Python爬虫图片学习(一)
Python爬虫学习
一、Python安装与调用
-
python官网安装地址:
https://www.python.org/
-
python帮助手册:在本机的路径
C:\Users\Administrator\AppData\Local\Programs\Python\Python37\Doc -
创建一个1.py文件,右键打开.py文件,用IDLE方式打开。保存后直接run F5运行或者保存后F5运行:输出效果
hello在十个星号中间

定义一个用户变量登陆

用ipuut:定义变量值

二、一些定义:
- 特殊语句:
and 并且
or 或者
not 条件取反
= 赋值
== 比较
> 、< 、!=、 >= 、<=
-
变量名称的定义:
不能以
数字开头(如1name,下划线可以开头__)、变量不能带有特殊符号(下划线_可以)、变量名称区分大小写、(if、else、elif这些特殊关键字不能作为变量名称使用) -
关键字和内建函数不能作为变量:
import keyword输出不能作为变量名的关键字
 内建函数不能作为变量名使用,变量名一般是黑色:
内建函数不能作为变量名使用,变量名一般是黑色:help(type)可以查看内建函数或者在python帮助手册里输入built-in function查看所有内建函数

-
脚标取值的常用形式
name = "my name is wahaha"
print(name[开始脚标:结束脚标])
print(name[正数]): 从左往右索引值分别为0,1,2,3,4,5...16,超出报错
print(name[负数]): 从右往左索引值分别为-1,-2,-3,-4...-17,超出报错
print(name[0]): 输出m,第一个字符串索引值为0
print(name[-1]): 输出a,最后一个字符串
print(name[1:4]): 输出y n,不输出结束脚标4的索引值
print(name[:11]): 输出my name is ,输出往前所有数据,不输出结束脚标11的值
print(name[11:]): 输出wahaha,输出往后所有数据,包括开始脚标
三、Python数据结构(列表、字典、元祖、集合):
- 列表的应用
1.列表中的每一个元素都是可变的;
2.列表中的元素是有序的,也就是说每一个元素都有一 个位置;
3.列表可以容纳Python中的任何对象
列表 ( list ) c = [ val1,val2,val3] 列表可以容纳ython的任何对象
all_in_list=[
1, 整型
1.0, 浮点型
"a word", 字符串
print(1), 函数
True, 布尔值
[1,2], 列表套列表
(1,2), 元祖
{"key":"val"}] 字典
列表的增删改查:insert():插入 remove():删除 alist[]=""、del:修改
查看
alist = [1,2,3,4]
print(alist[1:3]) #输出[2,3]按索引值查看单个或多个数据
增加
insert(索引值,插入数据)应用: 按列表索引值插入,索引值存在则在索引值前增加数据,索引值不存在则往后添加一个新数据(反向索引则往前添加)
alist = [1,2,3,4] #正向索引值1 >>0 反向索引值1 >>-4
alist.insert(2,8)
print(alist) #输出[1,2,8,3,4,]
删除
remove(删除的数据): 直接remove(数据)需要删除的数据
alist = [1,2,'3',4]
alist.remove('3')
print(alist) #输出[1,2,4] 想删啥删啥
del alist[]: 按索引值进行删除
alist = [1,2,3,4]
del alist[0:3]
print(alist) #输出[4] 相当于删除选中索引值的数据,索引值不存在就不会删除
修改
alist[索引值]="修改的数据"
alist = [1,2,3,4] #正向索引值1 >>0 反向索引值1 >>-4
alist[1]=8
print(alist) #输出[1,8,3,4,] 按索引值修改,相当于修改2为8
alist[0:3]=8
print(alist) #输出[8,4] 按索引值区间修改,相当于把修改的数据,放入所索引值数据区间内,即便是修改的数据有很多条
列表的索引值取值实例图片

列表的实际应用实例图片

2. 字典的应用
1.字典中数据必须键值对的形式出现,且键只能为字符串、数字、浮点类型
2.逻辑上,键是不可重复,键重复以该变量索引值末尾的键值对为准输出,而值可以重复
3.键是不可修改变换的,但是值可以修改变换(可以是任何对象)
字典的增删改查
查看
指定键查看值
adict = {"a":"123","b":"456","c":"789"}
print(adict["a"]) #输出123 指定键取值
增加
update()方法: 往字典内添加多条数据
adict = {"a":"123","b":"456"}
adict.update({"c":"789","d":"999"}) #不要忘了写大括号
print(adict) #输出{'a': '123', 'b': '456', 'c': '789', 'd': '999'}
删除
del adict(需要删除的键): 指定键删除的键
adict = {"a":"123","b":"456","c":"789"}
del adict['a'] #[]中括号里的键如果是字符串必须加引号,其他类型的加不加都行
print(adict) #输出{'b': '456', 'c': '789'}
修改
通过指定键修改值的形式修改
adict = {"a":"123","b":"456","c":"789"}
adict["a"] = 456 #修改为数字型456,[]中括号里的键如果是字符串必须加引号,其他类型的加不加都行
print(adict) #输出'a': 456, 'b': '456', 'c': '789'}
字典通过键取值实例图片

