【python课程学习3-1】——集合、文件操作、字符编码转换
集合、文件操作
- 一、集合
- 1.1 集合的特性
- 1.2 集合的创建
- 1.3 集合的运算
- 二、文件操作
- 2.1 文件打开和关闭
- 2.2 open()方法
- 2.3 f.tell()和f.seek()
- 2.4 file对象其他方法
- 2.5 文件的修改
- 2.6 with open() as 读文件
- 三、字符编码转换
- 3.1 ASCII、gbk、utf-8的爱恨情仇
- 3.2 字符编码、文件编码
- 3.2 字符编码
一、集合
1.1 集合的特性
集合是一个无序的,不重复的数据组合,它的主要作用如下:
~去重,把一个列表变成集合,就自动去重了,天生自带去重光环。
~关系测试,测试两组数据之间的交集、并集、差集等关系
~集合是无序的存储结构,集合内的数据没有先后关系
~集合相当于是只有键没有值的字典(键就是集合中的数据)
~集合是一个可变容器,但集合内的元素是不可变的。
补充:列表、字典、集合判定元素是否在其中,都是 x in s格式。
1.2 集合的创建
1.使用直接量创建集合
注意:使用直接量不能创建空集合
s = {1,2,3}
s = {“hello”,3.14,True,(2019,02,17)}
请牢记,花括号只能用于初始化包含值的集合。如下所示,
使用不包含值的花括号是初始化字典(dict)的方法之一,
而不是初始化集合的方法。

2.使用构造函数创建集合 - set
s = set() #创建空集合
s = set(iterable) #使用可迭代对象创建一个集合
s = set(“ABC”) # s = {‘A’,‘B’,‘C’}
s = set([1,0,3.14,“hello”]) # s = {1,0,3.14,‘hello’}
… …
1.3 集合的运算
(1)交集,并集,差集,子集,父集,对称差集。
list1 = [1,2,3,4,5,6,7,8,9,10,4,5]
set1 = set(list1) #把列表类型变成集合类型,并去重。
print(set1)
set2 = {1,3,5,7,9}
print(set2)
print(set1.intersection(set2)) #交集: a & b
print(set1.union(set2)) #并集: a | b
print(set1.difference(set2)) #差集: a - b
print(set1.symmetric_difference(set2)) #对称差集 a ^ b
print(set2.issubset(set1)) # 子集,s2是否是s1的子集
print(set1.issuperset(set2)) # 父集
print(set1.isdisjoint(set2)) # 返回两个集合是否有交集
#集合的增
set.add(element) # 向集合添加元素。
set.copy() # 返回集合的副本。
#集合的删
set.discard(element) # 删除指定元素。
set.remove(element) # 删除指定元素。
set.pop() # 从集合中删除一个元素。
set.clear() # 清空集合中的所有元素。
#集合的改
set.update(s1) # 用此集合和其他集合的并集来更新集合。
#删除两个集合中都存在的项目
# difference_update() 方法与 difference() 方法不同,
# 因为 difference() 方法返回一个新集合,其中没有不需要的项目,
# 而 difference_update() 方法从原始集中删除了不需要的项目。
set.difference_update(s1)
#删除各集合中都不存在的项目
# intersection_update() 方法与 intersection() 方法不同,
# 因为 intersection() 方法返回一个新集合,其中没有不需要的项目,
# 而 intersection_update() 方法从原始集中删除了不需要的项目。
set.intersection_update(s1)
#删除两集合中都没有的项目,然后插入两集合中都没有的项目
#通过删除两个集合中都存在的项目并插入其他项目来更新原始集合
set.symmetric_difference_update(s1)
(2)集合的相等、不等、成员运算
集合的相等 == 返回:True False
集合的不等 != 返回:True False
成员运算 - in , not in
等同于字典 in , not in
目的:判断某个值在集合中存在 / 不存在
(3)用于集合的内建函数
len(set) : 集合内元素的个数
max(set) : 最大值
min(set) : 最小值
