thrift原理
- 初识Thrift
- 背景简介
- Thrift原理
初识Thrift
初次接触Thrift是学习自学netty的时候,之后在公司的一个项目开始实际得接触。这个项目是一个广告投放的项目,基础信息在DB和Redis中存放着,当用户的请求过来的时候需要匹配出一个合适的广告和策略,对时时性要求比较高,考虑到性能的问题,这个匹配的过程要用C来写。但是由于DB和redis存放的数据都是非常基础的数据,而且匹配的逻辑比较麻烦,如果全放到C端,当数据量大的时候性能还是不够。解决方案是起另一个程序定时的去将DB和Redis的数据做初步的处理,将合适的数据推送到C端的服务器内存中。这块的逻辑是非常麻烦的,我们也知道C开发起来是比较麻烦的,所以当时的决定是推送端由java来写,接收端由C来写。这就需要一种跨语言的RPC通信框架。
背景简介
Thrift简介
thrift是一个软件框架,用来进行可扩展且跨语言的服务的开发。它结合了功能强大的软件堆栈和代码生成引擎,以构建在 C++, Java, Go,Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, JavaScript, Node.js, Smalltalk, and OCaml 这些编程语言间无缝结合的、高效的服务。
thrift早期由facebook内部团队开发, 是为了解决facebook 系统中各系统间大数据量的传输通信以及系统之间语言环境不同需要跨平台的特性,属于远程方法调用的一种。在2007 年facebook 提交Apache 基金会将Thrift 作为一个开源项目。
RPC
RPC(Remote Procedure Call)—远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序布式多程序在内的应用程序更加容易。
RPC采用客户机/服务器模式。请求程序就是一个客户机,而服务提供程序就是一个服务器。首先,客户机调用进程发送一个有进程参数的调用信息到服务进程,然后等待应答信息。在服务器端,进程保持睡眠状态直到调用信息到达为止。当一个调用信息到达,服务器获得进程参数,计算结果,发送答复信息,然后等待下一个调用信息,最后,客户端调用进程接收答复信息,获得进程结果,然后调用执行继续进行。

简单的说,RPC就是从一台机器(客户端)上通过参数传递的方式调用另一台机器(服务器)上的一个函数或方法并得到返回的结果。RPC 会隐藏底层的通讯细节(不需要直接处理Socket通讯或Http通讯) RPC 是一个请求响应模型。客户端发起请求,服务器返回响应(类似于Http的工作方式) RPC 在使用形式上像调用本地函数(或方法)一样去调用远程的函数(或方法)。
IDL
IDL是Interface description language的缩写,指接口描述语言,是CORBA规范的一部分,是跨平台开发的基础。IDL是用来描述软件组件接口的一种计算机语言。IDL通过一种中立的方式来描述接口,使得在不同平台上运行的对象和用不同语言编写的程序可以相互通信交流。
IDL通常用于远程调用软件。 在这种情况下,一般是由远程客户终端调用不同操作系统上的对象组件,并且这些对象组件可能是由不同计算机语言编写的。IDL建立起了两个不同操作系统间通信的桥梁。
从本质上讲,OMG IDL接口定义语言不是作为程序设计语言体现在CORBA体系结构中的,而是用来描述产生对象调用请求的客户对象和服务对象之间的接口的语言。OMG IDL文件描述数据类型和方法框架,而服务对象则为一个指定的对象实现提供上述数据和方法。
Thrift原理
架构
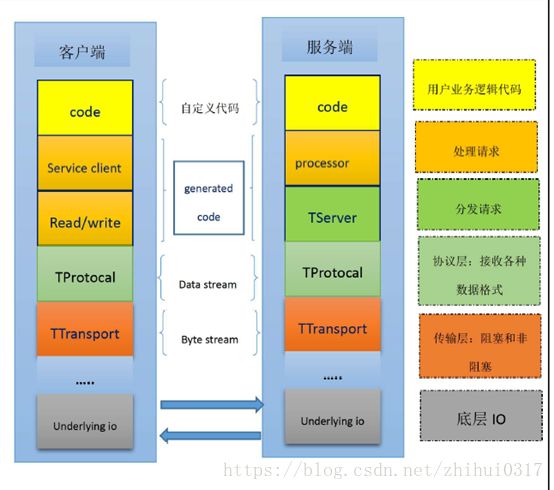
流程
前面说到,Thrift是一种RPC通信框架,在完成客户端到服务端的RPC调用过程中,Thrift主要用到了传输层、协议层和处理类三个主要的核心类。具体过程如下:
1.通过IDL定义一个接口的thrift文件,然后通过thrift的多语言编辑功能,将接口定义的thrift文件翻译成对应的语言版本的接口文件。
