Mysql+MysqlProxy实现 基于主从复制mysql读写分离
一.读写分离的作用
1.什么是读写分离?
MySQL的主从复制和MySQL的读写分离两者有着紧密联系,首先部署主从复制,只有主从复制完了,才能在此基础上进行数据的读写分离。
读写分离,基本的原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理SELECT查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
简单来说,读写分离的基本原理就是,在主服务器上修改,数据会同步到从服务器,从服务器只能提供读取数据,不能写入,实现备份的同时也实现了数据库性能的优化,以及提升了服务器安全。
2.为什么要进行读写分离?
因为数据库的“写”(写10000条数据到oracle可能要3分钟)操作是比较耗时的。
但是数据库的“读”(从oracle读10000条数据可能只要5秒钟)。
所以读写分离,解决的是,数据库的写入,影响了查询的效率。
3.什么时候要读写分离?
数据库不一定要读写分离,如果程序使用数据库较多时,而更新少,查询多的情况下会考虑使用,利用数据库 主从同步 。可以减少数据库压力,提高性能。当然,数据库也有其它优化方案。memcache 或是 表折分,或是搜索引擎。都是解决方法。
4.主从复制与读写分离
在实际的生产环境中,对数据库的读和写都在同一个数据库服务器中,是不能满足实际需求的。无论在安全性,高可用性还是高并发等各个方面是不能满足需求的。因此通过主从复制的方式来同步数据,再通过读写分离来提升数据库的并发负载能力。优点类似于我们前面学过的rsync,但是不同的是rsync是对磁盘文件做备份,而mysql主从复制是对数据库中的数据,语句做备份。
5.前较为常见的Mysql读写分离分为以下两种:
1)基于程序代码内部实现
在代码中根据select,insert,进行路由分类,这种方法也是目前生产环境下应用最广泛的。优点是性能较好,因为程序在代码中实现,不需要增加额外的硬件开支,缺点是需要开发人员来实现,运维人员无从下手。
2) 基于中间代理层实现
代理一般介于应用服务器和数据库服务器之间,代理数据库服务器接受到应用服务器的请求后根据判断后转发到,后端数据库,有以下代表性的程序。
(1)mysql_proxy。mysql_proxy是Mysql的一个开源项目,通过其自带的lua脚本进行sql判断。
(2)Atlas。是由 Qihoo 360, Web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目。它是在mysql-proxy 0.8.2版本的基础上,对其进行了优化,增加了一些新的功能特性。360内部使用Atlas运行的mysql业务,每天承载的读写请求数达几十亿条。支持事物以及存储过程。
(3)Amoeba。由阿里巴巴集团在职员工陈思儒使用序java语言进行开发,阿里巴巴集团将其用户生产环境下,但是他并不支持事物以及存储过程。
经过上述简单的比较,不是所有的应用都能够在基于程序代码中实现读写分离,像一些大型的java应用,如果在程序代码中实现读写分离对代码的改动就较大,所以,像这种应用一般会考虑使用代理层来实现,那么今天就使用mysql_proxy为例,完成主从复制和读写分离。
二、MySQLProxy介绍
下面使用MySQL官方提供的数据库代理层产品MySQLProxy搭建读写分离。
MySQLProxy实际上是在客户端请求与MySQLServer之间建立了一个连接池。所有客户端请求都是发向MySQLProxy,然后经由MySQLProxy进行相应的分析,判断出是读操作还是写操作,分发至对应的MySQLServer上。对于多节点Slave集群,也可以起做到负载均衡的效果。

