利用Docker和阿里云容器服务轻松搭建分布式TensorFlow训练集群(上)
本系列将利用Docker技术在阿里云HPC和容器服务上,帮助您上手TensorFlow的机器学习方案
- 第一篇:打造TensorFlow的实验环境
- 第二篇:轻松搭建TensorFlow Serving集群
- 第三篇:打通TensorFlow持续训练链路
- 第四篇:利用Neural Style的TensorFlow实现,像梵高一样作画
- 第五篇:轻松搭建分布式TensorFlow训练集群(上)
本文是该系列中的第五篇文章, 将为您介绍如何在本机以及HPC和阿里云容器服务上快速部署和使用分布式TensorFlow训练集群。
简介
由于在现实世界里,单机训练大型神经网络的速度非常缓慢,这就需要运行分布式TensorFlow集群并行化的训练模型。
分布式TensorFlow集群由两种类型的服务器组成,一种是参数服务器,一种是计算服务器,它们通过高性能的gRPC库作为底层技术互相通信。参数服务器负责管理并保存神经网络参数的取值;计算服务器负责计算参数的梯度。并行训练中的更新模式有两种:同步更新和异步更新, 在同步更新模式下,所有服务器都会统一读取参数的取值,计算参数梯度,最后统一更新。而在异步更新模式下,不同服务器会自己读取参数,计算梯度并更新参数,而不需要与其他服务器同步。启动分布式深度学习模型训练任务也有两种模式:图内拷贝模式(In-graph Replication)和图间拷贝模式模式(Between-graph replication)。
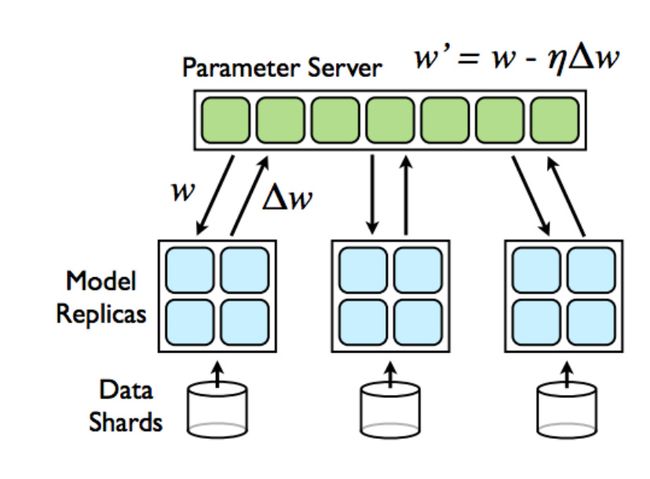
但是TensorFlow本身只是计算框架,要将其应用在生产环境,还是需要集群管理工具的资源调度,监控以及生命周期管理等能力。
在TensorFlow的官方文档介绍了如何在Kubernetes上部署和使用TensorFlow集群,而本文将为介绍如何在阿里云容器服务上玩转TensorFlow训练集群。
由于分布式TensorFlow比较复杂,我们会分为3个例子向您介绍:
- 图内拷贝模式(In-graph Replication)
- 图间拷贝模式模式(Between-graph replication)
- 基于Host网络的图间拷贝(Between-graph replication)
本文首先介绍的是图内拷贝模式,另外两种将在后面介绍
图内拷贝模式(In-graph Replication)
在In-graph Replication模式中,指整个集群由一个客户端来构建图,并且由这个客户端来提交图到集群中,worker只负责处理梯度计算的任务。In-graph的好处在于解耦了TensorFlow集群和训练应用之间的关系,这样就可以提前创建参数服务器和计算服务器,而这些角色本身无需额外的训练逻辑,只要通过join()方法等待。真正的训练逻辑只需要置于客户端应用里,有足够的灵活性。
但是对于机器学习的多数场景来说,海量数据是非常普遍的;而这个时候,只有一个客户端应用能提交数据和任务的弊端就体现出来了,客户端程序会变成整个训练过程的瓶颈。下篇文章会介绍的图间拷贝(Between-graph replication)就显得尤为重要了,它是TensorFlow分布式学习更为常用的模式。
使用docker-compose模板在本机上部署TensorFlow集群
1. 可以根据Dockerfile创建TensorFlow grpc server的镜像, 它使用的python脚本也在同一目录中
FROM registry.cn-hangzhou.aliyuncs.com/denverdino/tensorflow:0.12.0
RUN mkdir -p /var/worker
ADD . /var/worker
RUN chmod 777 /var/worker/*
ENTRYPOINT ["/var/worker/grpc_tensorflow_server.py"]当然也可以直接使用registry.cn-beijing.aliyuncs.com/tensorflow-samples/tf_grpc_server:0.12.0
2. 创建如下的docker compose模板
version: '2'
services:
worker-0:
image: registry-internal.cn-beijing.aliyuncs.com/tensorflow-samples/tf_grpc_server:0.12.0
restart: always
container_name: tf-worker0
command:
- --cluster_spec=worker|tf-worker0:2222;tf-worker1:2222,ps|tf-ps0:2222
- --job_name=worker
- --task_id=0
worker-1:
image: registry-internal.cn-beijing.aliyuncs.com/tensorflow-samples/tf_grpc_server:0.12.0
container_name: tf-worker1
restart: always
command:
- --cluster_spec=worker|tf-worker0:2222;tf-worker1:2222,ps|tf-ps0:2222