sum(set) : 和
any(set) : 任何一个元素为真,则返回真
all(set) : 所有元素为真,则返回真
二、文件操作
2.1 文件打开和关闭
(1)打开文件,得到文件句柄并赋值给一个变量
(2)通过句柄对文件进行操作
(3)关闭文件
f = open('song','r+',encoding='utf-8') #文件句柄,
#就是文件的内存对象包含文件名、字符集、大小、硬盘起止位置
data = f.read()
print(data)
f.close()
注意:使用 open() 方法一定要保证关闭文件对象,
即调用 close() 方法。
2.2 open()方法
一、语法:
open(file, mode=‘r’, buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
二、参数说明:
file: 必需,文件路径(相对或者绝对路径)。
mode: 可选,文件打开模式
buffering: 设置缓冲
encoding: 一般使用utf8
errors: 报错级别
newline: 区分换行符
closefd: 传入的file参数类型
opener:
三、mode 参数
(1)mode=‘r’ 对文件仅可读,文件的指针将会放在文件的开头。这是默认模式。readable()可判断文件是否可读。
(2)mode=‘r+’ (最常使用的),打开一个文件用于读写。文件指针将会放在文件的开头。
(3)mode=‘w’ 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。writeable()可判断文件是否可写。
(4)mode=‘w+’ 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
(5)mode=‘a’ (append),对文件追加,仅可写不可读,在原有的文件末尾开始写入内容。
(6)mode=‘a+’ 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。
(7)mode=‘rb’ 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。即网络传输的时候。b代表bytes字节
(8)mode=‘wb’ 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。。b代表bytes字节
2.3 f.tell()和f.seek()
文件定位操作
(1)f.tell()
tell()方法告诉你文件内的当前位置(当前光标的位置);
换句话说,下一次的读写会发生在文件开头这么多字节之后。
以字节进行计算的,开始数的。
(2)f.seek()
seek(offset [,from])方法改变当前文件的位置。Offset变量表示要移动的字节数。From变量指定开始移动字节的参考位置。如果from被设为0,这意味着将文件的开头作为移动字节的参考位置。如果设为1,则使用当前的位置作为参考位置。如果它被设为2,那么该文件的末尾将作为参考位置。
f = open('song','r+',encoding='utf-8')
print(f.readline())
f.tell()
f.seek(10)
print(f.readline())
print(f.tell())
2.4 file对象其他方法
f.close()
f.write(str)
f.read(size) #从文件读取指定的字节数,如果未给定或为负则读取所有。
f.readline(size) #size -- 从文件中读取的字节数。读取整行,包括 "\n" 字符。
f.readlines() #读取所有行并返回列表
f.flush() #刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。
f.truncate(size) #文件的首行首字符开始截断,截断文件为 size 个字符,
# 无 size 表示从当前位置截断;截断之后后面的所有字符被删除,
#其中 windows 系统下的换行代表2个字符大小。
f.encoding() #打印文件的编码
f.fileno() #返回文件的编号
f.closed #判断文件是否关闭
备注:调用read()会一次性读取文件的全部内容,如果文件很大,内存就爆了,所以可以反复调用read(size)方法,每次最多读取size个字节的内容。
~~调用readline()可以每次读取一行内容。
~~调用readlines()一次读取所有内容并按行返回list。
如果文件很小,read()一次性读取最方便;如果不能确定文件大小,反复调用read(size)比较保险;如果是配置文件,调用readlines()最方便
