Scrapy爬取知乎日报,并将文章保存为pdf
目标:
在D:/知乎日报下有两个文件夹,latest存放最新爬下来的文章,past存放之前爬下来的文章
在下一次爬的时候,如果文章已经爬过,就不再下载,如果没有就存放到latest中,并将之前已经存放在latest中的文章转移到past中
所用库,scrapy(必须的),pdfkit(用于html到pdf的转换),os和shutil(处理文件)
首先在http://daily.zhihu.com/得到每一篇文章的url和title,通过title判断这篇文章是否已经下载过。
将没下载过的文章的url传递给pdfkit.from_url,则自动在本地路径生成一个pdf。
代码:
在settings.py中声明两个变量filename和url
# -*- coding: utf-8 -*-
#
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ZhihudailyItem(scrapy.Item):
filename = scrapy.Field()
url = scrapy.Field()
pass
在爬虫文件中爬取daily.zhihu.com,返回文章的url和title给pipeline文件
# -*- coding: utf-8 -*-
import scrapy
from zhihudaily.items import ZhihudailyItem
class ZhihuSpider(scrapy.Spider):
name = 'zhihu'
allowed_domains = ['daily.zhihu.com']
start_urls = ['http://daily.zhihu.com/']
def parse(self, response):
for col in range(1,4):
for row in range(1,11):
item = ZhihudailyItem()
xpath_selector = "//div[@class='col-lg-4'][{0}]//div[@class='wrap'][{1}]".format(col, row)
sub_url = response.xpath(xpath_selector+"//@href").extract_first()
fix_url = "http://daily.zhihu.com"
item["url"] = fix_url+sub_url
title = response.xpath(xpath_selector+"//span/text()").extract_first()
item["filename"] = "D:/知乎日报/"+title+".pdf"
#print(item["filename"], item['url'])
yield item
#pdfkit.from_url(mix_url, filename)
在pipeline.py中将文章保存为pdf,并存放到对应的文件夹。并给出相应的提示。
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pdfkit
import os
import shutil
class ZhihudailyPipeline(object):
def process_item(self, item, spider):
try:
filename = os.path.basename(item["filename"])
dirname = os.path.dirname(item["filename"])
if not self.file_exsists(filename, dirname):
print('*'*20)
print(filename, "不存在")
pdfkit.from_url(item["url"], dirname+r'/latest/'+filename)
else:
print('*'*20)
print(filename, "已存在")
for _r, _d, files in os.walk("D:/知乎日报/latest/"):
if filename in files:
shutil.move("D:/知乎日报/latest/"+filename, "D:/知乎日报/past/")
print(filename, "文件移到past\n")
print('*'*20)
print('\n')
except:
# 此处一个Exit with code 1 due to network error: ContentNotFoundError异常
# 此异常为是因为css文件引用了外部的资源,如:字体,图片,iframe加载等。
# 选择忽略此异常
#
# 触发此异常,说明调用了pdfkit.from_url
print(item["filename"], "download successfully")
print('*'*20)
print('\n')
pass
return item
def file_exsists(self, filename, dirname):
for root, dirs, files in os.walk(dirname):
if filename in files:
return True
return False最后在settings.py中取消pipeline的注释,并设置USER_AGENT
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3269.3 Safari/537.36'保存文件,scrapy crawl zhihu 运行测试一下:

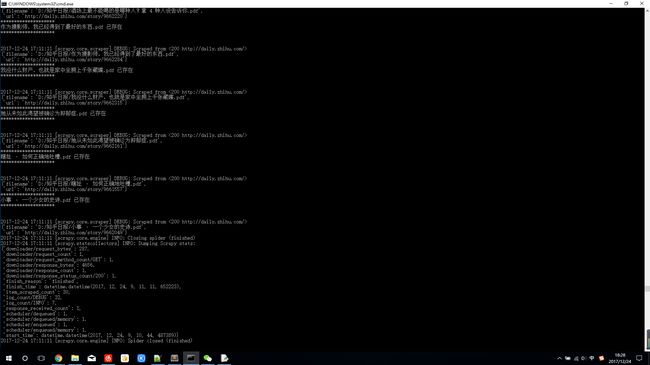
貌似还可以,看结果
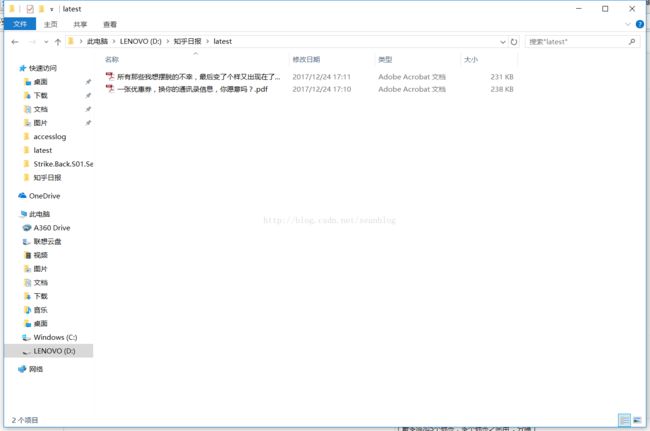
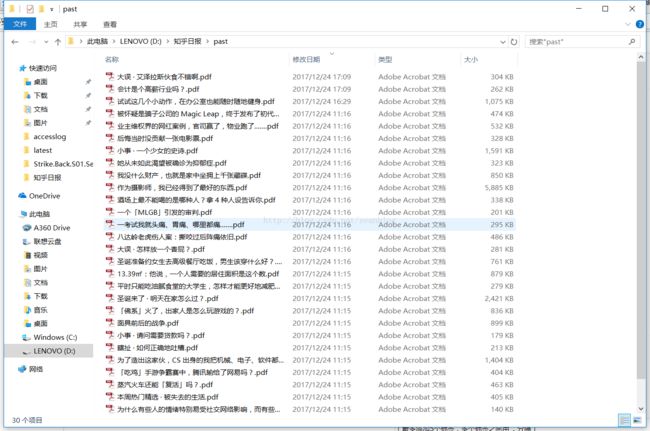

基本功能实现了,但是并不太实用,继续学习。