- --job_name=worker
- --task_id=1
ps-0:
image: registry-internal.cn-beijing.aliyuncs.com/tensorflow-samples/tf_grpc_server:0.12.0
container_name: tf-ps0
restart: always
command:
- --cluster_spec=worker|tf-worker0:2222;tf-worker1:2222,ps|tf-ps0:2222
- --job_name=ps
- --task_id=03. 利用docker-compose命令启动并查看容器状态
> docker-compose up -d
Creating network "distributed_default" with the default driver
Pulling worker-1 (registry-internal.cn-beijing.aliyuncs.com/tensorflow-samples/tf_grpc_server:0.12.0)...
0.12.0: Pulling from tensorflow-samples/tf_grpc_server
Digest: sha256:6bcd1b142c2cca4c8923424c4b33a4f8d4f31cb5e8b91793275cefc132d8cb29
Status: Downloaded newer image for registry-internal.cn-beijing.aliyuncs.com/tensorflow-samples/tf_grpc_server:0.12.0
Creating tf-worker1
Creating tf-worker0
Creating tf-ps0
> docker-compose ps
Name Command State Ports
-----------------------------------------------------------------
tf-ps0 /var/worker/gr Up 6006/tcp,
pc_tensorflo 8888/tcp
...
tf-worker0 /var/worker/gr Up 6006/tcp,
pc_tensorflo 8888/tcp
...
tf-worker1 /var/worker/gr Up 6006/tcp,
pc_tensorflo 8888/tcp
...4. 启动客户端
通过docker exec进入tf-ps0容器,在tf-ps0容器访问tf-worker0容器内的grpc server
> docker exec -it tf-ps0 /bin/bash
> cat client.py
import tensorflow as tf
c = tf.constant("Hello distributed TensorFlow!")
with tf.Session("grpc://tf-worker0:2222") as sess:
print(sess.run(c))
> python client.py
Hello distributed TensorFlow!可以看到我们能够成功的调用grpc://tf-worker0:2222, 并且输出了结果。
利用阿里云HPC和容器服务,部署TensorFlow集群服务端
1. 购买北京HPC后,按照北京HPC使用docker服务的文档在HPC机器上部署容器服务。
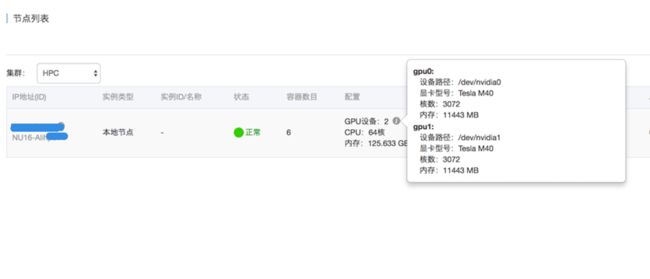
2. 当安装完成后,确认容器服务上支持了GPU,可以看到每台阿里云HPC上有两个GPU,其中还有每个GPU的配置
3. 为了简化部署,我们提供了一个预先构建基于GPU的TensorFlow grpc server的镜像
- registry-internal.cn-beijing.aliyuncs.com/tensorflow-samples/tf_grpc_server:0.12.0-devel-gpu
FROM registry.cn-hangzhou.aliyuncs.com/denverdino/tensorflow:0.12.0-devel-gpu
RUN mkdir -p /var/worker
ADD . /var/worker
RUN chmod 777 /var/worker/*
ENTRYPOINT ["/var/worker/grpc_tensorflow_server.py"]4. 用如下的docker-compose模板部署到HPC和阿里云容器服务上, 就创建了两个worker和一个PS(参数服务器)
version: '2'
services:
worker-0:
image: registry-internal.cn-beijing.aliyuncs.com/tensorflow-samples/tf_grpc_server:0.12.0-devel-gpu
restart: always
container_name: tf-worker0
command:
- --cluster_spec=worker|tf-worker0:2222;tf-worker1:2222,ps|tf-ps0:2222
- --job_name=worker
