unix进程通信方式总结(上)
本文将《unix环境高级编程》一书中所涉及的几种重要的进程间通信方式(
Inter-Process Communication)进行简单总结,总的来说,进程间通信有以下几种:
(1)管道(pipe,未命名管道):适用于两个相关进程间的使用,而且这两个相关的进程还要有一个共同的创建了它们的祖先进程。首先我们先列管道的相关函数。创建一个管道:int pipe(int fd[2]);在历史上,管道是半双工的,数据只能在一个方向上流动。通常,一个管道由一个进程创建,在进程fork之后,这个管道就能在父进程和子进程间使用了。一般的描绘半双工管道的方法如下:

(1)管道(pipe,未命名管道):适用于两个相关进程间的使用,而且这两个相关的进程还要有一个共同的创建了它们的祖先进程。首先我们先列管道的相关函数。创建一个管道:int pipe(int fd[2]);在历史上,管道是半双工的,数据只能在一个方向上流动。通常,一个管道由一个进程创建,在进程fork之后,这个管道就能在父进程和子进程间使用了。一般的描绘半双工管道的方法如下:


一般说来,fd[0]为读而打开,fd[1]为写而打开,fd[1]的输出是fd[0]的写入.一旦创建了一个管道,我们就可以像读写文件描述符一样
让我们来看一个简单的代码:
#include "apue.h"
int main(void){
int n;
int fd[2];
pid_t pid;
char line[MAXLINE]
if (pipe(fd) < 0)
err_sys("pipe error");
if ((pid = fork()) < 0) {
err_sys("fork error");
} else if (pid > 0) { /* parent */
close(fd[0]);//父进程关闭读入端,则说明父进程使用写入端
write(fd[1], "hello world\n", 12);//父进程将信息写入管道
} else { /* child */
close(fd[1]);//子进程关闭写入端,使用读端
n = read(fd[0], line, MAXLINE);//从fd[0]将数据读入到缓冲line中
write(STDOUT_FILENO, line, n);//将line中的字符写入到标准输出
}
exit(0);
}
(2)命名管道(FIFO):
命名管道相关的函数为:

通过FIFO,不相关的进程也能进行通信,FIFO有以下两种用途:
1.shell命令使用FIFO将数据从一条管道复制到另一条管道时无需创建中间临时文件;考虑这样的一个过程,它需要对一个经过过滤的输入流进行两次处理。下图现显示了这种安排。
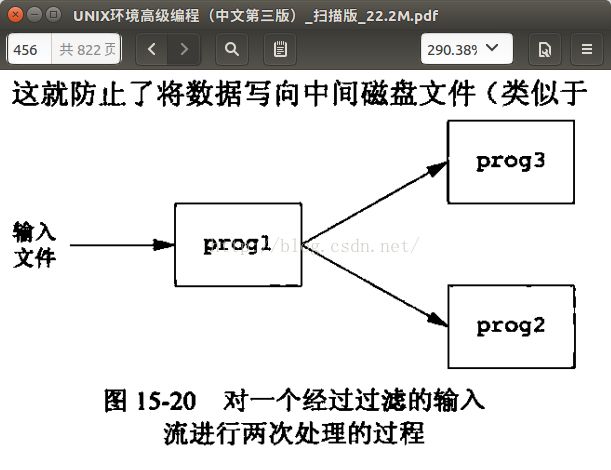
数据经prog1处理之后要作为prog3和prog2的输入,如果使用管道(pipe)的话,主程序要fork两次,况且一条管道只能维持一对进程的通信,因为管道是半双工,数据只能从一个方向流向另一个方向,主程序prog1不可能通过一个文件描述符向两个子进程传送数据(一个fd[1]只能向一个fd[0]传送数据),所以此时只能将prog1的输出保存到文件,然后再从文件到prog2,这样的话势必会产生磁盘中间文件。但是如果使用FIFO情况就会不一样,我们来看看书中的例子:
mkfifo fifo1
prog3 prog 用FIFO就可实现这样的过程而中间文件的产生,如图:

为了了解这个过程我们来看看上面的三条语句使怎样工作的:
tee命令:在执行Linux命令时,我们可以把输出重定向到文件中,比如 ls >a.txt,这时我们就不能看到输出了,如果我们既想把输出保存到文件中,又想在屏幕上看到输出内容,就可以使用tee命令了。tee命令读取标准输入,把这些内容同时输出到标准输出和(多个)文件中(read from standard input and write to standard output and files. Copy standard input to each FILE, and also to standard output. If a FILE is -, copy again to standard output.)。在info tee中说道:tee命令可以重定向标准输出到多个文件(`tee': Redirect output to multiple files. The `tee' command copies standard input to standard output and also to any files given as arguments. This is useful when you want not only to send some data down a pipe, but also to save a copy.)。要注意的是:在使用管道线时,前一个命令的标准错误输出不会被tee读取。简言之tee的作用是:输出到标准输出的同时,保存到文件file中。如果文件不存在,则创建;如果已经存在,则覆盖之。
新建一个命名管道:FIFO,然后后台运行prog3
