coursera-使用python访问网络数据-密歇根大学
课程总体比较简单,是python for everyone的系列课程之一,零基础的朋友也好上手。
课程简单随记笔记在此记录一下。
week2
正则表达式
‘^From’ 以’From’为开头
‘.’匹配任意字符
‘.*’任意字符任意次数
\S 非空格字符
+ 表示一次或者多次 eg.\S+ 至少一个非空格字符
re.search()返回是否匹配正则表达式
re.findall()提取所有符合的字符串,返回一个列表
[0-9] 匹配一个数字
[]一个字符
默认贪婪匹配,即返回最长的符合的字符串
?代表不进行贪婪匹配
()提取的起始和结束
[^ ]一个非空格字符,这里^表示非
Quick Guide
^ Matches the beginning of a line
$ Matches the end of the line
. Matches any character
\s Matches whitespace
\S Matches any non-whitespace character
* Repeats a character zero or more times
*? Repeats a character zero or more times
(non-greedy)
+ Repeats a character one or more times
+? Repeats a character one or more times
(non-greedy)
[aeiou] Matches a single character in the listed set
[^XYZ] Matches a single character not in the listed set
[a-z0-9] The set of characters can include a range
( Indicates where string extraction is to start
) Indicates where string extraction is to end
week3
Socket使客户端和服务器端能够进行通信
TCP端口号
python 建立socket连接:
import socket
mysock=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
mysock.connect(('www.py4inf.com',80))HTTP协议
URL :协议名、主机名、文件名
请求-响应周期:
请求新页面GET请求、连接服务器、响应返回页面
收到、取回、显示
mysock.send('GET http://...// HTTP/1.0\n\n')
while True:
data=mysock.recv(512)
if(len(data)<-1)
break
print data
mysock.close()
fhand=urlib.urlopen()
for line in fhand:
print line.strip()
week4
网络爬虫
beautiful soup
from BeautifulSoup imort *
html=urllib.urlopen(url).read()
soup=BeautifulSoup(html)
tags=soup('a')
for tag in tags:
print tag.get('href',None)week5
webservice
python和java通过线路转化协议互相通信
中间格式为xml json
序列化、反序列化 : 应用程序《-》xml
xml可以想象成一个树
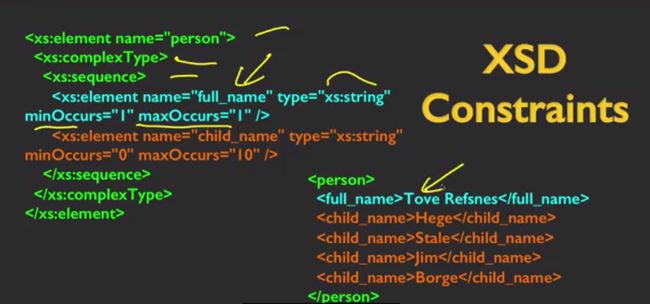
XML schema
用以验证XML格式的规范
XSD模式
xs:element
xs:sequence
xs:complexType
Python解析xml
用xml.etree.ElementTree
data = '''
Chuck
+1 734 303 4456
'''
tree = ET.fromstring(data)
print 'Name:',tree.find('name').text
print 'Attr:',tree.find('email').get('hide')本周测验代码如下
address = raw_input('Enter location: ')
count=0
url = address
print 'Retrieving', url
uh = urllib.urlopen(url)
data = uh.read()
#print 'Retrieved',len(data),'characters'
#print data
tree = ET.fromstring(data)
results = tree.findall('comments/comment')
#lat = results[0].find('geometry').find('location').find('lat').text
for result in results:
count+=int(result.find('count').text)
print count实例代码详见code文件夹xml1.py xml2.py geoxml.py
week6
第六周
json
实例代码json1.py json2.py
面向对象服务架构
使用API
测验一:
import json
import urllib
url = raw_input('Enter location: ')
print 'Retrieving', url
uh = urllib.urlopen(url)
data = uh.read()
print 'Retrieved',len(data),'characters'
info = json.loads(data)
print 'User count:', len(info)
count=0
#print info
for item in info['comments']:
count+=int(item['count'])
#print item['count']
print count测验二:
import urllib
import json
# serviceurl = 'http://maps.googleapis.com/maps/api/geocode/json?'
serviceurl = 'http://python-data.dr-chuck.net/geojson?'
while True:
address = raw_input('Enter location: ')
if len(address) < 1 : break
url = serviceurl + urllib.urlencode({'sensor':'false', 'address': address})
print 'Retrieving', url
uh = urllib.urlopen(url)
data = uh.read()
print 'Retrieved',len(data),'characters'
try: js = json.loads(str(data))
except: js = None
if 'status' not in js or js['status'] != 'OK':
print '==== Failure To Retrieve ===='
print data
continue
print json.dumps(js, indent=4)
lat = js["results"][0]["geometry"]["location"]["lat"]
lng = js["results"][0]["geometry"]["location"]["lng"]
print 'lat',lat,'lng',lng
location = js['results'][0]['formatted_address']
print location
print js['results'][0]['place_id']课程的code下载地址http://www.pythonlearn.com/code.zip