Redis 之压缩列表
Redis 中的五种类型,在底层存储上并不是唯一的,而是依据 redisObject 中 encoding 来选择更适合的编码方式。比如上一篇介绍的字符串,就有 int、embstr、raw 三种,而且在不同的场景是动态变动的,比如 embstr 进行 append 操作后 encoding 就改成了 raw。
127.0.0.1:6379> hmset person name molaifeng age 18 sex female
OK
127.0.0.1:6379> object encoding person
"ziplist"
今天介绍的 ziplist 也就是压缩列表也是如此,列表、哈希、有序数组的在底层存储中都直接或间接的用到了它。通读了 ziplist 相关源码,发现精华就体现在压缩二字上,列表作为其辅助,共同构成了一种节约内存的线性数据结构。
压缩列表在存储结构上比较特殊,没有像 dict、sds 相关的结构体,而是使用 char *zl 字节数组来表示.
// ziplist.c
/* Create a new empty ziplist. */
unsigned char *ziplistNew(void) {
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE;
unsigned char *zl = zmalloc(bytes);
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0;
zl[bytes-1] = ZIP_END;
return zl;
}
下面使用一个 模拟的结构体 来介绍下各个成员。
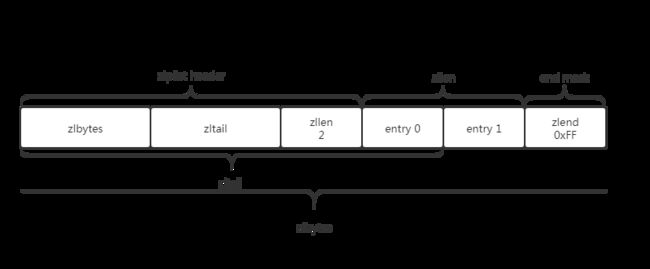
struct ziplist {
uint32_t uzlbytes; /* 4 个字节,表示整个 ziplist 占用的字节数 */
uint32_t zltail; /* 4 个字节,存储到链表最后一个节点的偏移值 */
uint16_t zllen; /* 2 个字节,存储到链表中节点的个数 */
uint8_t zlend; /* 1 个字节,硬编码 0xFF 标识链表的结束 */
} ziplist;
内存布局如下:
再来看看操作 ziplist_header 常用的宏
// ziplist.c
/* Return total bytes a ziplist is composed of. */
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))
zl 为 ziplist 字节数组的首地址,zlbyte 类型为 uint32_t,那么 (*((uint32_t*)(zl))) 就是指向ziplist 中 zlbyte 字段。使用这个宏就可以进而获取整个 ziplist 所占的内存总字节数了。
// ziplist.c
/* Return the offset of the last item inside the ziplist. */
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
*((uint32_t*)((zl) 就是上面的 ZIPLIST_BYTES 宏,指向 zlbyte,再加上 4 个字节,就指向 zltail 了,因为 zlbyte 本身占四个字节。获取 zltail 的偏移量,利用首地址 zltail 偏移,就获取最后一个 zlentry 。
// ziplist.c
/* Return the length of a ziplist, or UINT16_MAX if the length cannot be
* determined without scanning the whole ziplist. */
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))
参照之前的模拟结构体,通过首地址偏移 2*4 个字节,就得到了 zllen,也就知道了 ziplist 有多少个节点。
// ziplist.c
/* The size of a ziplist header: two 32 bit integers for the total
* bytes count and last item offset. One 16 bit integer for the number
* of items field. */
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
获取整个 ziplist header 占用的字节数 2*4+2 = 10,推导方法还是刚刚提到的模拟结构体。
// ziplist.c
/* Size of the "end of ziplist" entry. Just one byte. */
#define ZIPLIST_END_SIZE (sizeof(uint8_t))
ziplist 结尾标识所占的内存,1 个字节。
// ziplist.c
/* Return the pointer to the first entry of a ziplist. */
#define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE)
获取第一个 zlentry 节点地址,利用前面提到的 ZIPLIST_HEADER_SIZE 宏可以得知整个 ziplist header 所占的字节数,zl+ZIPLIST_HEADER_SIZE 就获取第一个节点地址了。
// ziplist.c
/* Return the pointer to the last entry of a ziplist, using the
* last entry offset inside the ziplist header. */
#define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl)))
获取最后一个节点的地址,ZIPLIST_TAIL_OFFSET 通过这个宏能知道 zltail 地址,然后 zl + zltail 就指向了最后一个节点。
// ziplist.c
/* Return the pointer to the last byte of a ziplist, which is, the
* end of ziplist FF entry. */
#define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)
获取 ziplist 的 zlend 地址,ZIPLIST_BYTES 表示整个 ziplist 所占的字节数,-1 就是向前偏移一个字节,就是 zlend 。
介绍完这些常用的宏,再回头看看一开始说 ziplist 是字节数组时贴出的代码段,就一目了然了。
压缩列表头部介绍完了,接下来就是重头戏压缩节点,知识点挺多的,且看我娓娓道来。
// ziplist.c
/* We use this function to receive information about a ziplist entry.