数据经prog1处理之后要作为prog3和prog2的输入,如果使用管道(pipe)的话,主程序要fork两次,况且一条管道只能维持一对进程的通信,因为管道是半双工,数据只能从一个方向流向另一个方向,主程序prog1不可能通过一个文件描述符向两个子进程传送数据(一个fd[1]只能向一个fd[0]传送数据),所以此时只能将prog1的输出保存到文件,然后再从文件到prog2,这样的话势必会产生磁盘中间文件。但是如果使用FIFO情况就会不一样,我们来看看书中的例子:
mkfifo fifo1
prog3
为了了解这个过程我们来看看上面的三条语句使怎样工作的:
tee命令:在执行Linux命令时,我们可以把输出重定向到文件中,比如 ls >a.txt,这时我们就不能看到输出了,如果我们既想把输出保存到文件中,又想在屏幕上看到输出内容,就可以使用tee命令了。tee命令读取标准输入,把这些内容同时输出到标准输出和(多个)文件中(read from standard input and write to standard output and files. Copy standard input to each FILE, and also to standard output. If a FILE is -, copy again to standard output.)。在info tee中说道:tee命令可以重定向标准输出到多个文件(`tee': Redirect output to multiple files. The `tee' command copies standard input to standard output and also to any files given as arguments. This is useful when you want not only to send some data down a pipe, but also to save a copy.)。要注意的是:在使用管道线时,前一个命令的标准错误输出不会被tee读取。简言之tee的作用是:输出到标准输出的同时,保存到文件file中。如果文件不存在,则创建;如果已经存在,则覆盖之。
新建一个命名管道:FIFO,然后后台运行prog3
2.客户进程-服务器进程应用程序中,FIFO用作汇聚点,在客户进程和服务器进程二者之间进行数据传递。
首先用我自己写的小程序来验证FIFO命名管道的基本用法:
数据发送方:

数据接收方:

可以看到两个无关的进程通信成功!!!
让我们来看看通信结束之后的命名管道fifo3:

可以看到管道使用前后大小均为0!!!!
首先用我自己写的小程序来验证FIFO命名管道的基本用法:
/*fifo-write.c*/
#include
#include
#include
#include
#include
#include
int main(){
int fd;
int nRead;
char szBuff[100];
sleep(1);//wait for the creating of fifo3
fd=open("/home/caoyan/unix/c15/cyfifo/fifo3", O_WRONLY);
while(1){
if((nRead = read(STDIN_FILENO, szBuff, sizeof(szBuff))) == -1){
if (errno == EAGAIN)
printf("no data\n");
}
szBuff[nRead] = '\0';
write(fd,szBuff,nRead);
if (szBuff[0] == '#')break;//the last letter is 'Q' means that the data transport is over!
}
printf("data sending has finished!\n");
} /*fifo-read.c*/
#include
#include
#include
#include
#include
#include
using namespace std;
int main(int argc, char* argv[]){
int tmp,nRead,fd;
char szBuff[128];
const char *szPath="/home/caoyan/unix/c15/cyfifo/fifo3";
tmp=mkfifo(szPath,0777);
if (-1 == fd){
printf("create fifo error\n");
return 0;
}
fd=open("/home/caoyan/unix/c15/cyfifo/fifo3", O_RDONLY);
if(fd==-1)exit(1);
while(1){
if((nRead = read(fd, szBuff, sizeof(szBuff))) == -1){
if (errno == EAGAIN)
printf("no data\n");
}
if (szBuff[0] == '#')break;//the last letter is 'Q' means that the data transport is over!
szBuff[nRead] = '\0';
printf("%s", szBuff);
}
printf("data recieving has finished!\n");
return 0;
} 数据发送方:
数据接收方:
可以看到两个无关的进程通信成功!!!