实验准备
1.selinux和firewalld状态为disabled
2.各主机信息如下:
| 主机 | ip |
|---|---|
| server1(主库) | 192.168.1.248 |
| server1(从库) | 192.168.1.249 |
| server3(代理服务器) | 192.168.1.247 |
三.主从复制存在的问题以及解决办法
问题:
主库宕机之后,数据可能会丢失
从库只有一个sql Thread,主库写压力大,复制很可能延时
解决方法:
半同步复制--解决数据丢失的问题
并行复制--解决从库复制延时的问题
2.数据库同步是怎样进行的?
master用户写入数据,生成event记到binary log中.
slave接收master上传来的binlog,然后按顺序应用,重现master上的用户操作。
3.数据库是靠什么同步的?
主从复制,默认是通过pos复制(postion),就是说在日志文档里,将用户进行的每一项操作都进行编号(pos),每一个event都有一个起始编号,一个终止编号,我们在配置主从复制时从节点时,要输入master的log_pos值就是这个原因,要求它从哪个pos开始同步数据库里的数据,这也是传统复制技术, MySQL5.6增加了GTID复制,GTID就是类似于pos的一个作用,不过它是整个mysql复制架构全局通用的,就是说在这整个mysql冗余架构中,它们的日志文件里事件的GTID值是一致的.
4.从节点怎么知道要从哪块进行同步?
上面也说了,一开始是自己设置的从节点从主节点的日志文件里的pos开始复制,以后就自己去读取上一次同步到哪一块,接着同步.
5:pos与GTID有什么区别?
两者都是日志文件里事件的一个标志,如果将整个mysql集群看作一个整体,pos就是局部的,GTID就是全局的。
1、GTID的概念
1.全局事务标识:global transaction identifiers。
2.GTID是一个事务一一对应,并且全局唯一ID。
3.一个GTID在一个服务器上只执行一次,避免重复执行导致数据混乱或者主从不一致。
4.GTID用来代替传统复制方法,不再使用MASTER_LOG_FILE+MASTER_LOG_POS开启。
5.而是使用MASTER_AUTO_POSTION=1的方式开始复制。
6.MySQL-5.6.5开始支持的,MySQL-5.6.10后开始完善。
2、GTID的组成
GTID = source_id:transaction_id
- source_id,用于鉴别原服务器,即mysql服务器唯一的的server_uuid,由于GTID会传递到slave,所以也可以理解为源ID。
- transaction_id,为当前服务器上已提交事务的一个序列号,通常从1开始自增长的序列,一个数值对应一个事务。
#示例:
3E11FA47-71CA-11E1-9E33-C80AA9429562:23
前面的一串为服务器的server_uuid,即3E11FA47-71CA-11E1-9E33-C80AA9429562,后面的23为transaction_id
3、GTID的优势
1.更简单的实现failover,不用以前那样在需要找log_file和log_pos。
2.更简单的搭建主从复制。
3.比传统的复制更加安全。
4.GTID是连续的没有空洞的,保证数据的一致性,零丢失
5.借助GTID,在发生主备切换的情况下,MySQL的其它Slave可以自动在新主上找到正确的复制位置,这大大简化了复杂复制拓扑下集群的维护,也减少了人为设置复制位置发生误操作的风险。另外,基于GTID的复制可以忽略已经执行过的事务,减少了数据发生不一致的风险。
4、GTID的工作原理
1.当一个事务在主库端执行并提交时,产生GTID,一同记录到binlog日志中。
2.binlog传输到slave,并存储到slave的relaylog后,读取这个GTID的这个值设置gtid_next变量,即告诉Slave,下一个要执行的GTID值。
3.sql线程从relay log中获取GTID,然后对比slave端的binlog是否有该GTID。
4.如果有记录,说明该GTID的事务已经执行,slave会忽略。
5.如果没有记录,slave就会执行该GTID事务,并记录该GTID到自身的binlog,在读取执行事务前会先检查其他session持有该GTID,确保不被重复执行。在解析过程中会判断是否有主键,如果有就用二级索引,如果没有就用全部扫描。
5、配置基于GTID的 Mysql 主从数据库的复制
配置server1(主库)
1.修改配置文件(/etc/my.cnf)并重启mysql
[root@server1 mysql]# vim /etc/my.cnf
在最后写入:
log-bin=mysql-bin #启动mysql二进制日志,即数据同步语句,从数据库会一条一条的执行这些语句
server-id=1 #服务器唯一标识
gtid_mode=ON #开启gtid模式
enforce-gtid-consistency=true #强制gtid一致性,开启后对于特定create table不被支持
修改完配置文件之后,重启mysqld服务
[root@server1 mysql]# systemctl restart mysqld
2.查看主库状态
[root@server1 mysql]# mysql -uroot -pWestos+001
mysql> show master status;

配置server2(从库)
1.修改配置文件(/etc/my.cnf)并重启mysql
[root@server2 mysql]# vim /etc/my.cnf
在最后写入:
gtid_mode=ON #开启gtid模块
enforce-gtid-consistency=true #强制gtid一致性,开启后对于特定create table不被支持
server-id=2 #服务器唯一标识
修改完配置文件之后,重启mysqld服务
[root@server2 mysql]# systemctl restart mysqld
2.设定从库,将主库与从库连接起来,并开启从库
登录server2(从库)自己的数据库进行设置
[root@server2 mysql]# mysql -uroot -pWestos+001
mysql> stop slave; #先关闭slave(在change之前要关闭slave)
Query OK, 0 rows affected (0.03 sec)
mysql> change master to
-> master_host='172.25.63.1',
-> master_user='repl',
-> master_password='Westos+001',
-> master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (0.17 sec)
mysql> start slave;
Query OK, 0 rows affected (0.06 sec)
查看从库状态:
如果Slave_IO_Running和Slave_SQL_Running都为yes,则表示正常