* Note that this is not how the data is actually encoded, is just what we
* get filled by a function in order to operate more easily. */
typedef struct zlentry {
unsigned int prevrawlensize; /* 存储 prevrawlen 所需的字节大小 */
unsigned int prevrawlen; /* 上一个节点的长度 */
unsigned int lensize; /* 存储 len 所需要的字节大小 */
unsigned int len; /* 当前节点的长度 */
unsigned int headersize; /* 当前节点的头部大小(prevrawlensize + lensize),即非数据域的大小 */
unsigned char encoding; /* 编码类型,说明节点存储的是整型还是字符串 */
unsigned char *p; /* 指向节点的指针,也就是当前元素的首地址 */
} zlentry;
别看上面的结构体有 7 个字段,其实有的字段是为了快速计算用的,比如 headersize,定位某个节点,偏移 headersize 个字节数,就能快速定位到节点所存储值的首地址。下面看看简化版的 zlentry 结构图。
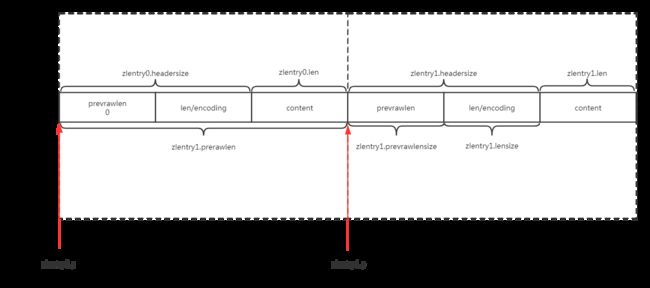
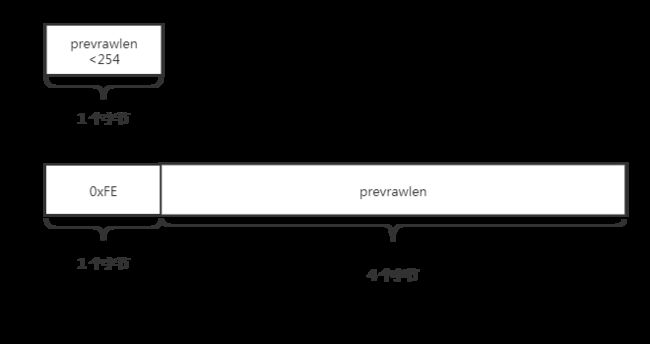
prevrawlen 表示前一个节点的字节长度,占 1 个或 5 个字节。
- 前一个节点长度小于 254 个字节点时,用 1 个字节表示。
- 前一个字节长度大于等于 254 个字节时,用 5 个字节表示。这 5 个字节中的第一个字节为 0xFE(也就是二进制的 254),后面的 4 个字节才是表示前一个节点的长度。至于为什么不是 255,因为在 ziplist 字节数组里提到, zlend 为结束标识,十六进制为 0xFF,其实换算成二进制就是 255,如此一来就形成了歧义,因此就用 0xFE。
假设当前节点的首地址为 p,那么 p-prevrawlen 就可以定位到上一个节点的首地址,反向迭代,从而实现压缩列表从尾到头的遍历。
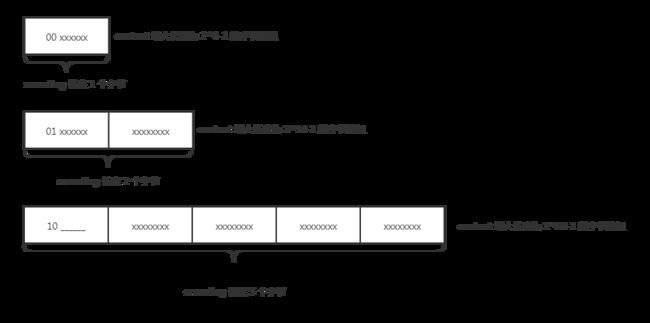
len/encoding,len 表示元素数据内容的长度,encoding 表示编码类型,也就是存储的值为字符串还是整数,这里面用到的算法就深深体现了压缩列表的压缩二字。
- 字符串
- 00 xxxxxx: 00 表示编码,长度使用 1 个字节表示,剩余的 6 位比特位用来表示具体的字节长度;
- 01 xxxxxx xxxxxxxx:01 表示编码,长度使用 2 个字节表示,剩余的 14 位比特用来表示具体的字节长度;
- 10______ xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxxx:10 用来表示编码,长度使用 5 个字节,10 接下来的 6 位比特不使用,再接下来的 4 个字节用来表示具体的字节长度。
- 整数,encoding 长度皆为 1 个字节,皆为 11 开头,第 3 位和第 4 位可判断整数的具体类型。
- 11 00 0000:表示 int16_t;
- 11 01 0000:表示 int32_t;
- 11 10 0000:表示 int64_t;