让我们来看看通信结束之后的命名管道fifo3:
可以看到管道使用前后大小均为0!!!!
下面我们来看看用FIFO实现客户进程和服务器进程通信的设计方式:

图15-22表示多个客户进程向服务器进程请求数据,每个客户进程可以将其请求写入到一个总所周知的FIFO,如果所有客户进程与服务器进程共用一个FIFO的话(这里的FIFO是另外的一个命名管道,不同于上图中的众所周知的FIFO,用来从服务器进程写入,从客户进程读出数据),服务器进程就不知道如何将数据回送给客户进程,因为一旦有数据被写入到FIFO中,所有的客户进程都可以读里面的数据,这样就会出乱!!!一个好的解决方案如下:

为每个客户进程建立一个FIFO,这样每个客户进程就可以互不干扰地从服务器进程读取数据!!!!
(3)消息队列:
第一步:创建一个消息队列:int msgget(key_t key,int msgflg),其中key_t ftok( const char * fname, int id ),fname就时你指定的文件名(该文件必须是存在而且可以访问的),id是子序号,虽然为int,但是只有8个比特被使用(0-255)。当成功执行的时候,一个key_t值将会被返回,否则 -1 被返回。在一般的UNIX实现中,是将文件的索引节点号取出,前面加上子序号得到key_t的返回值。如指定文件的索引节点号为65538,换算成16进制为 0x010002,而你指定的ID值为38,换算成16进制为0x26,则最后的key_t返回值为0x26010002。也是说消息队列号由文件的索引节点号和用户指定ID组成;
第二步:发送消息 :int msgsnd ( int msqid, struct msgbuf *msgp, int msgsz, int msgflg ); 其中的msgbuf的数据结构可表示为:
第二步:发送消息 :int msgsnd ( int msqid, struct msgbuf *msgp, int msgsz, int msgflg ); 其中的msgbuf的数据结构可表示为:
(1)消息缓冲区(msgbuf)
我们在这里要介绍的第一个数据结构是msgbuf结构,可以把这个特殊的数据结构看成一个存放消息数据的模板,它在include/linux/msg.h中声明,描述如下:
/* msgsnd 和msgrcv 系统调用使用的消息缓冲区*/
但是,消息的长度还是有限制的,在Linux中,给定消息的最大长度在include/linux/msg.h中定义如下:
#define MSGMAX 8192 /* max size of message (bytes) */
消息总的长度不能超过8192字节,包括mtype域,它是4字节长。
(2)消息结构(msg)
内核把每一条消息存储在以msg结构为框架的队列中,它在include/ linux/msg.h中定义如下:
(3)消息队列结构(msgid_ds)
当在系统中创建每一个消息队列时,内核创建、存储及维护这个结构的一个实例。
我们在这里要介绍的第一个数据结构是msgbuf结构,可以把这个特殊的数据结构看成一个存放消息数据的模板,它在include/linux/msg.h中声明,描述如下:
/* msgsnd 和msgrcv 系统调用使用的消息缓冲区*/
struct msgbuf {
long mtype; /* 消息的类型,必须为正数 */
char mtext[1]; /* 消息正文 */
};struct my_msgbuf {
long mtype; /* 消息类型 */
long request_id; /* 请求识别号 */
struct client info; /* 客户消息结构 */
};但是,消息的长度还是有限制的,在Linux中,给定消息的最大长度在include/linux/msg.h中定义如下:
#define MSGMAX 8192 /* max size of message (bytes) */
消息总的长度不能超过8192字节,包括mtype域,它是4字节长。
(2)消息结构(msg)
内核把每一条消息存储在以msg结构为框架的队列中,它在include/ linux/msg.h中定义如下:
struct msg {
struct msg *msg_next; /* 队列上的下一条消息 */
long msg_type; /*消息类型*/
char *msg_spot; /* 消息正文的地址 */
short msg_ts; /* 消息正文的大小 */
};(3)消息队列结构(msgid_ds)
当在系统中创建每一个消息队列时,内核创建、存储及维护这个结构的一个实例。
/* 在系统中的每一个消息队列对应一个msqid_ds 结构 */
struct msqid_ds {
struct ipc_perm msg_perm;
struct msg *msg_first; /* 队列上第一条消息,即链表头*/
struct msg *msg_last; /* 队列中的最后一条消息,即链表尾 */
