ECCV 2020 | 自监督任务辅助的知识蒸馏

本文介绍了一种利用自监督任务辅助知识蒸馏的方法:Knowledge Distillation Meets Self-Supervision [1]. 这篇文章(以下简称SSKD)来自香港中文大学和南洋理工大学,被ECCV 2020接收。
本文用一种简洁易理解的方式来分享这篇工作的思路来源,希望对读者有所启示。

![]()
壹
模型压缩与知识蒸馏
近年来,随着底层计算硬件和分布式平台的快速发展,卷积神经网络(CNN)向着更宽、更深的方向大步前进,这些模型有着优异性能的同时,过大的模型规模和过长的推理时间限制了它们向移动设备迁移的可能,为解决这一问题,多种模型压缩算法被提出,旨在压缩大模型,以尽可能小的性能损失部将其部署在计算资源受限的移动设备上。
模型压缩有很多种选择,如剪枝(pruning)维持模型结构不变,试图剪掉对网络影响不大的通道(channel),如量化(quantization)将32-bit的高精度计算降至8-bit的低精度计算,本文要讨论的知识蒸馏(knowledge distillation)也是模型压缩的一种,由Hinton [2]在2015年首次提出。

图1 知识蒸馏框架
不同于剪枝和量化,知识蒸馏并非去修改一个已有的大模型,而是构建一个新的小模型,期望在大模型的监督下,小模型的性能可以得到提升,如图1所示,通常称大模型为教师模型(teacher),称小模型为学生模型(student)。
Hinton提出知识蒸馏基于这样一个观察:一个训练好的模型在测试时,给出的预测结果并不是one-hot形式(某一类为1,其余类全0)的,对于某一张测试图像,即使模型分类正确,在错误的类别上模型仍然会给出一些值较小但非零的概率。
Hinton认为这些小而非零的值包含类与类之间的相似度关系,例如输入一张狗的图像,模型可能在狗的类别上给出0.7的概率,而在猫和狼的类别上给出0.1的概率,这种类间关系是模型在训练过程中基于数据集自动学会的,能够提供比人工标注的one-hot标签更丰富的信息,用一个训好的大模型的输出来监督另一个小模型,其结果比只用人工标签更好。
来自teacher的输出被形象化为知识(knowledge),而从teacher模型提取知识并转移至student,与化学中从混合物中蒸馏出某纯净物的过程相似,所以用teacher监督student的方法,被称作蒸馏(distillation)。
![]()
贰
现行蒸馏方法
一个应用于分类任务的CNN通常包含两部分:
1)用于提取特征的网络骨架backbone
2)用于将特征映射到分类结果的分类器classifier
一张输入图像经过整个网络处理,除了最后一层输出分类结果外,还会得到非常多不同尺度、不同语义的中间层特征,在Hinton最早尝试用最后一层输出作为knowledge后,后续的工作便开始探索中间层特征及其变体作为knowledge的可能性,例如FitNets [3]用feature map本身,AT [4]用attention map,FSP [5]用层之间的gram矩阵等等,这些工作可以用一个统一的公式来表达:
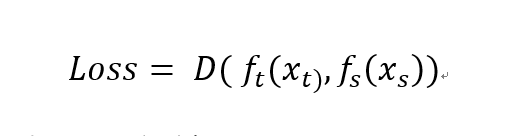
其中x表示feature,下标t和s分别表示teacher和student,f(·)表示某种变换,D(·)表示某种距离度量,公式的意思是对teacher和student的特征各自做某种变换,并要求二者的变换结果在距离度量D下尽量接近,f(·)和D(·)的变化也就对应了不同方法让student去模仿teacher的不同部分。