字典不能通过值取键实例图片

通过字典键值对的特殊性,解决账号登陆时,列表中密码不对应账户的问题实例图片

- 元祖的应用
元祖可以理解成稳固版的列表,因为元祖是不可修改的,增删改都不可以, 但是元祖可以按索引值查看数据,查看方式和列表相同
查看
atuple = ("opo","12",1,1.036,8,3)
print(atuple[0:3]) #输出('opo', '12', 1)
- 集合的应用
每一个集合的元素都是无序、不重复的任意对象。可以通过集合去判断数据的从属关系, 还可以通过集合把数据结构中重复的元素删除,集合里边不能放集合、字典、列表,但可以放元祖
增加
add()方法: 去增加一个字符串、数字、浮点或元祖类型的数据
aset = {1,"a",2,2,"2",1.02,"2"}
aset.add(("qq","ww"))
print(aset) #输出{1, 2, 1.02, ('qq', 'ww'), 'a', '2'},因为是无序的
删除
把集合中重复的数据删除
aset = {1,"a",2,2,"2",1.02,"2"}
print(aset) #输出{1, 2, 1.02, 'a', '2'},里面重复的内容会去掉整合成一个新集合
discard(删除的值)方法: 指定值删除某条值数据
aset = {1,2,3,4,5}
aset.discard(5)
print(aset) #输出{1, 2, 3, 4},指定5删除掉
- 数据结构技巧
sorted()方法:会将列表中同类型的每个元素按长短、大小、字母顺序排序,不改变列表内容
注意:当列表存在不同类型时用此方法会报错(不适用于不同类型的列表)
alist = ["7","6","5","4","Ba","Bb","bA","aA","3","2","1"]
print(sorted(alist)) #输出['1', '2', '3', '4', '5', '6', '7', 'Ba', 'Bb', 'aA', 'bA']
zip()方法:会将两个以上的列表进行对应,就可以用此方法操作
注意:当两个列表元素数量不等时,以元素数量少的列表为准相对应
alist = [7,6,5,4,3,2,1]
blist = ["Ba","Bb","bA","aA","3","2","1"]
a_list = sorted(alist) #对列表alistj进行顺序排序
b_list = sorted(blist) #对列表blistj进行顺序排序
print(a_list) #输出[1, 2, 3, 4, 5, 6, 7]
print(b_list) #输出['1', '2', '3', 'Ba', 'Bb', 'aA', 'bA']
for a,b in zip(a_list,b_list): #a >>a_list b >>b_list,相当于for循环每次循环会安排序取出一条数据进行输出
print(a,"is",b) #这个子语句需要缩进,若不缩进会报错
#输出
1 is 1
2 is 2
3 is 3
4 is Ba
5 is Bb
6 is aA
7 is bA
sorted()与zip()方法实例图片

enumerate()函数的运用
默认情况下循环列表获取元素索引值:
a = ["a","b","c","d"]
for num,a in enumerate(a): #num的值对应索引值,默认为0,相当于enumerate(a)=[0>"a",1>"b",2>"c",3>"d"]相对应
print(a,"is",num) #所以fo循环中 num对应的是索引值0,a对应的是列表中元素
#输出:
a is 0
b is 1
c is 2
d is 3
修改索引值情况下循环列表获取元素索引值:
a = ["a","b","c","d"]
for num,a in enumerate(a,10): #num的值对应索引值,默认为0,相当于enumerate(a)=[10>"a",11>"b",12>"c",13>"d"]相对应
print(a,"is",num) #所以fo循环中 num对应的是索引值0,a对应的是列表中元素
#输出
a is 10
b is 11
c is 12
d is 13
enumerate()函数获取元素列表索引值用法实例图片

