从0-1搭建Spark本地开发环境(idea)

1
文档编写目的
记录spark本地开发环境的搭建过程
环境依赖
操作系统 mac os
idea
scala 2.11.12
spark2.4.0 - 根据集群版本选择
jdk
2
Scala-2.11.12安装
下载连接
https://www.scala-lang.org/download/2.11.12.html

下载到scala目录,并进行解压
tar -zxvf scala-2.11.12.tgz
配置环境变量
vi ~/.bash_profile
# 添加scala path
# scala setting
export SCALA_HOME=/Users/jackbin/scala/scala-2.11.12
export PATH=$PATH:$SCALA_HOME/bin
# 刷新配置
source ~/.bash_profile在终端输入scala进行检验

3
Spark环境下载
下载连接
https://archive.apache.org/dist/spark/spark-2.4.0/
根据需要的集群环境选择下载的hadoop版本,这里使用的是CDH5,则下载hadoop2.6的版本

解压spark环境
tar -zxvf spark-2.4.0-bin-hadoop2.6.tgz配置环境变量
vi ~/.bash_profile
# 添加spark home配置
# spark setting
export SPARK_HOME=/Users/jackbin/spark-runtime/spark-2.4.0-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin终端输入spark-shell进行测试,spark配置完成

4
Idea构建Spark开发环境
新建maven项目

安装scala插件

项目添加scala支持

在main包下新建scala目录,在项目模块中将scala调整为source,并选择language level为java8

pom中引入spark的相关依赖
4.0.0
org.eights
spark-demo
1.0-SNAPSHOT
1.8
1.8
2.11
2.4.0
UTF-8
org.apache.spark
spark-core_${scala.version}
${spark.version}
org.apache.spark
spark-sql_2.11
${spark.version}
org.apache.spark
spark-hive_2.11
${spark.version}
net.alchim31.maven
scala-maven-plugin
3.2.2
org.apache.maven.plugins
maven-compiler-plugin
3.5.1
net.alchim31.maven
scala-maven-plugin
scala-compile-first
process-resources
add-source
compile
scala-test-compile
process-test-resources
testCompile
org.apache.maven.plugins
maven-compiler-plugin
compile
compile
org.apache.maven.plugins
maven-shade-plugin
2.4.3
package
shade
*:*
META-INF/*.SF
META-INF/*.DSA
META-INF/*.RSA
运行wordcount代码
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
object WorkCount {
/**
* spark word count
* @param args 传入参数
*/
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[*]")
.enableHiveSupport()
.getOrCreate()
val wordString = Array("hadoop", "hadoop", "spark","spark","spark","spark","flink","flink","flink","flink",
"flink","flink","hive","flink","hdfs","yarn","zookeeper","hbase","impala","sqoop","hadoop")
//生成Rdd
val wordRdd: RDD[String] = spark.sparkContext.parallelize(wordString)
//统计wordcount
val resRdd: RDD[(String, Int)] = wordRdd.map((_, 1)).reduceByKey(_ + _)
resRdd.foreach(elem => {
println(elem._1 + "-----" + elem._2)
})
spark.stop()
}
}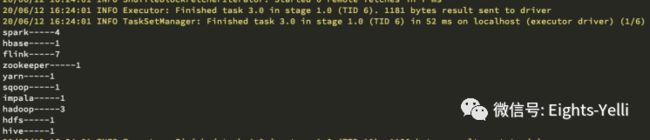
词频统计运行成功,Spark本地开发环境搭建完成
点个“在看”表示朕
已阅