- --task_id=0
labels:
- aliyun.gpu=1
- com.docker.swarm.reschedule-policies=["on-node-failure"]
worker-1:
image: registry-internal.cn-beijing.aliyuncs.com/tensorflow-samples/tf_grpc_server:0.12.0-devel-gpu
container_name: tf-worker1
restart: always
command:
- --cluster_spec=worker|tf-worker0:2222;tf-worker1:2222,ps|tf-ps0:2222
- --job_name=worker
- --task_id=1
labels:
- aliyun.gpu=1
- com.docker.swarm.reschedule-policies=["on-node-failure"]
ps-0:
image: registry-internal.cn-beijing.aliyuncs.com/tensorflow-samples/tf_grpc_server:0.12.0-devel-gpu
container_name: tf-ps0
restart: always
command:
- --cluster_spec=worker|tf-worker0:2222;tf-worker1:2222,ps|tf-ps0:2222
- --job_name=ps
- --task_id=0
labels:
- com.docker.swarm.reschedule-policies=["on-node-failure"]注:
aliyun.gpu指定申请的GPU个数。阿里云容器服务负责分配GPU给容器,并且将主机上的GPU卡映射到容器内,这里同时会做到对用户透明。举例来说,如果用户申请一个GPU,而主机上只有/dev/nvidia1可用,将主机上的/dev/nvidia1映射为容器里的/dev/nvidia0,这样就会让用户程序与具体设备号解耦。- 由于ps-0是参数服务器,并不消耗大量的计算资源无需使用gpu
container_name用于指定容器的主机名, 例如worker-0的主机名为tf-worker0, ps-0的主机名为tf-ps0, 指定其的目的是用于服务发现- 可以通过reschedule-policies可以满足当宿主机节点失败时自动重新调度容器到新的节点
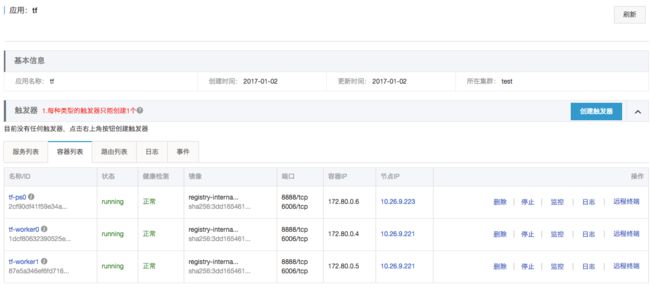
5. 几分钟之后编排模板部署完毕,可以看到worker-0,worker-1和ps对应的容器启动了。注意:worker-0和worker-1运行在同一个HPC宿主机上。
6. 登录到HPC机器可以发现两个容器分别绑定了两块GPU卡
> docker inspect tf-worker0 |grep '"Pid"'
"Pid": 48968,
> docker inspect tf-worker1 |grep '"Pid"'
"Pid": 49109,
> nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 367.48 Driver Version: 367.48 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla M40 Off | 0000:06:00.0 Off | 0 |
| N/A 39C P0 61W / 250W | 10876MiB / 11443MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla M40 Off | 0000:87:00.0 Off | 0 |
| N/A 33C P0 62W / 250W | 10876MiB / 11443MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 48968 C /usr/bin/python 10874MiB |
| 1 49109 C /usr/bin/python 10874MiB |
+-----------------------------------------------------------------------------+7. 但是在tf-worker0的容器中以为自己绑定了第一块GPU卡
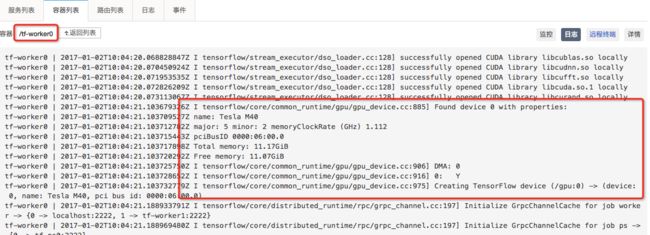
8. 同时在tf-worker1的容器中也以为自己绑定了第一块GPU卡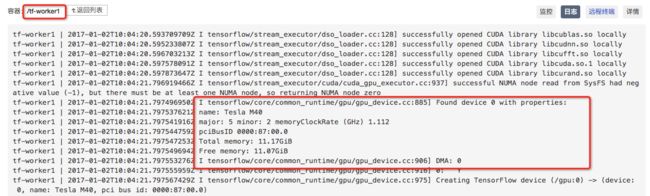
9. 这样我们就获得了一个好处:底层基础架构对于应用是透明的,让用户程序与具体设备号解耦。
利用阿里云HPC和容器服务,运行TensorFlow客户端
1. 以下为Client的代码,要做的就是构造写线性数据,其中斜率是2、截距是10,如果梯度下降算法正确的话最终w和b的输出应该也接近2和10。同时我们这里可看到我们将可变参数tf.Variable w和b绑定到ps-0,并且把不同的operation分配给了不同worker,最后将session指向其中一个worker的grpc的终端。