- 11 11 0000:3 字节长有符号整数;
- 11 11 1110:表示 int8_t;
- 11 11 xxxx:该项比较特殊,编码和 *p 是放在一起,该项 xxxx 表示实际的数据项,由于 0xFF与 zlend 冲突,0xFE 与 int8_t 编码冲突,0x10 与 3 字节有符号整数冲突,因此 0XFF/0XFE/0x00 均不使用,而最小的值为 0,最大的值为 12

具体的实现可参照下面宏,其中 ZIP_STR_ 为字符串相关宏, ZIP_INT_ 为整数相关宏。
// ziplist.c
#define ZIP_STR_MASK 0xc0 /* 1100 0000 */
#define ZIP_INT_MASK 0x30 /* 0011 000 */
#define ZIP_STR_06B (0 << 6) /* 0000 0000,字符串编码类型 */
#define ZIP_STR_14B (1 << 6) /* 0100 0000,字符串编码类型 */
#define ZIP_STR_32B (2 << 6) /* 1000 0000,字符串编码类型 */
#define ZIP_INT_16B (0xc0 | 0<<4)/* 1100 0000,整数编码类型 */
#define ZIP_INT_32B (0xc0 | 1<<4)/* 1101 0000,整数编码类型 */
#define ZIP_INT_64B (0xc0 | 2<<4)/* 1110 0000,整数编码类型 */
#define ZIP_INT_24B (0xc0 | 3<<4)/* 1111 0000,整数编码类型 */
#define ZIP_INT_8B 0xfe /* 1111 1110,整数编码类型 */
/* 4 bit integer immediate encoding */
#define ZIP_INT_IMM_MASK 0x0f /* 0000 1111 */
#define ZIP_INT_IMM_MIN 0xf1 /* 1111 0001 */
#define ZIP_INT_IMM_MAX 0xfd /* 1111 1101 */
#define ZIP_INT_IMM_VAL(v) (v & ZIP_INT_IMM_MASK)
规则就介绍到这,下面来看看 Redis 是如何解码压缩列表的元素再存储于 zlentry 结构体的。
// ziplist.c
/* Return a struct with all information about an entry. */
void zipEntry(unsigned char *p, zlentry *e) {
ZIP_DECODE_PREVLEN(p, e->prevrawlensize, e->prevrawlen);
ZIP_DECODE_LENGTH(p + e->prevrawlensize, e->encoding, e->lensize, e->len);
e->headersize = e->prevrawlensize + e->lensize;
e->p = p;
}
函数体内两个宏,两个赋值语句,实现从指针 p 中提取出节点的各个属性,并将属性保存到 zlentry 结构,然后返回 。
// ziplist.c
/* Return the length of the previous element, and the number of bytes that
* are used in order to encode the previous element length.