1)异步客户端类AsyncClient和异步接口AsyncIface,本节暂不涉及这些异步操作相关内容;
2)同步客户端类Client和同步接口Iface,Client类继承自TServiceClient,并实现了同步接口Iface;Iface就是根据thrift 文件中所定义的接口函数所生成;Client类是在开发Thrift的客户端程序时使用,Client类是Iface的客户端存根实现, Iface在开发Thrift服务器的时候要使用,Thrift的服务器端程序要实现接口Iface。
3)Processor类,该类主要是开发Thrift服务器程序的时候使用,该类内部定义了一个map,它保存了所有函数名到函数对象的映射,一旦Thrift接到一个函数调用请求,就从该map中根据函数名字找到该函数的函数对象,然后执行它;
4)参数类,为每个接口函数定义一个参数类,例如:为接口getInt产生一个参数类:getInt_args,一般情况下,接口函数参数类的命名方式为:接口函数名_args;
5)返回值类,每个接口函数定义了一个返回值类,例如:为接口getInt产生一个返回值类:getInt_result,一般情况下,接口函数返回值类的命名方式为:接口函数名_result;
2.客户端通过接口文件中的客户端部分生成的client对象,来调用thrift文件中的那些接口函数,但是,客户端调用接口函数时实际上调用的是接口函数的本地存根实现。
3.接口函数的存根实现将调用请求发送给thrift服务器端,Thrift会将客户端程序调用的函数名和参数传递给协议层(TProtocol),协议层将函数名和参数按照协议格式进行封装,然后封装的结果交给下层的传输层。此处需要注意:要与Thrift服务器程序所使用的协议类型一样,否则Thrift服务器程序便无法在其协议层进行数据解析;
4.传输层(TTransport)将协议层传递过来的数据进行处理,例如传输层的实现类TFramedTransport就是将数据封装成帧的形式,即“数据长度+数据内容”,然后将处理之后的数据通过网络发送给Thrift服务器;此处也需要注意:要与Thrift服务器程序所采用的传输层的实现类一致,否则Thrift的传输层也无法将数据进行逆向的处理;
5.Thrift服务端的协议类(TProtocol)将传输层处理之后的数据按照协议进行解封装,并将解封装之后的数据交个Processor类进行处理;
6.Thrift服务端的Processor类根据协议层(TProtocol)解析的结果,按照函数名找到函数名所对应的函数对象;
7.Thrift服务端使用传过来的参数调用这个找到的函数对象;
8.Thrift服务端将函数对象执行的结果交给协议层;
9.Thrift服务器端的协议层将函数的执行结果进行协议封装;
10.Thrift服务器端的传输层将协议层封装的结果进行处理,例如封装成帧,然后发送给Thrift客户端程序;
11.Thrift服务器端的传输层将协议层封装的结果进行处理,例如封装成帧,然后发送给Thrift客户端程序;
12.Thrift客户端的协议层将数据按照协议格式进行解封装,然后得到具体的函数执行结果,并将其交付给调用函数;
数据结构
- 基本类型
bool:布尔值
byte:8位有符号整数
i16:16位有符号整数,对应java中的short
i32:32位有符号整数,对应java中的int
i64:64位有符号整数,对应java中的long
double:64位浮点数
string:未知编码文本或二进制字符串
- 结构体类型
struct:定义公共的对象,类似于 C 语言中的结构体定义,在 Java 中是一个 JavaBean
- 容器类型
list:对应java中的ArrayList
set:对应java中的HashSet
map:对应java中的HashMap
- 异常类型
- 服务类型
service:对应服务的类