time_t msg_stime; /* 发送给队列的最后一条消息的时间 */
time_t msg_rtime; /* 从消息队列接收到的最后一条消息的时间 */
time_t msg_ctime; /* 最后修改队列的时间*/
ushort msg_cbytes; /*队列上所有消息总的字节数 */
ushort msg_qnum; /*在当前队列上消息的个数 */
ushort msg_qbytes; /* 队列最大的字节数 */
ushort msg_lspid; /* 发送最后一条消息的进程的pid */
ushort msg_lrpid; /* 接收最后一条消息的进程的pid */
};
第四步:接受消息:
int msgrcv ( int msqid, struct msgbuf *msgp, int msgsz, long mtype, int msgflg );
返回值:成功,则为拷贝到消息缓冲区的字节数,失败为-1。
很明显,第一个参数用来指定要检索的队列(必须由msgget()调用返回),第二个参数(msgp)是存放检索到消息的缓冲区的地址,第三个参数(msgsz)是消息缓冲区的大小,不包括消息类型mtype的长度。第四个参数(mtype)指定了消息的类型。内核将搜索队列中相匹配类型的最早的消息,并且返回这个消息的一个拷贝,返回的消息放在由msgp参数指向的地址。这里存在一个特殊的情况,如果传递给mytype参数的值为0,就可以不管类型,只返回队列中最早的消息。如果传递给参数msgflg的值为IPC_NOWAIT,并且没有可取的消息,那么给调用进程返回ENOMSG错误消息,否则,调用进程阻塞,直到一条消息到达队列并且满足msgrcv()的参数。如果一个客户正在等待消息,而队列被删除,则返回EIDRM。如果当进程正在阻塞,并且等待一条消息到达但捕获到了一个信号,则返回EINTR。
很明显,第一个参数用来指定要检索的队列(必须由msgget()调用返回),第二个参数(msgp)是存放检索到消息的缓冲区的地址,第三个参数(msgsz)是消息缓冲区的大小,不包括消息类型mtype的长度。第四个参数(mtype)指定了消息的类型。内核将搜索队列中相匹配类型的最早的消息,并且返回这个消息的一个拷贝,返回的消息放在由msgp参数指向的地址。这里存在一个特殊的情况,如果传递给mytype参数的值为0,就可以不管类型,只返回队列中最早的消息。如果传递给参数msgflg的值为IPC_NOWAIT,并且没有可取的消息,那么给调用进程返回ENOMSG错误消息,否则,调用进程阻塞,直到一条消息到达队列并且满足msgrcv()的参数。如果一个客户正在等待消息,而队列被删除,则返回EIDRM。如果当进程正在阻塞,并且等待一条消息到达但捕获到了一个信号,则返回EINTR。
(4)信号量:
当我们在多用户系统,多进程系统,或是两者混合的系统中使用线程操作编写程序时,我们经常会发现我们有段临界代码,在此处我们需要保证一个进程(或是一个线程的执行)需要排他的访问一个资源。信号量有一个复杂的编程接口。幸运的是,我们可以很容易的为自己提供一个对于大多数的信号量编程问题足够高效的简化接口。为了阻止多个程序同时访问一个共享资源所引起的问题,我们需要一种方法生成并且使用一个标记从而保证在临界区部分一次只有一个线程执行。线程相关的方法,我们可以使用互斥或信号量来控制一个多线程程序对于临界区的访问。信号量与已经介绍过的IPC机构(管道,FIFO以及消息队列不同),它是一个计数器,用于多个为多个进程提供对共享数据的访问。当我们要使用XSI信号量时,首先需要通过调用函数semget来获得一个信号量的ID,函数原型如下
int semget(key_t key,int nsems,int flag);
其中,nsems是该集合中的信号量数,如果是创建新集合(一般是在服务器进程中),则必须指定nsems,如果是应用现有集合(一个客户进程),则将nsems指定为0。
信号量相关的三个重要函数:
1. semget函数原型
| semget(得到一个信号量集标识符或创建一个信号量集对象) | ||
| 所需头文件 | #include |
|
| #include |
||
| #include |
||
| 函数说明 | 得到一个信号量集标识符或创建一个信号量集对象并返回信号量集标识符 | |
| 函数原型 | int semget(key_t key, int nsems, int semflg) | |
| 函数传入值 | key | 0(IPC_PRIVATE):会建立新信号量集对象 |
| 大于0的32位整数:视参数semflg来确定操作,通常要求此值来源于ftok返回的IPC键值 | ||
| nsems | 创建信号量集中信号量的个数,该参数只在创建信号量集时有效 | |
| msgflg | 0:取信号量集标识符,若不存在则函数会报错 | |
| IPC_CREAT:当semflg&IPC_CREAT为真时,如果内核中不存在键值与key相等的信号量集,则新建一个信号量集;如果存在这样的信号量集,返回此信号量集的标识符 | ||