* 'ptr' must point to the prevlen prefix of an entry (that encodes the
* length of the previous entry in order to navigate the elements backward).
* The length of the previous entry is stored in 'prevlen', the number of
* bytes needed to encode the previous entry length are stored in
* 'prevlensize'. */
#define ZIP_DECODE_PREVLEN(ptr, prevlensize, prevlen) do { \
ZIP_DECODE_PREVLENSIZE(ptr, prevlensize); \
if ((prevlensize) == 1) { \
(prevlen) = (ptr)[0]; \
} else if ((prevlensize) == 5) { \
assert(sizeof((prevlen)) == 4); \
memcpy(&(prevlen), ((char*)(ptr)) + 1, 4); \
memrev32ifbe(&prevlen); \
} \
} while(0);
/* Return the number of bytes used to encode the length of the previous
* entry. The length is returned by setting the var 'prevlensize'. */
#define ZIP_DECODE_PREVLENSIZE(ptr, prevlensize) do { \
if ((ptr)[0] < ZIP_BIG_PREVLEN) { \
(prevlensize) = 1; \
} else { \
(prevlensize) = 5; \
} \
} while(0);
通过 ZIP_DECODE_PREVLEN 这个宏,把 ptr 节点的上一个节点的长度存储于 prevrawlen,prevrawlensize 则存储着具体的值。比如上一个节点长度为 255,那么 prevrawlen 存放 255,同时由于 prevrawlen 不小于 254 则用 5 个字节存放,于是 prevrawlensize 值为 5,又由于第一个字节为 0xFE,后四个字节存放具体的长度,便用 C 的 memcpy(&(prevlen), ((char*)(ptr)) + 1, 4) 来存放。
// ziplist.c
/* Decode the entry encoding type and data length (string length for strings,
* number of bytes used for the integer for integer entries) encoded in 'ptr'.
* The 'encoding' variable will hold the entry encoding, the 'lensize'
* variable will hold the number of bytes required to encode the entry
* length, and the 'len' variable will hold the entry length. */
#define ZIP_DECODE_LENGTH(ptr, encoding, lensize, len) do { \
ZIP_ENTRY_ENCODING((ptr), (encoding)); \
if ((encoding) < ZIP_STR_MASK) { \
if ((encoding) == ZIP_STR_06B) { \
(lensize) = 1; \
(len) = (ptr)[0] & 0x3f; \
} else if ((encoding) == ZIP_STR_14B) { \
(lensize) = 2; \
(len) = (((ptr)[0] & 0x3f) << 8) | (ptr)[1]; \
} else if ((encoding) == ZIP_STR_32B) { \
(lensize) = 5; \
(len) = ((ptr)[1] << 24) | \
((ptr)[2] << 16) | \
((ptr)[3] << 8) | \
((ptr)[4]); \
} else { \
panic("Invalid string encoding 0x%02X", (encoding)); \
} \
} else { \
(lensize) = 1; \
(len) = zipIntSize(encoding); \
} \