import tensorflow as tf
import numpy as np
train_X = np.linspace(-1, 1, 101)
train_Y = 2 * train_X + np.random.randn(*train_X.shape) * 0.33 + 10
X = tf.placeholder("float")
Y = tf.placeholder("float")
with tf.device("/job:ps/task:0/cpu:0"):
w = tf.Variable(0.0, name="weight")
b = tf.Variable(0.0, name="reminder")
# tf.initialize_all_variables() no long valid from
# 2017-03-02 if using tensorflow >= 0.12
with tf.device("/job:worker/task:0/gpu:0"):
init_op = tf.global_variables_initializer()
cost_op = tf.square(Y - tf.mul(X, w) - b)
with tf.device("/job:worker/task:1/gpu:0"):
train_op = tf.train.GradientDescentOptimizer(0.01).minimize(cost_op)
with tf.Session("grpc://tf-worker0:2222") as sess:
sess.run(init_op)
#epoch = 1
for i in range(10):
for (x, y) in zip(train_X, train_Y):
sess.run(train_op, feed_dict={X: x, Y: y})
#print ("Epoch: {}, w: {}, b: {}").format(epoch, sess.run(w), sess.run(b))
#epoch += 1
print ("Result is w: {}, b: {}").format(sess.run(w), sess.run(b))BTW: 这个程序只是为了演示可以显示的把不同的operation分配到不同的worker上,
2. 我们创建了一个包含上面python脚本的容器镜像
- registry-internal.cn-beijing.aliyuncs.com/tensorflow-samples/distribute_linear_regression:0.12.0
FROM registry.cn-hangzhou.aliyuncs.com/denverdino/tensorflow:0.12.0
RUN mkdir -p /var/worker
ADD client.py /var/worker
RUN chmod 777 /var/worker/client.py
CMD ["python", "/var/worker/client.py"]3. 用如下的docker-compose模板部署到阿里云HPC容器服务上,就可以触发TensorFlow并行训练
version: '2'
labels:
aliyun.project_type: "batch"
services:
linear:
image: registry-internal.cn-beijing.aliyuncs.com/tensorflow-samples/distribute_linear_regression:0.12.0
labels:
aliyun.remove_containers: "remove-none"注:
aliyun.project_type: "batch"指定该应用使用的是离线应用,如果希望了解离线计算的元语,可以参考在阿里云容器服务中运行离线任务文档aliyun.remove_containers代表容器运行完后是否删除,这里remove-none表示运行完之后不删除
6. 可以到容器服务的应用状态页面查看进度,当发现应用完成后,就可以查看日志

7. 从日志中可以看到拟合出的结果与真实值w=2,b=10非常接近

总结
可以看到,在阿里云容器服务上部署和使用TensorFlow分布式集群非常方便,比如TensorFlow集群的成员是在创建时刻通过cluster_spec指定,容器服务完全兼容Docker网络模型,可以方便地利用容器名进行服务发现。可以说,利用容器服务和Kubernetes在支持分布式TensorFlow训练集群上有异曲同工之妙,也为读者提供了在机器学习的实践中更多的选择。
利用阿里云HPC和容器服务,您除了可以获得高性能计算的洪荒之力,还可以简单的掌控这种能力,实现快速测试、部署机器学习应用,进而加速机器学习产品化的速度。容器服务了提供GPU资源的调度和管理,再加上对象存储,日志、监控等基础设施能力,帮助用户专注于利用机器学习创造商业价值。
最后的最后,要提示您的是:
在阿里云北京HPC上,使用容器服务是完全免费的
想了解更多容器服务内容,请访问 https://www.aliyun.com/product/containerservice
想了解如何在HPC上使用容器服务,请访问https://help.aliyun.com/document_detail/48631.html