| IPC_CREAT|IPC_EXCL:如果内核中不存在键值与key相等的信号量集,则新建一个消息队列;如果存在这样的信号量集则报错 | ||
| 函数返回值 | 成功:返回信号量集的标识符 | |
| 出错:-1,错误原因存于error中 | ||
| 附加说明 | 上述semflg参数为模式标志参数,使用时需要与IPC对象存取权限(如0600)进行|运算来确定信号量集的存取权限 | |
| 错误代码 | EACCESS:没有权限 | |
| EEXIST:信号量集已经存在,无法创建 | ||
| EIDRM:信号量集已经删除 | ||
| ENOENT:信号量集不存在,同时semflg没有设置IPC_CREAT标志 | ||
| ENOMEM:没有足够的内存创建新的信号量集 | ||
| ENOSPC:超出限制 | ||
2. semop函数原型
| semop(完成对信号量的P操作或V操作) | |
| 所需头文件 | #include |
| #include |
|
| #include |
|
| 函数说明 | 对信号量集标识符为semid中的一个或多个信号量进行P操作或V操作 |
| 函数原型 | int semop(int semid, struct sembuf *sops, unsigned nsops) |
| 函数传入值 | semid:信号量集标识符 |
| sops:指向进行操作的信号量集结构体数组的首地址,此结构的具体说明如下: | |
| struct sembuf { | |
| short semnum; /*信号量集合中的信号量编号,0代表第1个信号量*/ | |
| short val;/*若val>0进行V操作信号量值加val,表示进程释放控制的资源 */ | |
| /*若val<0进行P操作信号量值减val,若(semval-val)<0(semval为该信号量值),则调用进程阻塞,直到资源可用;若设置IPC_NOWAIT不会睡眠,进程直接返回EAGAIN错误*/ | |
| /*若val==0时阻塞等待信号量为0,调用进程进入睡眠状态,直到信号值为0;若设置IPC_NOWAIT,进程不会睡眠,直接返回EAGAIN错误*/ | |
| short flag; /*0 设置信号量的默认操作*/ | |
| /*IPC_NOWAIT设置信号量操作不等待*/ | |
| /*SEM_UNDO 选项会让内核记录一个与调用进程相关的UNDO记录,如果该进程崩溃,则根据这个进程的UNDO记录自动恢复相应信号量的计数值*/ | |
| }; | |
| nsops:进行操作信号量的个数,即sops结构变量的个数,需大于或等于1。最常见设置此值等于1,只完成对一个信号量的操作 | |
| 函数返回值 | 成功:返回信号量集的标识符 |
| 出错:-1,错误原因存于error中 | |
| 错误代码 | E2BIG:一次对信号量个数的操作超过了系统限制 |
| EACCESS:权限不够 | |
| EAGAIN:使用了IPC_NOWAIT,但操作不能继续进行 | |
| EFAULT:sops指向的地址无效 | |
| EIDRM:信号量集已经删除 | |
| EINTR:当睡眠时接收到其他信号 | |
| EINVAL:信号量集不存在,或者semid无效 | |
| ENOMEM:使用了SEM_UNDO,但无足够的内存创建所需的数据结构 | |
| ERANGE:信号量值超出范围 | |
3. semctl函数原型
| semctl (得到一个信号量集标识符或创建一个信号量集对象) | ||
| 所需头文件 | #include |
|
| #include |
||
| #include |
||
| 函数说明 | 得到一个信号量集标识符或创建一个信号量集对象并返回信号量集标识符 | |
| 函数原型 | int semctl(int semid, int semnum, int cmd, union semun arg) | |
| 函数传入值 | semid | 信号量集标识符 |
| semnum | 信号量集数组上的下标,表示某一个信号量 | |
| cmd | 见下文表15-4 | |
| arg | union semun { | |
| short val; /*SETVAL用的值*/ | ||
| struct semid_ds* buf; /*IPC_STAT、IPC_SET用的semid_ds结构*/ | ||
| unsigned short* array; /*SETALL、GETALL用的数组值*/ | ||
| struct seminfo *buf; /*为控制IPC_INFO提供的缓存*/ | ||
| } arg; | ||
| 函数返回值 | 成功:大于或等于0,具体说明请参照表15-4 | |
| 出错:-1,错误原因存于error中 | ||
| 附加说明 | semid_ds结构见上文信号量集内核结构定义 | |
| 错误代码 | EACCESS:权限不够 | |
| EFAULT:arg指向的地址无效 | ||