6. **查看类型的属性与帮助内容**
可以通过某些特殊内建函数去查看模块或者函数方法的帮助信息
help():查看类型、模块帮助信息,查看的信息全面
type():查看类型,丢进去一个模块或方法
dir(): 查看类型的属性和函数方法,
以random模块为例,查看类型的属性与帮助内容实例图片

四、python推导式的运用
- python之列表推导式的运用:
首先得知道
randge()函数的运用:
range(a,b,c)
a:计数从a开始,默认为0,当range(5),相当于range(0,5)
b:计数到b结束,但不包括5,当range(0,5),输出的是[0,1,2,3,4]
c:步长值,默认为1,相当每隔一个取一个。当range[0,8,2],输出的是[0,2,4,6]
append()方法用于在列表末尾添加新的对象。
range()函数的运用,python之列表推导式运用
python之列表推导式普通写法:
添加了步长值的用法
a = []
for i in range(1,8,2): #print(a)在for循环外的用法:每隔两位取值进入for循环,相当于每次for循环从range()中按步长值取出数字,返回给a列表,当循环完成后,输出的就是range(1,8)中取出来的所有值的a列表
a.append(i) #append()方法相当于给a列表添加新数据
print(a) #输出的是[1, 3, 5, 7]
print(a)在for循环外的用法:
a = []
for i in range(1,8): #print(a)在for循环外的用法:相当于每次for循环从range()中值取出数字,返回给a列表,当循环完成后,输出的就是range(1,8)中取出来的所有值的a列表
a.append(i)
print(a) #输出的是[1, 2, 3, 4, 5, 6, 7],如果是range(8)输出的是[0, 1, 2, 3, 4, 5, 6, 7]
print(a)在for循环内的用法:
a = []
for i in range(1,8): #print(a)在for循环内的用法,相当于每次for循环从range(1,8)中取出数字,依次将range(1,8)取出来的值放入a列表中,每次a列表的值会从原来的基础上增加一个值,每一次循环输出一次a列表
a.append(i)
print(a)
#输出
[1]
[1, 2]
[1, 2, 3]
[1, 2, 3, 4]
[1, 2, 3, 4, 5]
[1, 2, 3, 4, 5, 6]
[1, 2, 3, 4, 5, 6, 7]
python之列表推导式解析式:
b = [i for i in range(1,8)] #for i rang(1,8)将[1,2,3,4,5,6,7]的值传给了i,i再将值传递给for前面的i,注意:两个i的变量必须相同,相当于定义了for前边的i
print(b) #输出的是[1, 2, 3, 4, 5, 6, 7]
python之列表推导式实例图片:range()函数用法

enumerate()函数:循环列表时获取元素的索引值(也可以自己指定索引值)
enumerate(list,b)
list: 列表
b: 默认从0开始取,但是可以指定索引值从第几个去
- python之字典推导式
字典推导式的运用
adict = {i:i+1 for i in range(1,6)} #for循环将得到的数据传给i ,i再将得到的数据传for前面的i:i+1
print(adict) #输出{1: 2, 2: 3, 3: 4, 4: 5, 5: 6}
理解下面这个for循环就好理解上面字典推导式了:
adict = {}
for i in range(1,6):
adict.update({i:i+1}) #{}大括号不要忘记,相当for循环将range(1,6)得到的数据放入adict字典中
print(adict) #输出{1: 2, 2: 3, 3: 4, 4: 5, 5: 6}
python之字典推导式实例图片

五、if 条件判断语句:
-
if 条件:
子语句(子语句一定要有4个空格缩进)
-
if 条件 (多个条件可以在if后面加 and password ==“123”:) 子语句(子语句一定要有4个空格条件成立执行)
else: 子语句(条件不成立执行)

- 多分支条件语句

六、循环语句
while循环 、for循环
- 利用循环制作小游戏
猜一次:小游戏,看看能否猜中随机值
用if循环去做这个小游戏
猜十次:小游戏,看看能否猜中随机值
- while循环:根据条件进行循环(条件满足跑到死马)
用while循环作弊,可以容错十次(缺点:你得玩十次,猜对了还得往下猜)

