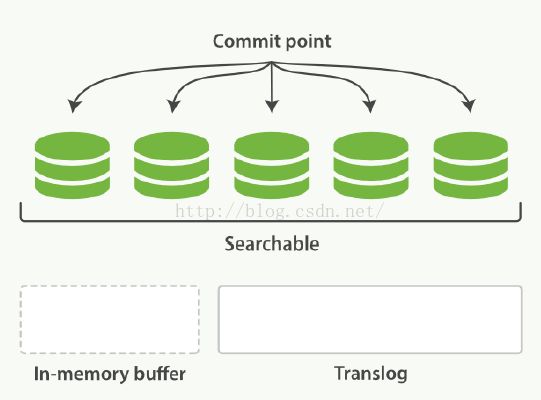
执行commit并清空translog的行为,在es中可以通过_flush api进行手动触发。
如:
curl -XPOST127.0.0.1:9200/tcpflow-2015.06.17/_flush?v
通常这个flush行为不需要人工干预,交给es自动执行就好了。同时,在重启es或者关闭索引之间,建议先执行flush行为,确保所有数据都被写入磁盘,避免照成数据丢失。通过调用sh service.sh start/restart,会自动完成flush操作。
Segment的合并
前面讲到es会定期的将收到的文档写入新的segment中,这样经过一段时间之后,就会出现很多segment。但是每个segment都会占用独立的文件句柄/内存/消耗cpu资源,而且,在查询的时候,需要在每个segment上都执行一次查询,这样是很消耗性能的。
为了解决这个问题,es会自动定期的将多个小segment合并为一个大的segment。前面讲到删除文档的时候,并没有真正从segment中将文档删除,而是维护了一个.del文件,但是当segment合并的过程中,就会自动将.del中的文档丢掉,从而实现真正意义上的删除操作。
当新合并后的segment完全写入磁盘之后,es就会自动删除掉那些零碎的segment,之后的查询都在新合并的segment上执行。Segment的合并会消耗大量的IO和cpu资源,这会影响查询性能。
在es中,可以使用optimize接口,来控制segment的合并。
如:
POST/logstash-2014-10/_optimize?max_num_segments=1
这样,es就会将logstash-2014-10中的segment合并为1个。但是对于那些更新比较频繁的索引,不建议使用optimize去执行分片合并,交给后台的es自己处理就好了。