| EIDRM:信号量集已经删除 | ||
| EINVAL:信号量集不存在,或者semid无效 | ||
| EPERM:进程有效用户没有cmd的权限 | ||
| ERANGE:信号量值超出范围 | ||
表15-4 semctl函数cmd形参说明表
| 命令 | 解 释 |
| IPC_STAT | 从信号量集上检索semid_ds结构,并存到semun联合体参数的成员buf的地址中 |
| IPC_SET | 设置一个信号量集合的semid_ds结构中ipc_perm域的值,并从semun的buf中取出值 |
| IPC_RMID | 从内核中删除信号量集合 |
| GETALL | 从信号量集合中获得所有信号量的值,并把其整数值存到semun联合体成员的一个指针数组中 |
| GETNCNT | 返回当前等待资源的进程个数 |
| GETPID | 返回最后一个执行系统调用semop()进程的PID |
| GETVAL | 返回信号量集合内单个信号量的值 |
| GETZCNT | 返回当前等待100%资源利用的进程个数 |
| SETALL | 与GETALL正好相反 |
| SETVAL | 用联合体中val成员的值设置信号量集合中单个信号量的值 |
对于系统中的每个信号量集,内核维护一个如下的信息结构:
struct semid_ds {
struct ipc_permsem_perm ;
structsem* sem_base ; //信号数组指针
ushort sem_nsem ; //此集中信号个数
time_t sem_otime ; //最后一次semop时间
time_t sem_ctime ; //最后一次创建时间
} ;
某个给定信号量的结构体
struct sem {
ushort_t semval ; //信号量的值
short sempid ; //最后一个调用semop的进程ID
ushort semncnt ; //等待该信号量值大于当前值的进程数(一有进程释放资源 就被唤醒)
ushort semzcnt ; //等待该信号量值等于0的进程数
} ;
struct sembuf {
unsigned short sem_num ; //信号量在信号量集中的index(对哪个信号量操作),如果只有一个信号量,则对应的值为0
short sem_op ; //操作的类型(P操作 还是 V操作)
short sem_flg ; //是否等待(当信号量的值不够消耗时 是否等待其他进进程释放资源)
} ;
union semun {
short val; /*SETVAL用的值*/
struct semid_ds* buf; /*IPC_STAT、IPC_SET用的semid_ds结构*/
unsigned short* array; /*SETALL、GETALL用的数组值*/
struct seminfo *buf; /*为控制IPC_INFO提供的缓存*/
}arg;
对于sembuf结构体中的sem_op值:
⑴若sem_op为正,这对应于进程释放占用的资源数。sem_op值加到信号量的值上。(V操作)
⑵若sem_op为负,这表示要获取该信号量控制的资源数。信号量值减去sem_op的绝对值。(P操作)
⑶若sem_op为0,这表示调用进程希望等待到该信号量值变成0
如果此时执行的是p操作且信号量值小于sem_op的绝对值(资源不能满足要求),则:
⑴若指定了IPC_NOWAIT,则semop()出错返回EAGAIN。
⑵若未指定IPC_NOWAIT,则信号量的semncnt值加1(因为调用进程将进入休眠状态),然后调用进程被挂起直至:①此信号量变成大于或等于sem_op的绝对值;②从系统中删除了此信号量,返回EIDRM;③进程捕捉到一个信号,并从信号处理程序返回,返回EINTR。(与消息队列的阻塞处理方式 很相似)
⑴若sem_op为正,这对应于进程释放占用的资源数。sem_op值加到信号量的值上。(V操作)
⑵若sem_op为负,这表示要获取该信号量控制的资源数。信号量值减去sem_op的绝对值。(P操作)
⑶若sem_op为0,这表示调用进程希望等待到该信号量值变成0
如果此时执行的是p操作且信号量值小于sem_op的绝对值(资源不能满足要求),则:
⑴若指定了IPC_NOWAIT,则semop()出错返回EAGAIN。
⑵若未指定IPC_NOWAIT,则信号量的semncnt值加1(因为调用进程将进入休眠状态),然后调用进程被挂起直至:①此信号量变成大于或等于sem_op的绝对值;②从系统中删除了此信号量,返回EIDRM;③进程捕捉到一个信号,并从信号处理程序返回,返回EINTR。(与消息队列的阻塞处理方式 很相似)
下面我们通过引用http://blog.csdn.net/liang890319/article/details/8280860所提及的例子来简单讲解上面的参数的运用:
/*sem_com.h*/
#ifndef SEM_COM_H
#define SEM_COM_H
#include
#include
union semun {