下图记录了gtid的变化

测试:
1.在主库端的数据库westos下的表usertb中,插入信息
mysql> insert into usertb values ('user2','456');
Query OK, 1 row affected (0.04 sec)
mysql> insert into usertb values ('user3','789');
Query OK, 1 row affected (0.08 sec)
在主库上查看gtid号的改变
mysql> show master status;

2.从库端查看是否存在在主库中添加的内容

此时可以在从库上查看gtid号码的改变。

四、MySQL 主从复制模式
异步模式(mysql async-mode)
MySQL默认的复制即是异步的,主库在执行完客户端提交的事务后会立即将结果返给给客户端,并不关心从库是否已经接收并处理,这样就会有一个问题,主如果crash掉了,此时主上已经提交的事务可能并没有传到从库上,如果此时,强行将从提升为主,可能导致新主上的数据不完整。
异步模式如下图所示,这种模式下,主节点不会主动push bin log到从节点,这样有可能导致failover的情况下,也许从节点没有即时地将最新的bin log同步到本地。
半同步模式(mysql semi-sync)
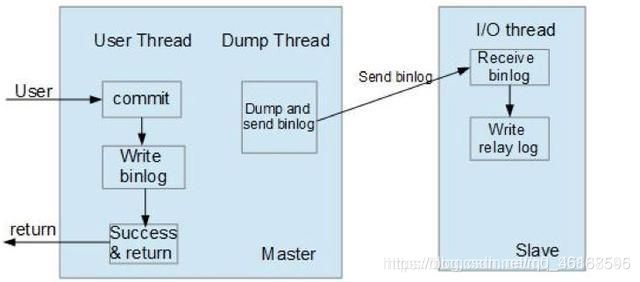
介于异步复制和全同步复制之间,主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收到并写到relay log中才返回给客户端。相对于异步复制,半同步复制提高了数据的安全性,同时它也造成了一定程度的延迟,这个延迟最少是一个TCP/IP往返的时间。所以,半同步复制最好在低延时的网络中使用。
这种模式下主节点只需要接收到其中一台从节点的返回信息,就会commit;否则需要等待直到超时时间然后切换成异步模式再提交;这样做的目的可以使主从数据库的数据延迟缩小,可以提高数据安全性,确保了事务提交后,binlog至少传输到了一个从节点上,不能保证从节点将此事务更新到db中。性能上会有一定的降低,响应时间会变长。如下图所示:

全同步模式
指当主库执行完一个事务,所有的从库都执行了该事务才返回给客户端。因为需要等待所有从库执行完该事务才能返回,所以全同步复制的性能必然会收到严重的影响。
配置server1(主库)
1.加载插件,并查看插件加载是否成功
[root@server1 mysql]# mysql -uroot -pWestos+001
mysql> install plugin rpl_semi_sync_master soname 'semisync_master.so';
Query OK, 0 rows affected (0.09 sec)
查看插件是否加载成功
mysql> select PLUGIN_NAME,PLUGIN_STATUS FROM INFORMATION_SCHEMA.PLUGINS where PLUGIN_NAME like '%semi%';

2.启动半同步复制,并查看半同步复制是否在运行
mysql> SET GLOBAL rpl_semi_sync_master_enabled=1; #启动半同步复制
Query OK, 0 rows affected (0.00 sec)
mysql> show status like '%rpl%'; #查看半同步复制的状态是否是打开状态的
mysql> show variables like '%rpl%'; #查看半同步复制的一些参数变量
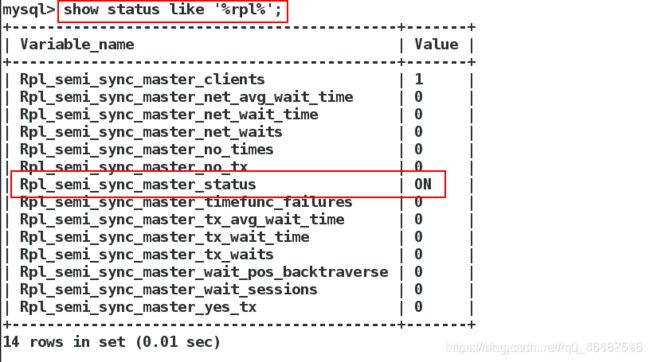