break:猜中了立即跳出循环:
作弊手段智能化,猜对了就不用再假惺惺去猜了,直接跳循环

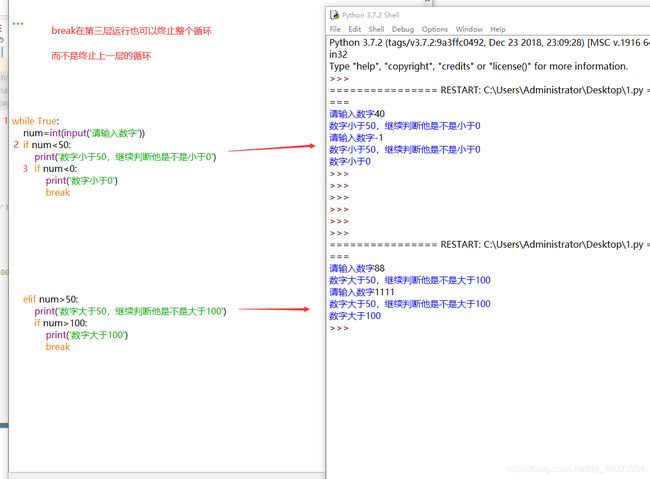
break的应用:终极关闭程序
终止实例代码:
while True:
num=int(input('请输入数字'))
if num<50:
print('数字小于50,继续判断他是不是小于0')
if num<0:
print('数字小于0')
break
elif num>50:
print('数字大于50,继续判断他是不是大于100')
if num>100:
print('数字大于100')
break
管你break在第几层,只要运行break这个循环得停止
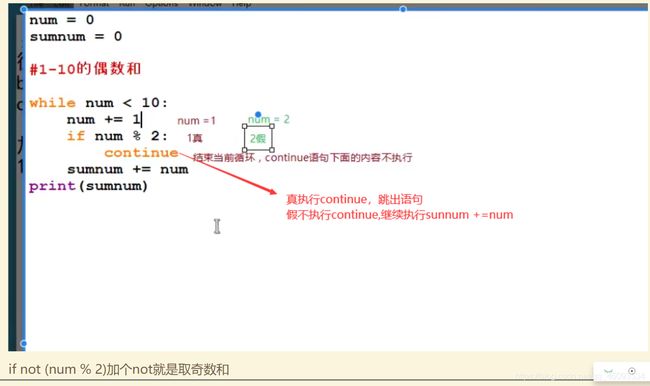
continue:结束此次循环,重新开始循环
continue被运行了,它下面代码不再执行,重新开始循环,知道这个while循环条件不在满足
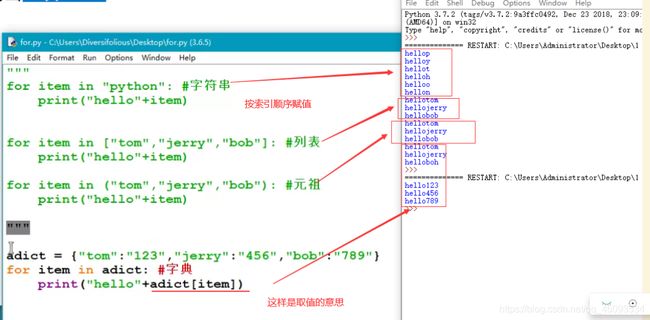
- for循环:根据变量赋值的次数进行循环
字符串、列表、元组、字典在for循环中依次取值实例图片
range()函数在for循环中依次循环取值示例图片

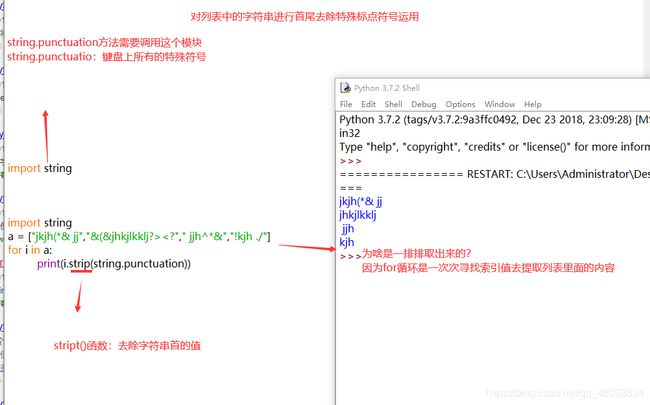
利用for循环将列表的值取出来并进行首尾去除特殊符号实例图片
七、文件对象的读取
f=open("E:\\aaaa\\a.txt","rb") open("读取文件的绝对路径","rb")r为读 b为二进制,以二进制的方式
去读取a.txt的内容,然后将内容赋值给变量f
print(f.read()) 打印f.read()读取a.txt的内容
f.close 关闭内存
f.seek(0,0) 读取光标移会初始位置
f.readline() 按行读取
f.readlines() 以列表的方式读取
在cmd默认登陆目录(Windows登陆时的home目录)中建立一个名叫test.txt的文件写入内容

