redis学习笔记(6)---压缩列表ziplist
ziplist
压缩列表是列表键和哈希键的底层实现之一。
当一个列表键只包含少量表项,并且每个列表项要么是小整数,要么是较短的字符串 ,那么redis就会使用压缩列表来作为列表键的底层实现。
当一个哈希键只包含少量key-value对,且每个key-value对的key和value要么是小整数,要么是较短字符串,那么redis就会使用ziplist作为哈希键的底层实现。
ziplist的实现:
ziplist的内存布局如下所示:

- zlbytes:4字节,记录整个压缩列表占用内存的字节数
- zltail:4字节,记录压缩列表尾部节点距离起始地址的偏移量
- zllen:2字节,记录压缩列表包含的节点数量
- entry:不定,列表中的每个节点
- zlend:1字节,特殊值0xFF,标记压缩列表的结束
因此通过下面的宏定义可以非常方便的求出各个字段的值
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
#define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE)
#define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl)))
#define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1) 一个简单的ziplist示意图如下:

zlbytes为0x50,表示压缩列表一共占用了0x50=80字节,其中zltail指示最后一个节点距离起始地址的偏移量为0x3C=60字节,因此p+60就为最后一个节点的起始地址,zllen=3表示列表中一共有3个节点。
ziplist节点定义如下:
typedef struct zlentry {
unsigned int prevrawlensize, prevrawlen;
unsigned int lensize, len;
unsigned int headersize;
unsigned char encoding;
unsigned char *p;
} zlentry;
- prevrawlen:前置节点的长度
- prevrawlensize:编码 prevrawlen 所需的字节大小
- len:当前节点的长度
- lensize:编码 len 所需的字节大小
- headersize:当前节点 header 的大小,等于 prevrawlensize + lensize
- encoding:当前节点值所使用的编码类型
- p:指向当前节点的指针
ziplist的创建
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
//即ZIPLIST_HEADER_SIZE=zlbytes(4)+zltail(4)+zllen(2)
unsigned char *ziplistNew(void) {
unsigned int bytes = ZIPLIST_HEADER_SIZE+1;//1字节的zlend
unsigned char *zl = zmalloc(bytes); //分配内存
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);//初始化各字段
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0;
zl[bytes-1] = ZIP_END; //ZIP_END=0xFF
return zl;//返回ziplist的起始地址
}这样就完成了一个压缩列表的创建了
加入一个元素
向ziplist中加入一个元素可以调用ziplistPush或ziplistInsert,二者的区别在于push只能在列表头部或尾部插入,而insert则可以在任意位置插入 。这两个函数最终都是通过调用__ziplistInsert来完成插入操作的。
//在zl的位置p处插入一个元素,元素的内容为s,s的长度为slen
static unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen;
unsigned int prevlensize, prevlen = 0;
size_t offset;
int nextdiff = 0;
unsigned char encoding = 0;
long long value = 123456789; /*任意一个非0值*/
zlentry tail;
/* 首先找到待插入位置的前一个节点的长度prevlen*/
if (p[0] != ZIP_END) {
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
} else {
unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl);
if (ptail[0] != ZIP_END) {
prevlen = zipRawEntryLength(ptail);
}
}
/* 首先判断节点是否可以被编码,并选择合适的编码方式 */
if (zipTryEncoding(s,slen,&value,&encoding)) {
reqlen = zipIntSize(encoding);
} else {
reqlen = slen;//若不能被编码,直接以字符串形式存储
}
/* 还需要存储前一个节点的长度和当前节点的长度 */
reqlen += zipPrevEncodeLength(NULL,prevlen);
reqlen += zipEncodeLength(NULL,encoding,slen);
/* 当插入位置不为tail时,需要保证后一个节点的prevlen字段足够存储当前节点的长度 */
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
/* 保存偏移量 */
offset = p-zl;
zl = ziplistResize(zl,curlen+reqlen+nextdiff);
p = zl+offset;
/* Apply memory move when necessary and update tail offset. */