rpl_semi_sync_master_timeout的值是10000(单位是毫秒),表示半同步复制时,当从库的io线程关闭时,主库等待10s。
当然10s这个时间是可以改的,通过参数SET GLOBAL rpl_semi_sync_master_timeout =N;更改。在实际的生产过程中,为了防止数据丢失,一般将N设置为无穷大。
配置server2(从库)
1.加载插件,并查看插件加载是否成功
[root@server2 mysql]# mysql -uroot -pWestos+001
mysql> install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
Query OK, 0 rows affected (0.05 sec)
查看插件是否加载成功

2.启动半同步复制,并查看半同步复制是否在运行
mysql> SET GLOBAL rpl_semi_sync_slave_enabled=1; #启动半同步复制
Query OK, 0 rows affected (0.00 sec)
slave端启动半同步复制之后,不能立即生效,需要重启slave端的io线程
mysql> stop slave IO_THREAD;
Query OK, 0 rows affected (0.02 sec)
mysql> start slave IO_THREAD;
Query OK, 0 rows affected (0.00 sec)
查看半同步复制状态
mysql> show status like '%rpl%'; #查看半同步复制是否打开
mysql> show variables like '%rpl%'; #查看半同步复制的一些参数变量


测试:
1.在从库关闭io线程
mysql> stop slave IO_THREAD;
Query OK, 0 rows affected (0.02 sec)
2.在主库更新数据,并查看更新以后的数据
mysql> use westos;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> insert into usertb values ('user6','666');
Query OK, 1 row affected (10.06 sec) #一直停留10秒才会返回OK
此时可以看到,数据传送成功之后,半同步复制就会关闭(这是因为从库没有成功接收到数据)。
show status like '%rpl%'或show status like 'semi’都可以。
Rpl_semi_sync_master_no_tx为失败次数,yes为成功次数
Rpl_semi_sync_master_yes_tx为1,半同步成功
mysql> show status like '%rpl%';
+--------------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------------+-------+
| Rpl_semi_sync_master_clients | 0 |
| Rpl_semi_sync_master_net_avg_wait_time | 0 |
| Rpl_semi_sync_master_net_wait_time | 0 |
| Rpl_semi_sync_master_net_waits | 1 |
| Rpl_semi_sync_master_no_times | 1 |
| Rpl_semi_sync_master_no_tx | 1 |
| Rpl_semi_sync_master_status | OFF |
| Rpl_semi_sync_master_timefunc_failures | 0 |
| Rpl_semi_sync_master_tx_avg_wait_time | 0 |
| Rpl_semi_sync_master_tx_wait_time | 0 |
| Rpl_semi_sync_master_tx_waits | 0 |
| Rpl_semi_sync_master_wait_pos_backtraverse | 0 |
| Rpl_semi_sync_master_wait_sessions | 0 |
| Rpl_semi_sync_master_yes_tx | 0 |
+--------------------------------------------+-------+
14 rows in set (0.00 sec)
3.在从库查看更新之后的数据
mysql> use westos;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from usertb;
+----------+----------+
| username | password |
+----------+----------+
| user1 | 123 |
| user2 | 456 |
| user3 | 789 |
+----------+----------+
3 rows in set (0.00 sec)
发现内容没有同步
4.在从库打开io线程,再次查看更新以后的数据
mysql> start slave IO_THREAD;
Query OK, 0 rows affected (0.01 sec)
mysql> select * from usertb;
+----------+----------+
| username | password |
+----------+----------+
| user1 | 123 |
| user2 | 456 |
| user3 | 789 |
| user6 | 666 |
+----------+----------+
4 rows in set (0.00 sec)
当从库打开io线程之后,从库就接受到了数据,那么半同步复制又会重新开启
结论:
从上述测试的过程中可知:当从库的io线程关掉之后,在主库插入数据,会有10s的停留才会返回OK,在从库看不到刚刚插入的数据,当打开从库的io线程后,此时从库又可以看到主库刚刚插入的数据。
表明基于GTID的主从数据库的半同步复制搭建成功。
值的注意的是:
半同步的设置是临时的,如果重新启动mysqld服务,那么半同步的设置就会失效。需要在主库和从库上重新打开半同步的设置。
五、基于主从复制(半同步复制)使用 MySQLProxy实现 Mysql 读写分离
配置代理服务器server3
<1>下载软件:mysql-proxy-0.8.5-linux-el6-x86-64bit.tar.gz,并将其解压到/usr/local目录下:
[root@server3 Mysql]# tar zxf mysql-proxy-0.8.5-linux-el6-x86-64bit.tar.gz -C /usr/local/
—C表示指定解压目录
<2>为了方便,做软链接
[root@server3 local]# ln -s mysql-proxy-0.8.5-linux-el6-x86-64bit/ mysql-proxy
<3>为了方便,编辑系统的环境变量:这样就能直接执行mysql-proxy命令,而不需要进入bin目录下执行命令:./mysql-proxy
[root@server3 bin]# vim ~/.bash_profile
PATH=$PATH:$HOME/bin:/usr/local/mysql-proxy/bin
[root@server3 mysql-proxy]# source ~/.bash_profile
<4>在解压之后的目录中建立目录conf(配置文件目录)和log(日志目录),用来存放日志和配置文件,并编辑conf目录下的配置文件mysql-proxy.conf文件。
[root@server3 bin]# cd /usr/local/mysql-proxy
[root@server3 mysql-proxy]# mkdir conf
[root@server3 mysql-proxy]# cd conf/
[root@server3 conf]# vim mysql-proxy.conf
[mysql-proxy]
daemon=true #定义以守护进程模式启动(打入后台)
user=root #执行mysqql-proxy的用户(这个可写可不写,因为运行mysql-proxy的本身就是root用户)
pid-file=/usr/local/mysql-proxy/log/mysql-proxy.pid #定义mysql-proxy的pid文件路径
plugins=proxy #加载proxy的插件
log-level=debug #定义log日志级别,由高到低分别有(error|warning|info|message|debug),因为这里是测试,所以定义日志级别为debug
log-file=/usr/local/mysql-proxy/log/mysql-proxy.log #定义mysql-proxy的log文件路径
keepalive=true #使进程在异常关闭后能够自动恢复(保持连接)
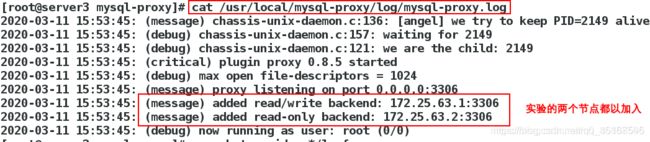
proxy-address=172.25.83.3:3306 #调度器IP
proxy-read-only-backend-addresses=172.25.83.2:3306 #定义后端只读服务器地址(从库IP)
proxy-backend-addresses=172.25.83.1:3306 #定义后端主服务器地址(主库IP)
proxy-lua-script=/usr/local/mysql-proxy/share/doc/mysql-proxy/rw-splitting.lua #自带的lua脚本文件所在位置
值的注意的是:该配置文件中不能有空格,同时将注释全部删掉,否则会报错。
这还不是最坑的,最坑的是:即使删掉注释,去除多余的空白字符,仍然可能会报如下错误:
2018-09-21 06:39:40: (critical) Key file contains key “daemon” which has a value that cannot be interpreted.
或者
2018-09-21 06:52:22: (critical) Key file contains key “keepalive” which has a value that cannot be interpreted.
出现以上问题的原因是daemon=true,keepalive=true现在不这样写了,要改为:
daemon=1
keepalive=1
<5>编辑自带的lua脚本
[root@server3 mysql-proxy]# vim /usr/local/mysql-proxy/share/doc/mysql-proxy/rw-splitting.lua
38 if not proxy.global.config.rwsplit then
39 proxy.global.config.rwsplit = {
40 min_idle_connections = 1, #改为1
41 max_idle_connections = 2, #改为2
42
43 is_debug = false
44 }
这里1,2的意思是:MySQL Proxy会检测客户端连接,当连接没有超过min_idle_connections预设值时,不会进行读写分离,默认最小4个(最大8个)以上的客户端连接才会实现读写分离。现改为最小1个最大2个,便于读写分离的测试,生产环境中,可以根据实际情况进行调整。
<6>启动mysql-proxy服务:此时发现服务起不来,因为权限过大。根据提示需要修改为660。
#启动mysql-proxy服务
[root@server3 mysql-proxy]# /usr/local/mysql-proxy/bin/mysql-proxy --defaults-file=/usr/local/mysql-proxy/conf/mysql-proxy.conf