- 第一步:建立文件对象(打开冰箱门)
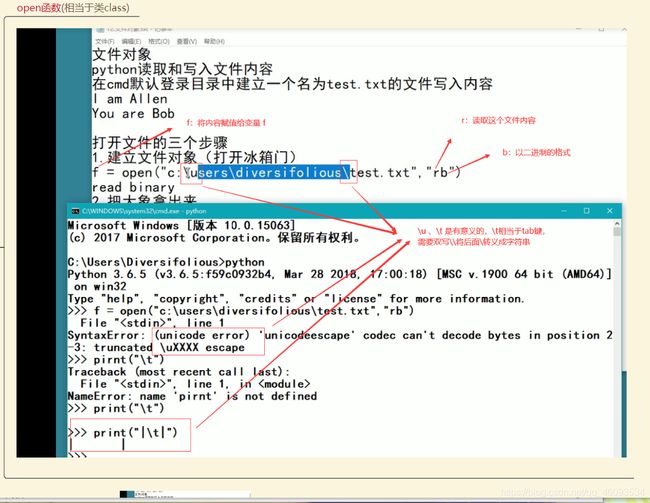
- 第二步:读取文件(把大象拿出来)
read函数读取文件
初次读取

第二次读取需要:f.seek(0,0)将光标移回起始位置,再次f.read()就可以读取内容了

f.readline()按行读取f.readlines()以列表的方式读取

- 第三步:关闭文件(关上冰箱门)
f.close()函数 因为前面open()它是占用了内存的,不关闭内存不会释放,影响运行
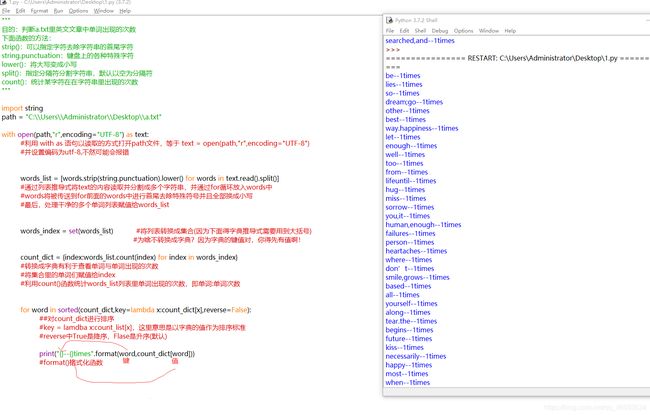
知识断点:判断a.txt里英文文章中单词出现的次数
代码:
目的:判断a.txt里英文文章中单词出现的次数
下面函数的方法:
strip():可以指定字符去除字符串的首尾字符
string.punctuation:键盘上的各种特殊字符
lower():将大写变成小写
split():指定分隔符分割字符串,默认以空为分隔符
count():统计某字符在在字符串里出现的次数
import string
path = "C:\\Users\\Administrator\\Desktop\\a.txt"
with open(path,"r",encoding="UTF-8") as text:
#利用 with as 语句以读取的方式打开path文件,等于 text = open(path,"r",encoding="UTF-8")
#并设置编码为utf-8,不然可能会报错
words_list = [words.strip(string.punctuation).lower() for words in text.read().split()]
#通过列表推导式将text的内容读取并分割成多个字符串,并通过for循环放入words中
#words将被传送到for前面的words中进行首尾去除特殊符号并且全部换成小写
#最后,处理干净的多个单词列表赋值给words_list
words_index = set(words_list) #将列表转换成集合(因为下面得字典推导式需要用到大括号)
#为啥不转换成字典?因为字典的键值对,你得先有值啊!
count_dict = {index:words_list.count(index) for index in words_index}
#转换成字典有利于查看单词与单词出现的次数
#将集合里的单词们赋值给index
#利用count()函数统计words_list列表里单词出现的次数,即单词:单词次数
for word in sorted(count_dict,key=lambda x:count_dict[x],reverse=False):
##对count_dict进行排序
#key = lamdba x:count_list[x],这里意思是以字典的值作为排序标准
#reverse中True是降序,Flase是升序(默认)
print("{}--{}times".format(word,count_dict[word]))
#format()格式化函数
判断a.txt里英文文章中单词出现的次数实例图片
八、文件对象写入
实现拷贝文件,打开两个文件。一个用读的形式打开需要拷贝的文件,另一个用写的方式打开需要生成的文件,把读取文件交给写入的文件,最后关闭两个文件
往a.txt文件写like,(a.txt存在会替换里面内容,不存在会创建一个a.txt)
f=open("E:\\aaaa\\1.txt","wb") 以写的方式打开a.txt
f.writelines([b"li",b"ke"]) 写入内容
f.close() 关闭
将a.txt的内容复制到b.txt,b.txt不存在则创建一个b.txt,存在则替换内容
rf = open("E:\\aaaa\\a.txt","rb") 以读取方式打开,赋值rf
wf = open("E:\\bbbb\\b.txt","wb") 以写入方式打开,赋值wf,创建-替换
data = rf.read() rf调用read()函读取a.txt内容然后赋值data
wf.write(data) wf调用write()函数将data内容写入到b.txt里(因为打开方式是写入)
rf.close() 关闭
wf.close() 关闭
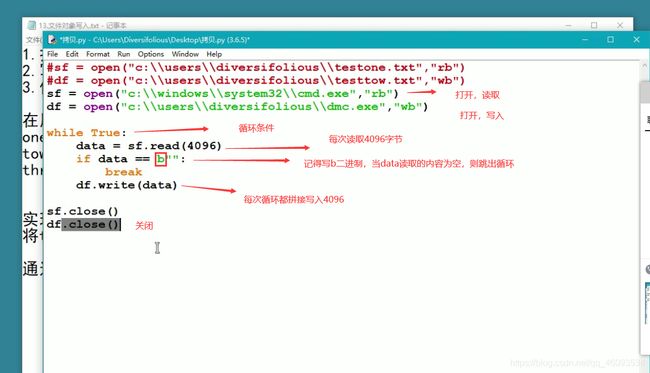
当限制读取数据是可以利用循环一点点读取
rf = open("E:\\aaaa\\a.txt","rb") 以读取方式打开,赋值rf
wf = open("E:\\bbbb\\b.txt","wb") 以写入方式打开,赋值wf,创建-替换
while True: 死循环
data = rf.read(110) 每次读取110字节数
if data == b"": 当data读取到空即读取完,就break跳出死循环
break
wf.write(data) 每次循环都往b.txt里拼接内容
rf.close() 关闭
wf.close() 关闭
- 第一步:打开文件(开冰箱)
在用户家目录中建立一个tsetone.txt的文件写入三行内容