if (p[0] != ZIP_END) { //当插入位置不为tail时
/* 将p之后的所有内容向后移动到p+reqlen */
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
/*将当前节点的长度经编码后存储到下一个节点的prevlen中*/
zipPrevEncodeLength(p+reqlen,reqlen);
/* 更新zltail的值 */
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
tail = zipEntry(p+reqlen);
if (p[reqlen+tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
} else { //插入到列表尾部
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
}
if (nextdiff != 0) {
offset = p-zl;
zl = __ziplistCascadeUpdate(zl,p+reqlen);
p = zl+offset;
}
/* 将新元素写到位置p */
p += zipPrevEncodeLength(p,prevlen);
p += zipEncodeLength(p,encoding,slen);
if (ZIP_IS_STR(encoding)) {
memcpy(p,s,slen);
} else {
zipSaveInteger(p,value,encoding);
}
ZIPLIST_INCR_LENGTH(zl,1);
return zl;
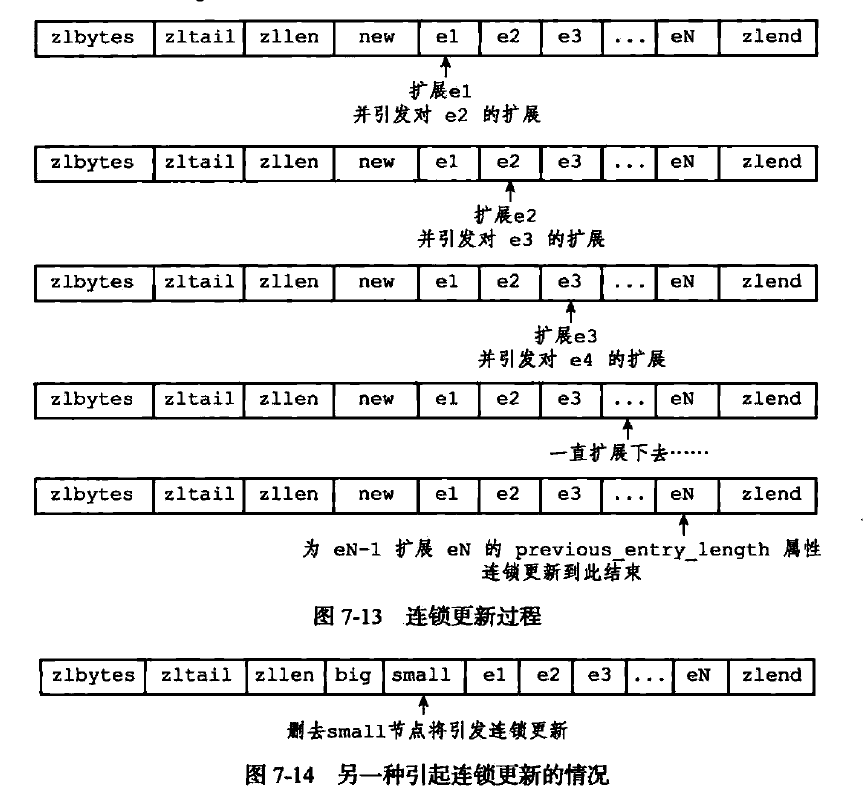
} 当加入新节点后,后一个节点需要保存新节点的长度信息,当后一个节点的长度字段在内存中占有的长度不足以表示该长度信息时,就需要对后一个节点进行更新,并扩展其内存。因此这个步骤可能会导致连锁更新。而删除操作也类似
//判断能否编码,返回1时可以编码。
static int zipTryEncoding(unsigned char *entry, unsigned int entrylen, long long *v, unsigned char *encoding) {
long long value;
if (entrylen >= 32 || entrylen == 0) return 0; //字符串长度只能为0~32
if (string2ll((char*)entry,entrylen,&value)) {
if (value >= 0 && value <= 12) {
*encoding = ZIP_INT_IMM_MIN+value;
} else if (value >= INT8_MIN && value <= INT8_MAX) {
*encoding = ZIP_INT_8B;
} else if (value >= INT16_MIN && value <= INT16_MAX) {
*encoding = ZIP_INT_16B;
} else if (value >= INT24_MIN && value <= INT24_MAX) {
*encoding = ZIP_INT_24B;
} else if (value >= INT32_MIN && value <= INT32_MAX) {
*encoding = ZIP_INT_32B;
} else {
*encoding = ZIP_INT_64B;
}
*v = value;
return 1;
}
return 0;
} string2ll()函数的返回值:
a)当传入的字符串只包含数字,如”1234”、”-456”这种情况时,才会返回1,并将字符串转化为数字存储在value中.当数字过大溢出时,也会返回0
b)否则都返回0
可以发现 zipTryEncoding()对字符串的长度和整数的大小进行了限制,只有在一定范围内才会进行编码
查找元素
unsigned char *ziplistFind(unsigned char *p, unsigned char *vstr, unsigned int vlen, unsigned int skip) {
int skipcnt = 0;
unsigned char vencoding = 0;
long long vll = 0;
while (p[0] != ZIP_END) { //从头遍历到最后一个节点
unsigned int prevlensize, encoding, lensize, len;
unsigned char *q;
ZIP_DECODE_PREVLENSIZE(p, prevlensize);
ZIP_DECODE_LENGTH(p + prevlensize, encoding, lensize, len);
q = p + prevlensize + lensize;
if (skipcnt == 0) {
if (ZIP_IS_STR(encoding)) { //如果没有编码,直接以字符串形式比较
if (len == vlen && memcmp(q, vstr, vlen) == 0) {
return p;
}
} else {
if (vencoding == 0) { //否则对vstr进行编码
if (!zipTryEncoding(vstr, vlen, &vll, &vencoding)) {
vencoding = UCHAR_MAX;
}
assert(vencoding);
}
if (vencoding != UCHAR_MAX) {
long long ll = zipLoadInteger(q, encoding);
if (ll == vll) { //然后再与节点数据比较
return p;
}
}
}
skipcnt = skip;
} else {
skipcnt--;
}
p = q + len;
}
return NULL;
}API

本文所引用的源码全部来自Redis3.0.7版本
redis学习参考资料:
https://github.com/huangz1990/redis-3.0-annotated
Redis 设计与实现(第二版)