Thrift在客户端和服务器端传递数据的时候(包括发送调用请求和返回执行结果),都是将数据按照TMessage进行组装,然后发送;TMessage包括三部分:消息的名称、消息的序列号和消息的类型,消息名称为字符串类型,消息的序列号为32位的整形,消息的类型为byte类型,消息的类型共有如下17种;
协议(TProtocol)
Thrift可以让用户选择客户端与服务端之间传输通信协议的类别,在传输协议上总体划分为文本 (text) 和二进制 (binary) 传输协议,为节约带宽,提高传输效率,一般情况下使用二进制类型的传输协议为多数。常用协议有以下几种:常用协议有以下几种:
- TBinaryProtocol
是Thrift的默认协议,使用二进制编码格式进行数据传输,基本上直接发送原始数据
- TCompactProtocol
压缩的、密集的数据传输协议,基于Variable-length quantity的zigzag 编码格式
- TJSONProtocol
以JSON(JavaScript Object Notation)数据编码协议进行数据传输
- TDebugProtocol
常常用以编码人员测试,以文本的形式展现方便阅读
传输类(TTransport)
- TSocket
阻塞型 socket,用于客户端,采用系统函数 read 和 write 进行读写数据。
- TServerSocket
非阻塞型 socket,用于服务器端,accecpt 到的 socket 类型都是 TSocket(即阻塞型 socket)。
- TBufferedTransport和TFramedTransport
都是有缓存的,均继承TBufferBase,调用下一层 TTransport 类进行读写操作,吗,结构极为相似。其中 TFramedTransport 以帧为传输单位,帧结构为:4个字节(int32_t)+传输字节串,头4个字节是存储后面字节串的长度,该字节串才是正确需要传输的数据,因此TFramedTransport 每传一帧要比 TBufferedTransport 和 TSocket 多传4个字节。
- TMemoryBuffer
继承 TBufferBase,用于程序内部通信用,不涉及任何网络I/O,可用于三种模式:(1)OBSERVE模式,不可写数据到缓存;(2)TAKE_OWNERSHIP模式,需负责释放缓存;(3)COPY模式,拷贝外面的内存块到TMemoryBuffer。
- TFileTransport
直接继承 TTransport,用于写数据到文件。对事件的形式写数据,主线程负责将事件入列,写线程将事件入列,并将事件里的数据写入磁盘。这里面用到了两个队列,类型为 TFileTransportBuffer,一个用于主线程写事件,另一个用于写线程读事件,这就避免了线程竞争。在读完队列事件后,就会进行队列交换,由于由两个指针指向这两个队列,交换只要交换指针即可。它还支持以chunk(块)的形式写数据到文件。
- TFDTransport
是非常简单地写数据到文件和从文件读数据,它的 write 和 read 函数都是直接调用系统函数 write 和 read 进行写和读文件。
- TSimpleFileTransport
直接继承 TFDTransport,没有添加任何成员函数和成员变量,不同的是构造函数的参数和在 TSimpleFileTransport 构造函数里对父类进行了初始化(打开指定文件并将fd传给父类和设置父类的close_policy为CLOSE_ON_DESTROY)。
- TZlibTransport
跟 TBufferedTransport 和 TFramedTransport一样,调用下一层 TTransport 类进行读写操作。它采用
- TZlibTransport
继承 TSocket,阻塞型 socket,用于客户端。采用 openssl 的接口进行读写数据。checkHandshake()函数调用SSL_set_fd 将 fd 和 ssl 绑定在一起,之后就可以通过 ssl 的 SSL_read和SSL_write 接口进行读写网络数据。