<7>修改mysql-proxy.conf文件的权限为660。
[root@server3 mysql-proxy]# chmod 660 /usr/local/mysql-proxy/conf/mysql-proxy.conf
<8>重新启动mysql-proxy服务,并查看端口,以确保服务已经正常启动。
[root@server3 conf]# mysql-proxy --defaults-file=/usr/local/mysql-proxy/conf/mysql-proxy.conf
[root@server3 conf]# netstat -antulpe #查看mysql-proxy的3306端口是否存在
查看日志确定节点以加入集群:
[root@server3 mysql-proxy]# cat /usr/local/mysql-proxy/log/mysql-proxy.log
<9>安装losf软件以提供losf命令,用来查看调度器的连接数
[root@server3 mysql-proxy]# yum install lsof-4.87-4.el7.x86_64 -y
[root@server3 mysql-proxy]# lsof -i:3306 #查看本机的3306端口的连接数
配置server1(主库):
<1>登录数据库,创建数据库westos以便测试,创建用户并且给用户进行授权(读和写的权限:update,select,insert)
[root@server1 ~]# mysql -uroot -pWestos+001
mysql> grant,update,select on *.* to dd@'%' identified by 'Westos+001' ;
Query OK, 0 rows affected, 1 warning (0.08 sec)
#建立proxy用户,并给proxy用户授权(select,insert,update权限)
配置物理机(客户端)
<1>安装mysql,以提供mysql命令
值的注意的是:这里必须用yum安装mysql,不可以跟server1,server2一样安装rpm包。(因为mysql数据库的读写分离,不适用于最新版的mysql服务)
[root@foundation63 images]# yum install mariadb -y
读写分离测试:
第一次连接:
<1>物理机:以proxy用户的身份登录数据库。
[root@foundation63 images]# mysql -h 172.25.63.3 -udd -pWestos+001
<2>在server3(代理服务器)上查看调度器的连接数
[root@server3 mysql-proxy]# lsof -i:3306

第二次连接:
<3>物理机:重新开一个终端(上次的那个登陆数据库的终端,不要退出数据库),以proxy用户的身份登录数据库。
[kiosk@foundation63 images]$ mysql -h 172.25.63.3 -udd -pWestos+001
<4>在server3(代理服务器)上查看调度器的连接数。
[root@server3 mysql-proxy]# lsof -i:3306

第三次连接:
<5>物理机:重新开一个终端(上两次的那个登陆数据库的终端,不要退出数据库),以proxy用户的身份登录数据库。
[kiosk@foundation63 images]$ mysql -h 172.25.63.3 -udd -pWestos+001
<6>在server3(代理服务器)上查看调度器的连接数。
[root@server3 mysql-proxy]# lsof -i:3306

从上面的测试过程和结果可以看出,当客户端的连接数超过2个时,客户端指向的是server2(从库:只能读的库),表示读写分离配置成功,此时就可以进行读写分离的测试:
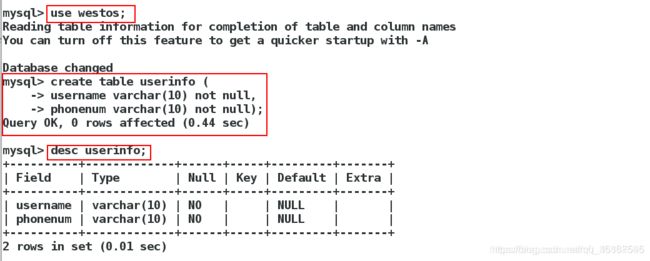
在server1建立新表:
mysql> create table userinfo (
-> username varchar(10) not null,
-> phonenum varchar(10) not null);
Query OK, 0 rows affected (0.44 sec)
此时,在客户端的任意一个终端对数据库进行写入操作:
[kiosk@foundation63 images]$ mysql -h 172.25.63.3 -udd -pWestos+001
MySQL [(none)]> use westos;
MySQL [westos]> insert into userinfo values ('redhat-cc','123456');
写入后可以查看到表的内容

此时停止从库:
在server2:
mysql> stop slave;
Query OK, 0 rows affected (0.06 sec)

在客户端再插入一条数据,并查看表格内容:
MySQL [westos]> insert into userinfo values ('redhat-qq','666666');
MySQL [westos]> select * from userinfo;

此时在server1中查看可以看到新插入的内容:

server2中查不到新插入的内容:

说明关闭server2(从库:只能读的库)后,客户端读的功能受到了影响
此时打开server2,并在客户端再读就可以查看到新插入的内容:
在server2:
mysql> start slave;

在客户端查看:

表明读写分离配置成功