2. 第二步:写入文件内容(放大象)
拷贝一个文件,将testone.txt文件的内容拷贝成testtow.txt(one的内容不能变化删除,而是产生一个新的tow文件)

通过文件对象cmd.exe对命令工具做复制
- 保存文件(关冰箱门)
f.close()函数 因为前面open()它是占用了内存的,不关闭内存不会释放,影响运行
九、函数和模块的定义
取随机值:
import random #调用模块 从此文件调用模块c:\users\administrator\appdata\local\programs\python\python37\lib\random.py
alist= ["tom","timi","niko"] #赋值
print(alist[random.randint(1,2)]) #根据索引值随机打印出变量alist的内容,需要根据alist的数据来指定,不然会报错
print(random.choice(alist)) #不用指定alist的数据就可以随机取值

- 创建模块
该模块可以被调用 ( 用import调用)
在模块中包含一个功能模块,函数的作用是返回20个星号
1·定义的模块名称不能以数字开头
2·不能和默认的模块重名
注意:调用方法函数必须有一个变量去接受方法函数的返回值,然后输出这个变量得到的就是返回的内容
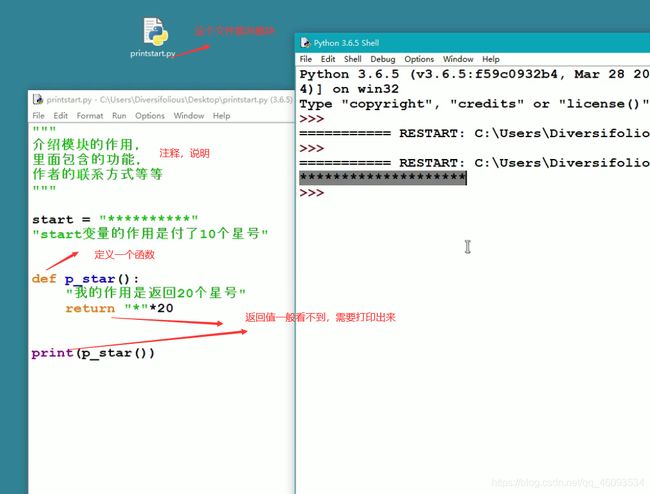
- 调用创建的模块
调用模块和打印模块必须在同一个目录或者调用模块在此文件中(c:\users\administrator\appdata\local\programs\python\python37\lib\random.py )