- TSSLServerSocket
继承 TServerSocket,非阻塞型 socket, 用于服务器端。accecpt 到的 socket 类型都是 TSSLSocket 类型。
- THttpClient和THttpServer
是基于 Http1.1 协议的继承 Transport 类型,均继承 THttpTransport,其中 THttpClient 用于客户端,THttpServer 用于服务器端。两者都调用下一层TTransport 类进行读写操作,均用到TMemoryBuffer 作为读写缓存,只有调用 flush() 函数才会将真正调用网络 I/O 接口发送数据。
Tprocessor层
处理层就是服务器端定义的处理业务逻辑,它的主要代码是**Service.java文件中的Iface接口和Processor类。Iface接口:这个接口中的所有方法都是用户定义在IDL文件中的service的方法,它需要抛出TException这个检查异常,服务器端需要定义相应的实现类去 implements **.Iface 接口,完成服务的业务逻辑。Processor类:这个类中定义了一个processMap,里面包含了service中定义的方法,服务器端在构造这个Processor对象的时候,唯一需要做的就是把实现service(Iface)的对象作为参数传递给Processor的构造函数。Server层
server是Thrift框架中的最高层,它创建并管理下面的三层,同时提供了客户端调用时的线程调度逻辑。服务层的基类是TServer,它相当于一个容器,里面包含了TProcessor,TTransport,TProtocol,并实现对它们的管理和调度。其中,protocol 定义了消息是怎样序列化的;transport 定义了消息是怎样在客户端和服务器端之间通信的;server 用于从 transport 接收序列化的消息,根据 protocol 反序列化之,调用用户定义的消息处理器,并序列化消息处理器的响应,然后再将它们写回 transport。Thrift 模块化的结构使得它能提供各种 server 实现。下面列出了 Java 中可用的 server 实现:
- TSimpleServer
- TNonblockingServer
- THsHaServer
- TThreadedSelectorServer
- TThreadPoolServer
TSimpleServer
TSimpleServer的工作模式只有一个工作线程,循环监听新请求的到来并完成对请求的处理,TSimplerServer 接受一个连接,处理连接请求,直到客户端关闭了连接,它才会去接受一个新的连接。正因为它只在一个单独的线程中以阻塞 I/O 的方式完成这些工作,所以它只能服务一个客户端连接,其他所有客户端在被服务器端接受之前都只能等待,所以它只是在简单的演示时候使用。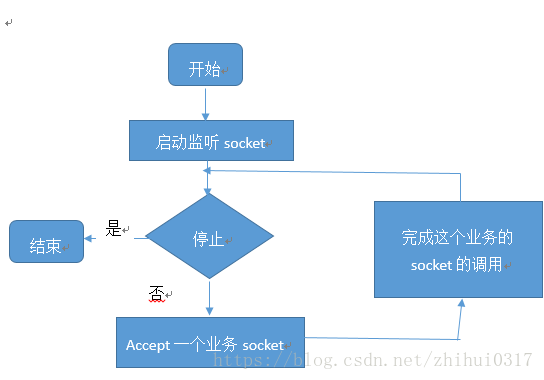
TnonblockingServer
TNonblockingServer 使用非阻塞的 I/O 解决了 TSimpleServer 一个客户端阻塞其他所有客户端的问题。它使用了java.nio.channels.Selector,通过调用 select(),它使得你阻塞在多个连接上,而不是阻塞在单一的连接上。当一个或多个连接准备好被接收/读/写时,select() 调用便会返回。TNonblockingServer 处理这些连接的时候,要么接受它,要么从它那读数据,要么把数据写到它那里,然后再次调用 select() 来等待下一个可用的连接。通用这种方式,server 可同时服务多个客户端,而不会出现一个客户端把其他客户端全部“饿死”的情况。
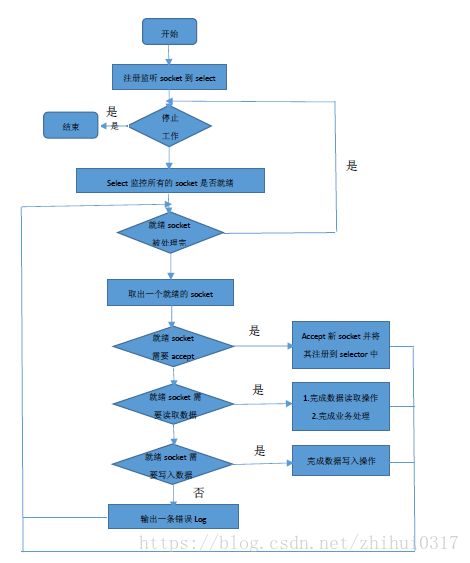