早期的知识蒸馏大多是一元模仿,即针对单张图像的模仿,后续的工作[6,7]将一元拓展至二元,即针对样本间关系的模仿,这一拓展使得对student特征空间中样本的分布有了更加结构化的约束,student性能得到进一步提升。
![]()
叁
自监督任务辅助的知识蒸馏
回顾之前的知识蒸馏方法,不难发现他们的区别在于不同方法将teacher模型的不同要素视为knowledge的来源,而共性在于这些knowledge全都是最开始的分类任务的中间产物。
可以拟人化地思考teacher模型和student模型的关系,如同现实生活中老师和学生的关系。
知识蒸馏的目标是在teacher模型监督下,student模型在目标数据集上取得好的准确率,对应了现实中在老师的监督和指导下,学生在某学科的考试中取得好成绩;
一张图像送入teacher网络,经过层层feature的提取最后得到分类结果,对应了现实中老师对于一道题目的解法,那么诸多的知识蒸馏方法中,有的学feature,有的学attention,有的学gram matrix,其实很像学生在学老师解题过程中的一些关键步骤。
以往知识蒸馏的共性是knowledge都来自原始的分类任务,对应现实中,学生仅仅去学老师在这一学科中的知识,虽然最终目标依然是在这一学科中取得好成绩,但是不同学科间的知识显然存在可以相互借鉴的点,
例如学习电动力学时,数学知识会很有帮助,学习英文语法时,中文语法也有助于对比和思考,所以论文[1]的出发点便是:通过自监督任务,补足teacher模型中原本分类任务无法覆盖的那部分知识,通过分类任务和自监督任务的双重蒸馏,促进student模型的性能提升,原理如图2。
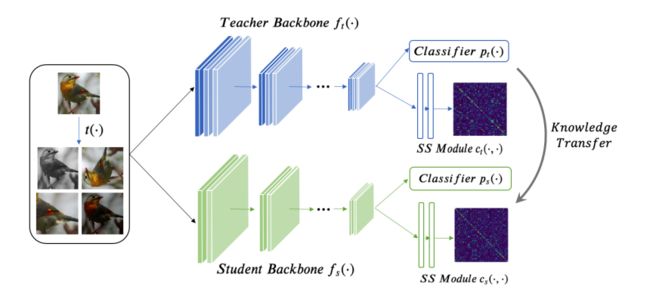
图2 自监督辅助的知识蒸馏
那么为什么要选取自监督任务作为辅助呢,有两点考虑:
1)任务之间的关系密切与否很重要,如同学科间的关系一样,显然中国近代史知识对于学习量子力学几乎没有帮助,类似地,一个与分类任务相距甚远的其他任务(如风格迁移)对于原本的分类任务也几乎没有帮助,而自监督任务与分类任务使用相同的数据、相同的evaluation方式,区别仅在于数据是否有标签,所以自监督任务与分类有着非常密切的联系,也更有可能提供辅助信息;
2)自监督任务的一大优势是不需要人工标注,所以研究者可以仍然使用原本的数据集,不引入任何外部数据和标注,即可实现自监督辅助。
自监督的任务有非常多种,SSKD所采用的是性能较高的对比学习(contrastive learning [8]),其原理可以概括为:对输入图像,从变换图片池中挑选出与之最匹配的那一个。本文主要讨论思路,具体自监督任务细节可参考SSKD原文 。
![]()
肆
实验结果
1) 不同知识蒸馏方法的student性能。作者在CIFAR100和ImageNet数据集上,尝试了不同的teacher-student网络架构组合,在每一个组合下,所有student模型使用相同的teacher模型作为监督,并最终以student的top-1准确率作为评价标准。结果如图3、图4、图5。
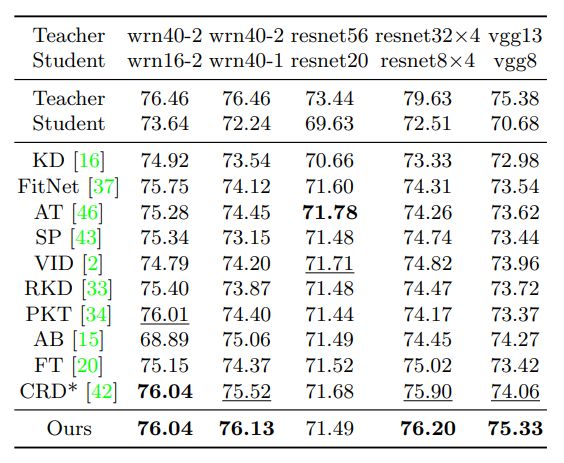
图3 CIFAR100测试集准确率,teacher和student使用相似网络结构
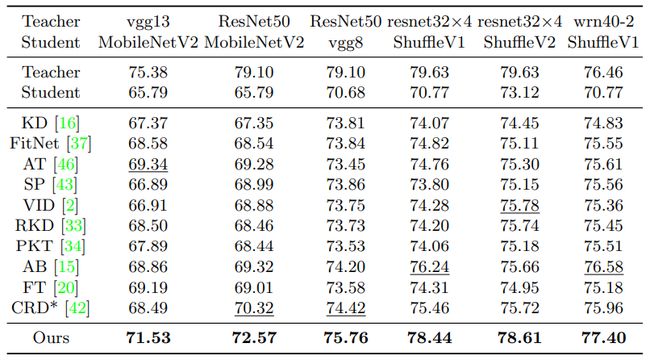
图4 CIFAR100测试集准确率,teacher和student使用不同网络结构