} while(0);
/* Extract the encoding from the byte pointed by 'ptr' and set it into
* 'encoding' field of the zlentry structure. */
#define ZIP_ENTRY_ENCODING(ptr, encoding) do { \
(encoding) = (ptr[0]); \
if ((encoding) < ZIP_STR_MASK) (encoding) &= ZIP_STR_MASK; \
} while(0)
/* Return bytes needed to store integer encoded by 'encoding'. */
unsigned int zipIntSize(unsigned char encoding) {
switch(encoding) {
case ZIP_INT_8B: return 1;
case ZIP_INT_16B: return 2;
case ZIP_INT_24B: return 3;
case ZIP_INT_32B: return 4;
case ZIP_INT_64B: return 8;
}
if (encoding >= ZIP_INT_IMM_MIN && encoding <= ZIP_INT_IMM_MAX)
return 0; /* 4 bit immediate */
panic("Invalid integer encoding 0x%02X", encoding);
return 0;
}
这一步则很关键了,通过 ZIP_DECODE_LENGTH 宏 解码了 encoding 相关逻辑。前面说了 encoding 中 00、01、10 开头的为字符串,同时对应的长度为 1、2、5;11 开头的为整数,长度固定为 1 个字节。对应到代码中就是 encoding 为具体的编码方式, lensize 存储着长度,len 存储着节点元素具体内容的长度。这里再强调下 len 这个字段,比如 encoding 的编码方式为 ZIP_STR_14B,也就是此节点存储的是字符串,那么 lensize 为 1 个字节,但字符串的长度则是存在 len 这个字段里;如果 encoding 为整数,那么需要注意一点是,当条件满足 (encoding >= ZIP_INT_IMM_MIN && encoding <= ZIP_INT_IMM_MAX) 时,len 字段为 0,因为此时的值存放在 encoding 的后四位。
最后聊下连锁更新。
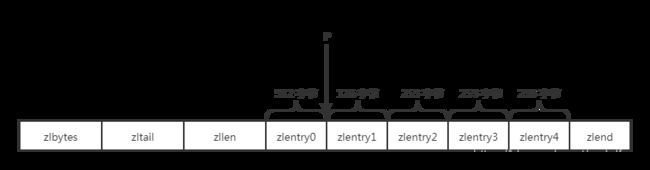
删除压缩列表中 P 位置 zlentry1 的节点:由于 zlentry1 之后节点长度皆为 253 个字节,那么这些节点的 prerawlensize 都为 1 个字节。当删除 zlentry1 节点后,zlentry2 的前置节点就为 zlentry0 了,而 zlentry0 的长度为 512 个字节,prerawlensize 字段需要 5 个字节,也就是加了 4 个字节(zlentry prerawlen 为 128 字节,其 prerawlensize 只需 1 个字节 ),那么 prerawlen 就扩展为 253+4= 257 个字节了。而 zlentry2 又作为 zlentry3 的前置节点,在 prerawlen 扩展为 257 个字节后,zlentry2 用来存储的 prerawlen 的prerawlensize 也需要加 4 个字节,后面的节点就以此类推。而每次扩展都将重新分配内存,导致效率很低。
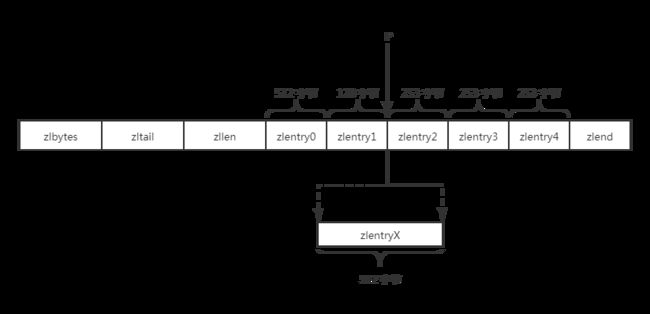
在压缩列表中 P 位置,添加个长度为 512 个字节的节点 zlentryX,分析逻辑和删除一样。
尽管连锁跟新的对于 Redis 性能有所影响,但是也得需要满足条件
- 首先, 压缩列表里要恰好有多个连续的、长度介于 250 字节至 253 字节之间的节点(之所以 250~253,可以参见上面的删除节点时的解释), 连锁更新才有可能被引发, 在实际中, 这种情况并不多见;
- 其次, 即使出现连锁更新, 但只要被更新的节点数量不多, 就不会对性能造成任何影响: 比如说, 对三五个节点进行连锁更新是绝对不会影响性能的;
上面提到的都是因为前置节点扩展导致连锁更新,那么缩小了呢。比如一开始前置节点长度为 512,后来变成了 125 了,那么当前节点存储前置节点 prerawlen 的 prerawlensize 是否也需要由 5 个字节缩小为 1 个字节呢。答案是不需要,在 Redis 中为了防止出现反复的缩小/扩展而出现的抖动(flapping),便只处理扩展的而不处理缩小的。
【注】 此博文中的 Redis 版本为 5.0。
参考书籍 :
【1】redis设计与实现(第二版)
【2】Redis 5设计与源码分析