TNonblockingServer模式在业务处理上还是采用单线程顺序来完成,所有消息是被调用 select() 方法的同一个线程处理的。在业务处理比较复杂、耗时的时候,某些接口函数需要执行时间较长,多个调用请求任务依然是顺序一个接一个执行,此时该模式效率也不高,假设有10个客户端,处理每条消息所需时间为30000毫秒,那么,latency 和吞吐量分别是多少?当一条消息被处理的时候,其他9个客户端就等着被 select,所以客户端需要等待30秒钟才能从服务器端得到回应,吞吐量就是0.3个请求/秒,这个效率就相当低了。
THsHaServer
THsHaServer类是TNonblockingServer类的子类,TNonblockingServer模式中,采用一个线程来完成对所有socket的监听和业务处理,造成了效率的低下,THsHaServer模式的引入则是部分解决了这些问题。THsHaServer模式中,引入一个线程池来专门进行业务处理。
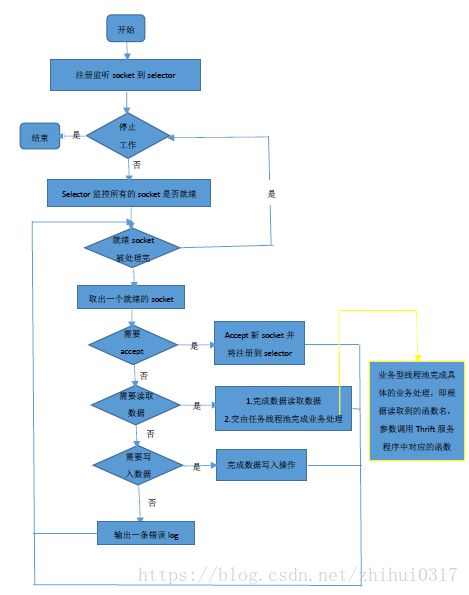
与TNonblockingServer模式相比,THsHaServer在完成数据读取之后,将业务处理过程交由一个线程池来完成,主线程直接返回进行下一次循环操作,效率大大提升。但是,主线程需要完成对所有socket的监听以及数据读写的工作,当并发请求数较大时,且发送数据量较多时,监听socket上新连接请求不能被及时接受。
TThreadPoolServer模式
TThreadPoolServer模式采用阻塞socket方式工作,主线程负责阻塞式监听“监听socket”中是否有新socket到来,业务处理交由一个线程池来处理。
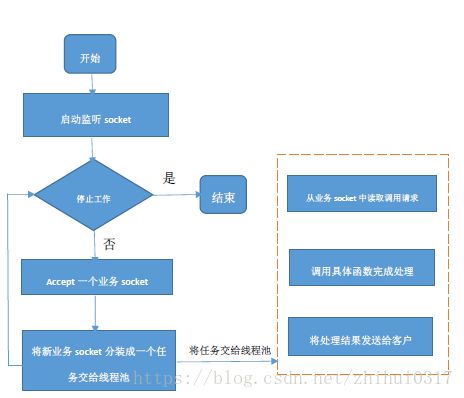
线程池模式中,数据读取和业务处理都交由线程池完成,主线程只负责监听新连接,因此在并发量较大时新连接也能够被及时接受。线程池模式比较适合服务器端能预知最多有多少个客户端并发的情况,这时每个请求都能被业务线程池及时处理,性能也非常高。线程池模式的处理能力受限于线程池的工作能力,当并发请求数大于线程池中的线程数时,新请求也只能排队等待。还有就是按照线程池模式,有一个专用的线程用来接受连接,一旦接受了一个连接,它就会被放入 ThreadPoolExecutor 中的一个 worker 线程里处理。worker 线程被绑定到特定的客户端连接上,直到它关闭。一旦连接关闭,该 worker 线程就又回到了线程池中。这意味着,在极端情况下如果有1万个并发的客户端连接,你就需要运行1万个线程。所以它对系统资源的消耗不像其他类型的 server 一样那么“友好”。
TthreadedSelectorServer
TThreadedSelectorServer模式是目前Thrift提供的最高级的模式,它内部有如果几个部分构成:
- 一个AcceptThread线程对象,专门用于处理监听socket上的新连接;
- 若干个SelectorThread对象专门用于处理业务socket的网络I/O操作,所有网络数据的读写均是由这些线程来完成;
- 一个负载均衡器SelectorThreadLoadBalancer对象,主要用于AcceptThread线程接收到一个新socket连接请求时,决定将这个新连接请求分配给哪个SelectorThread线程。
- 一个ExecutorService类型的工作线程池,在SelectorThread线程中,监听到有业务socket中有调用请求过来,则将请求读取之后,交个ExecutorService线程池中的线程完成此次调用的具体执行;

TThreadedSelectorServer模式中有一个专门的线程AcceptThread用于处理新连接请求,因此能够及时响应大量并发连接请求;另外它将网络I/O操作分散到多个SelectorThread线程中来完成,因此能够快速对网络I/O进行读写操作,能够很好地应对网络I/O较多的情况;TThreadedSelectorServer对于大部分应用场景性能都不会差,因此,如果实在不知道选择哪种工作模式,使用TThreadedSelectorServer就可以。