图5 ImageNet测试集准确率,teacher:ResNet34,student:ResNet18
2)Teacher和student的相似度评估。自监督任务的引入为student的模仿带来了更多约束,从而使得student更“像”teacher。作者使用两个指标:KL-divergence和CKA-similarity[9]来衡量student模型与teacher模型的相似度,两个模型都是在CIFAR100的训练集上训练的,但计算相似度使用了未见过的CIFAR100测试集、STL测试集、SVHN测试集,结果如图6,在3个测试集上,所提出的方法都取得了较高的相似度。

图6 teacher-student相似度比较
3) 鲁棒性测试。在实验过程中发现,SSKD在训练集的准确率低于其他知识蒸馏方法,但测试集准确率更高,推测SSKD具有较强的抵抗过拟合效果,为验证这一猜想,作者在少样本和噪声两种环境下进一步测试SSKD和其他KD方法的性能,结果如图7。可以看到,在比较极端的情况下(25%训练数据或50%数据噪声),SSKD都有更为优异的表现。

图7 少样本和噪声环境下的准确率
![]()
伍
总结
知识蒸馏的核心问题在于如何定义知识,本文探究了一种借助自监督任务来定义知识的可能性,至于如何将二者更有效地结合起来,还需后续的研究者来回答。
参考文献:
[1] Guodong Xu, Ziwei Liu, Xiaoxiao Li, Chen Change Loy. Knowledge Distillation Meets Self-Supervision. In ECCV, 2020.
[2] Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. In: NIPS Deep Learning and Representation Learning Workshop, 2015
[3] Romero, A., Ballas, N., Kahou, S.E., Chassang, A., Gatta, C., Bengio, Y.: Fitnets: Hints for thin deep nets. arXiv preprint arXiv:1412.6550, 2014
[4] Zagoruyko, S., Komodakis, N.: Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. In ICLR, 2017
[5] Yim, J., Joo, D., Bae, J., Kim, J.: A gift from knowledge distillation: Fast optimization, network minimization and transfer learning. In CVPR, 2017
[6] Tung, F., Mori, G.: Similarity-preserving knowledge distillation. In CVPR, 2019
[7] Park, W., Kim, D., Lu, Y., Cho, M.: Relational knowledge distillation. In CVPR, 2019
[8] Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for contrastive learning of visual representations. arXiv preprint arXiv:2002.05709, 2020
[9] Kornblith, S., Norouzi, M., Lee, H., Hinton, G.E.: Similarity of neural network representations revisited. In ICML, 2019
END

备注:自监督

自监督/无监督学习交流群
关注最新最前沿的自监督、无监督学习技术,
若已为CV君其他账号好友请直接私信。
我爱计算机视觉
微信号:aicvml
QQ群:805388940
微博知乎:@我爱计算机视觉
网站:www.52cv.net

在看,让更多人看到 