int val;
struct semid_ds *buf;
unsigned short *array;
struct seminfo *buf;
};
int init_sem(int, int);
int del_sem(int);
int sem_p(int);
int sem_v(int);
#endif /* SEM_COM_H */
/* sem_com.c */
#include "sem_com.h"
int init_sem(int sem_id, int init_value) {
union semun sem_union; //可以知道对信号量ID的操作都需要用到semun联合体
//我们想对信号量ID采取什么样的操作就将对应的值设置,然后再设置标志(SETVAL)
//不同的标志(也就是cmd参数)对应着设置semum联合体里的不同字段的值
sem_union.val = init_value;
if (semctl(sem_id, 0, SETVAL, sem_union) == -1){//设置单个信号量的值
perror("Initialize semaphore");
return -1;
}
return 0;
}
int del_sem(int sem_id){//从内核中删除该信号量
union semun sem_union;
if (semctl(sem_id, 0, IPC_RMID, sem_union) == -1){//在semctl中,参数包括对直接操作的信号,但是在semop中,
perror("Delete semaphore"); //被操作的信号量的下标由sembuf中的相关字段标明
return -1;
}
}
int sem_p(int sem_id) { //对信号量的操作,操作的信息以sembuf结构体进行传递
struct sembuf sem_b;
sem_b.sem_num = 0; /*id,因为集合中只有一个信号量,所以下标为0*/
sem_b.sem_op = -1; /* P operation,对信号量减1*/
sem_b.sem_flg = SEM_UNDO; //这会使得操作系统跟踪当前进程对信号量所做的改变,而且如果进程终止而没
//有释放这个信号量, 如果信号量为这个进程所占有,这个标记可以使得操作系统自动释放这个信号量。
if (semop(sem_id, &sem_b, 1) == -1){//对信号量进行减1操作
perror("P operation");
return -1;
}
return 0;
}
int sem_v(int sem_id) { //和sem_p操作相对,对信号量所代表的资源进行释放
struct sembuf sem_b;
sem_b.sem_num = 0; /* id */
sem_b.sem_op = 1; /* V operation */
sem_b.sem_flg = SEM_UNDO;
if (semop(sem_id, &sem_b, 1) == -1) {
perror("V operation");
return -1;
}
return 0;
}
/* fork.c */
#include
#include
#include
#include
#include
#include
#include
#define DELAY_TIME 3
int main(void) {
pid_t result;
int sem_id;
sem_id = semget(ftok(".", 'a'), 1, 0666|IPC_CREAT); /* 创建一个信号量集,这个信号量集中只有一个信号量*/
init_sem(sem_id, 0); //初始值设为0资源被占用
result = fork(); /*调用fork函数,其返回值为result*/
/*通过result的值来判断fork函数的返回情况,首先进行出错处理*/
if(result == -1)perror("Fork\n");
else if (result == 0) {/*返回值为0代表子进程*/
printf("Child process will wait for some seconds...\n");
sleep(DELAY_TIME);
printf("The returned value is %d in the child process(PID = %d)\n", result, getpid());
sem_v(sem_id); //释放资源
}
else {/*返回值大于0代表父进程*/
sem_p(sem_id); //等待资源,如果子进程不释放 就一直等
printf("The returned value is %d in the father process(PID = %d)\n", result, getpid());
sem_v(sem_id); //释放资源
del_sem(sem_id); //删除信号量
}
exit(0);
}