2.5 文件的修改
如果用“w”或者“w+”只会覆盖之前的内容,并且从头空白处写,所以不能在中间对内容进行修改(这是因为硬盘的存储方式决定的)
如果想要对文件修改,我们可以新建一个文件,把原来未修改的内容写进去,想要修改的部分进行替换,就达到了修改文件内容的目的(而且还没有在源文件上修改,更保险)
f = open('file1','r',encoding='utf-8') #打开源文件,也就是待修改文件
f_new = open('file2','w',encoding='utf-8')#打开新文件,准备修改
#循环源文件,找到符合想要修改的一行,进行字符串修改,并写入新文件中。
for line in f:
if "需修改的部分" in line:
line = line.replace("需修改的部分","想要修改的部分")
f_new = f_new.write(line)
注意:
#这个循环方式是效率最高的,在内存中读一行删除一行,最适合文件较大的情况。
for i in f:
print(i)
2.6 with open() as 读文件
为避免因忘记关闭文件导致报错问题,Python引入了with语句来自动帮我们调用close()方法,同时也解决了异常问题。
with open('test.txt','r',encoding='utf-8') as f :
print(f.readline())
其中,with open('test.txt') as **f** 中的 f 和 **f**=open('test.txt')是一样的,
都是文件句柄。前面的语句自动调用了close()方法。
写文件时,操作系统往往不会立刻把数据写入磁盘,而是放到内存缓存起来,空闲的时候再慢慢写入。只有调用close()方法时,操作系统才保证把没有写入的数据全部写入磁盘。忘记调用close()的后果是数据可能只写了一部分到磁盘,剩下的丢失了。所以,还是用with语句来得保险。
三、字符编码转换
3.1 ASCII、gbk、utf-8的爱恨情仇
(1)首先课程一中有详细介绍这些编码的发展过程
编码的发展过程
(2)# – coding:utf-8 – 的作用
在python2文件中,经常在文件开头看到“ #_coding:utf-8 _ ”语句,它的作用是告诉python解释器此.py文件是utf-8编码,需要用utf-8的编码去读取这个.py文件。
在python3中就不用加入这句话,默认是Unicode编码。
(3)对编码方式的手写历程介绍

3.2 字符编码、文件编码
python默认编码
python 2.x默认的字符编码是ASCII,默认的文件编码也是ASCII。
python 3.x默认的字符编码是unicode,默认的文件编码是utf-8。
备注:unicode:统一码、万国码、单一码。
python3相比python2特别明显的变化是字符集默认支持中文,按照utf-8处理的,python2按照ASCII处理的。
注意:字符编码和文件编码不一样,
界面上的修改是修改的文件编码,
程序中的字符编码不一样。如图
文件编码是什么样的,就声明什么样的文件编码类型,但是程序中的字符编码在Python3中依然是Unicode,不会随着文件编码类型而改变。
3.2 字符编码
(1)Python2中,因为默认的字符编码是ASCII,所以需要经过先解码成Unicode再编成想要的码。
注意理解:
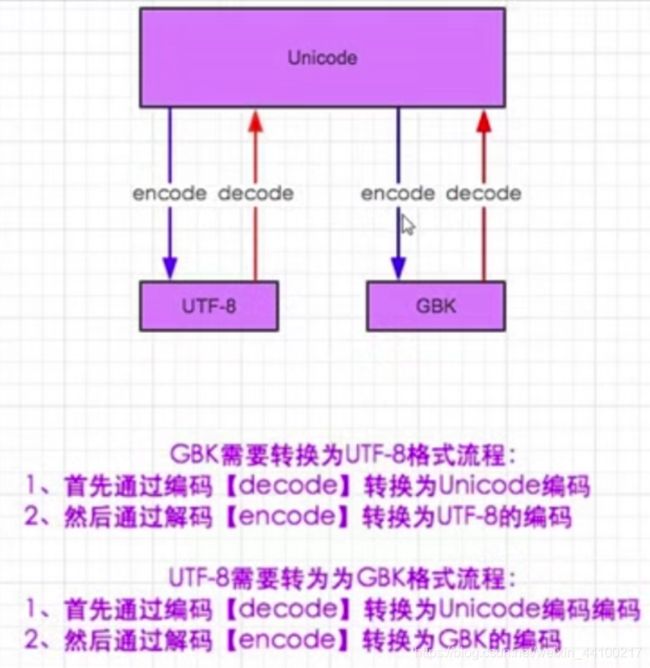
例如:gbk转成utf-8
parse = “今天继续加油~” #gbk编码
parse.decode(“gbk”).encode(“utf-8”)
注意:①.decode(“gbk”)是告诉Unicode你是什么编码形式,才能解码成Unicode,所有的解码都是要解码成Unicode形式。
②.encode(“utf-8”) 是告诉Unicode你想编码成哪种方式,例如utf-8。
③ utf-8是Unicode的扩展集,所以在文件编码是utf-8的情况下依然可以打印成中文,但是gbk不可以。
即:文件编码是 gbk 的情况下,Unicode不能正常显示,会乱码
文件编码是 utf-8 的情况下,Unicode编码可以正常显示,不会乱码
(2)python 3.x默认的字符编码是unicode,所以无需进行解码,只需要编码就可以了。
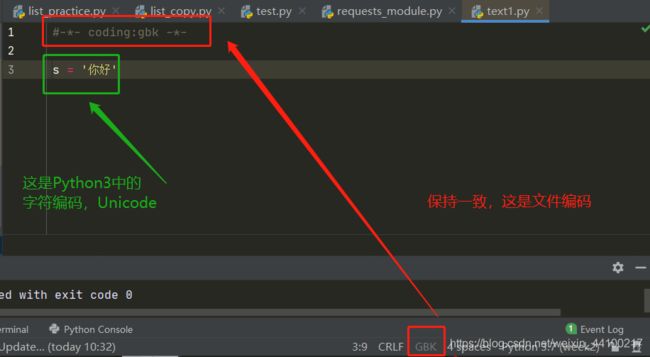
注意:
# -*- coding:gbk -*-
"""
上面这句是文件的编码,但是程序中数据类型依然是Unicode
"""
s = "你好" #依然是Unicode,所以没有decode方法
①Python3中编码后会变成bytes类型(就是打印出来的字符串前面有b),与Python2还是有区别的
(3)图解析