十、函数的形参实参与异常捕获
- 函数的形参和实参
函数的形参:在定义函数的时候,给定函形参变量,然后传参的时候传上两个变量去对应,那么形参变量就变为上传的变量导入函数中。
如:
def division (a,b) # a和b是给定的变量形参
num = a / b
return num
numa = 20
numb = 5
endnum = division(numa,numb) # 上传到函数里面取代 a,b
print(endnum)
函数的实参:就是在定义函数的时候给了一个指定的值,比如def division(1,2) 就是实参
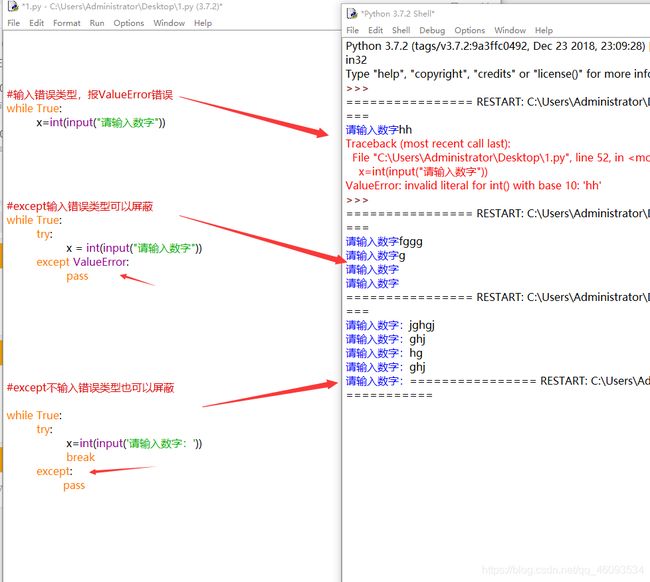
- 函数的异常捕获(找bug)
函数的异常捕获:预判代码某个位置可能会报错,提前将这个报错屏蔽,然后由开发者去进行提示
try (被捕获的子语句)可能出现运行错误的语句: 利用这个关键字去捕获异常
except (异常类型1,异常类型2,...)报错信息: 关键字除非,意思是如果出现这个报错将由它打印出异常的提示信息,更为友好直观
小技巧:expcept:不捕获异常类型信息也是可以的
当代码运行出现异常,用try捕获代码,然后用except提示友好的异常信息或者直接pass退出

异常捕获小技巧:
十一、面向对象编程
面向对象编程相对应的是面向过程编程(顺序,按顺序运行)

- 类 class
生物 >>动物 >>灵长类动物 >>人类 >> 男人 >>老人…(无限套娃,万物皆可为类)
当定义一个类的时候,系统会开辟一个内存空间,里面存储属性和方法
类的命名规则:大小驼峰命名法 两个单词首字母大写 两个单词首字符大写
属性:由变量组成
方法:由函数组成,实现功能,函数(self)括号内必须写self
创建对象:就是使用一个类,将类实例化,同一个类可以创建多个对象,类相当于模板
魔术方法:双下划线(__init__初始化方法),满足即调用
self的运用,代表实例化对象本身

将更多需要设置修改的东西放入类中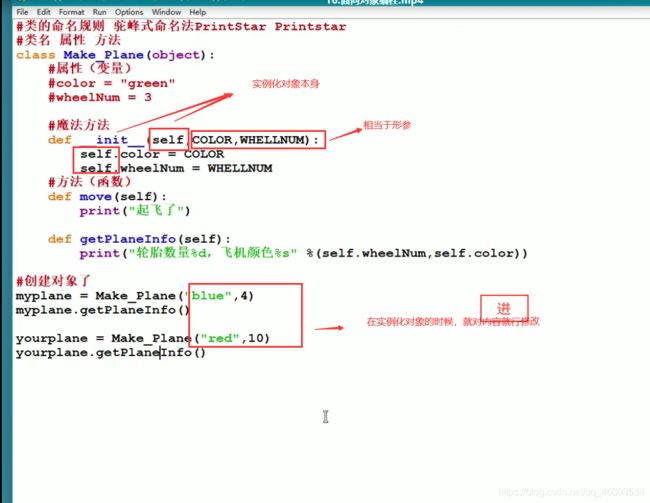
python之%s、%d、%f的用法
%s字符串 %d数字 %f浮点数
十二、爬虫获取网页图片
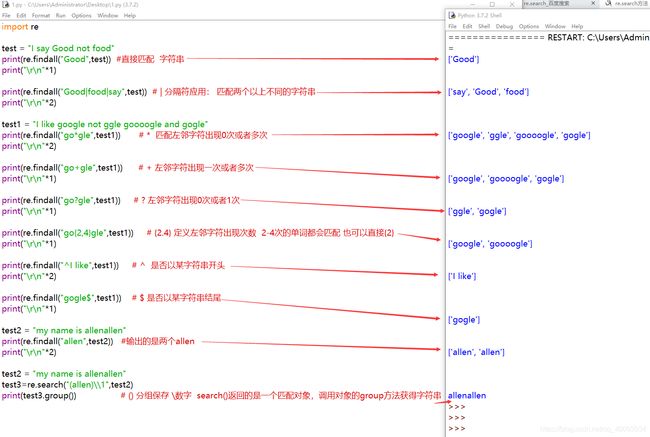
- python正则表达式
正则使用最多的是findall函数:
单个字符串匹配:
. 匹配单个任意字符
[] 写在中括号里面的内容会被逐一单个匹配
\d 匹配单个数字
\w 匹配 [0-9a-zA*Z_]
\s 匹配空白字符 空格 tab键

多个字符串匹配:
直接匹配 字符串
|: 分隔符应用 匹配两个不同的字符串 字符串|字符串
*: 匹配左邻字符出现0次或者多次
+:左邻字符出现一次或者多次
?:左邻字符出现0次或者1次
{2.4}:定义左邻字符出现次数 2-3此次都会匹配
^:是否以某字符串开头
$:是否以某字符串结尾
():分组保存 \数字
正则表达式分组保存,参考:https://www.cnblogs.com/erichuo/p/7909180.html
正则表达式中,group()用来提出分组截获的字符串,()用来分组
import re
a = "123abc456"
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0) #123abc456,返回整体
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1) #123
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2) #abc
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3) #456
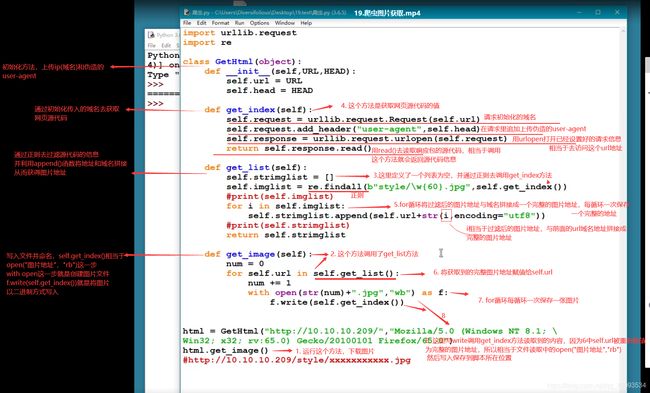
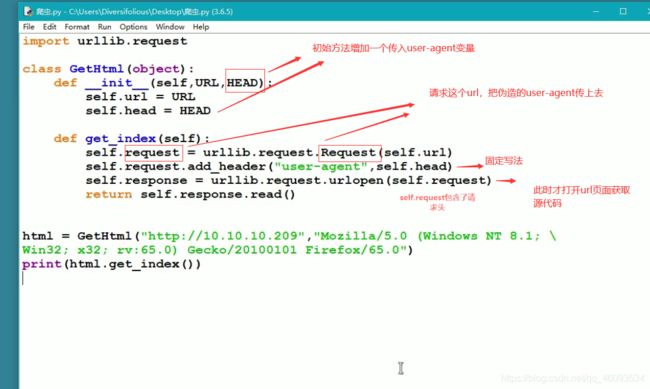
- 需要使用python中的urllib库爬取网页图片
第一步:获取网页的html代码
第二步:伪造一个user_agent头,不能会被封ip
第三步:通过正则表达式过滤出图片信息
第一步:获取网页的源代码:
import urllib.request: 通过request模拟浏览器发送请求
__init_: 初始化方法,即实例化对象时就使用这个方法给对象配置基本功能
urllib.request.urlopen(): 指定一个url,默认以GET方式发送请求
read(): 读取内容
add_hearder: 伪造一个user-agent

第二步:伪造user-agent
第三步:利用正则过滤图片信息并把图片下载下来