分布式基础(6)-分布式共识之Paxos、Raft算法
文章目录
- 一.分布式共识
- 二.Paxos算法
- Paxos角色定义
- 1.Basic Paxos
- 1.算法步骤
- 2.基本流程
- 3.部分节点失败
- 4.Proposer失败
- 5.活锁问题
- 2.Multi Paxos
- 0.Leader
- 1.算法步骤
- 2.角色优化
- 3.Multi Paxos的优点
- 三.Raft算法
- 1.角色定义
- 2.核心流程
- 1.Leader Selection
- 1.1、初始化Leader
- 1.2、重新选举Leader
- 1.3、双候选人选举
- 2.Log Replication
- 1.Log复制过程
- 2.网络分区发生
- 四.总结及推荐
本文主要参考自相关书籍和网络文章,并附上自身的一些理解,如有遗漏或错误,还望海涵并指出。谢谢!
一.分布式共识
之前我们已经了解过分布式系统中会出现的分布式一致性问题:当分布式的节点发生了网络分区时,可用性和强一致性只可选择一者。
而分布式共识描述的是分布式系统中,如何使所有的分布式节点都达成共识,譬如在节点宕机后,其他的节点如何达成这个节点“已经宕机”的共识?或是要选举出某个节点作为Master,那么其他节点如何达成“该节点作为Master”的共识?这就是分布式共识问题。
在分布式共识问题中,经典的解决方法有Paxos、Raft和ZAB算法。
在此之前,我们需要先了解一下拜占庭将军问题:
https://www.zhihu.com/question/23167269/answer/232108407
11位拜占庭将军去打仗, 他们各自有权力观测敌情并作出判断, 进攻或撤退, 那么怎么让他们只用传令兵达成一致呢?一种很符合直觉的方法就是投票,每位将军作出决定后都将结果"广播"给其余所有将军, 这样所有将军都能获得同样的11份(包括自己)结果, 取多数, 即可得到全军都同意的行为.但如果这11位将军中有间谍呢? 假设有9位忠诚的将军, 5位判断进攻, 4位判断撤退, 还有2个间谍恶意判断撤退, 虽然结果是错误的撤退, 但这种情况完全是允许的. 因为这11位将军依然保持着状态一致性.暂时从战争故事中抽离出来, 分布式数据库最糟糕的问题绝对不是写入或者读取失败, 而是状态不同步, 还感知不到. 这个的后果就是correctness不能保证, 那程序就没有任何意义了.2个间谍怎么破坏状态一致性呢? 他们跟5位判断进攻的将军说, 我们支持进攻, 那么这5位将军统计发现7位支持进攻, 4位支持撤退, 将发动进攻. 又跟4位撤退的将军说, 我们支持撤退, 一统计, 5票进攻, 6票撤退, 立马撤退. 这场战争必输无疑了.避免这种状态不同步的问题, 称之为"广义拜占庭将军问题"。
简单地理解这个问题,就是当叛变者不超过 3分之1时,存在有效的算法,使得忠诚的将军们达到一致的结果。
用数学公式来表达就是,假设节点总数为 N, 叛变将军数为 F, 当 N >= 3F + 1,问题就有解。
Byzantine Fault Tolerant (BFT) 算法就是解决这个问题的。
二.Paxos算法
Paxos算法是分布式宗师Lamport提出的一种基于消息传递的分布式一致性算法,使其获得2013年图灵奖。也是经典的分布式共识算法,不过由于实现复杂并且偏理论性,并且难于理解,所以主要作为理论研究居多。
Paxos角色定义
Paxos算法将分布式系统的节点分为以下四类角色:
- Client(客户端):系统外部角色,对Proposer发出请求。
- Proposer(提议者):接收Client的请求,并提出提案,提案信息包括提案编号和提议的值([n, v])
- Acceptor(接收者):接受提案并对提案投票
- Learner(告知者):被告知对提案的投票结果,不参与投票过程
1.Basic Paxos
Basic Paxos是一种基本的Paxos算法变种,实现比较简单。
1.算法步骤
- 一阶段:Prepare,Proposer提出一个提案,编号为n,该编号大于Proposer之前提出的提案编号则请求Acceptor接受提案
- 一阶段:Promise,如果n大于该Acceptor之前接受的提案编号则接受,否则拒绝
- 二阶段:Accept,如果大多数Acceptor同意该提案,则Proposer会发出Accept请求,此请求包含了该提案编号n和提案内容
- 二阶段:Accepted,如果Acceptor在Accept期间没有接收到任何编号大于n的提案,则接收此提案内容,否则忽略
2.基本流程
现在演示Basic Paxos的基本请求流程:

- Client向Proposer发送请求
- Proposer进入Prepare阶段,对Acceptor发出提案(编号为1)
- Acceptor接收到提案,进入Promise阶段,假设a、b、c三个Acceptor都同意该提案(Promise(1, {Va, Vb, Vc}))
- 大多数Acceptor都同意该提案,Proposer向Acceptor发出Accept请求(提案内容为Vn)
- 在这个期间没有其他新的提案产生,所以Acceptor接受此提案,进入Accepted阶段,然后告知Learner记录结果
- Learner记录下结果后,响应Client
3.部分节点失败
上述的基本流程是最理想的情况下,全部Acceptor都同意提案的情况,接下来演示的是部分节点失败(不同意提案或者是Acceptor节点宕机)时的Basic Paxos流程:

- Client向Proposer发送请求
- Proposer进入Prepare阶段,对Acceptor发出提案(编号为1)
- Acceptor接收到提案,进入Promise阶段,此时有一个Acceptor不同意或宕机,但是仍然有两个节点同意,满足大多数同意提案的情况(Quoroms Agree)
- Proposer向Acceptor发出Accept请求(提案内容为V)
- 在此期间没有其他的提案,所有Acceptor同意提案(Accepted),并告知Learner记录结果,响应给Client
4.Proposer失败
现在来看看Basic Paxos中,Proposer失败的场景。由于Proposer也是一个节点,所以有可能出现宕机的问题。

- Client向Proposer发送请求
- Proposer进入Prepare阶段,对Acceptor发出提案(编号为1)
- Acceptor接收到提案,进入Promise阶段,假设a、b、c三个Acceptor都同意该提案
- Proposer失败
- 此时会重启另一个Proposer,来重新发送提案,继续执行Prepare、Promise、Accept和Accepted的过程
5.活锁问题
Basic Paxos在多个Proposer的情况下会出现活锁问题,导致整个系统不能正常工作,出现对多个提案进行竞争Accept的情况。
https://zhuanlan.zhihu.com/p/31780743

2.Multi Paxos
为了解决Basic Paxos的多个提案下的活锁问题和需要两个阶段的网络来回问题,此时出现了Paxos算法的另一种变种:Multi Paxos
0.Leader
在Multi Paxos中,只有一个Proposer可以对Acceptor提出提案,该proposer被称为Leader。
1.算法步骤

- Leader确认阶段:其中一个Proposer对Acceptor发送一个提案,提案中带有n标志着这是某个Proposer节点(Prepare);Acceptor对这个Proposer进行确认(Promise),然后该Proposer发出Accept请求,确定自身为Leader(Accepted)
- 请求阶段:在该Leader的有效期内,对Acceptor发送请求,但是无需再进行Prepare和Promise阶段,Acceptor会同意该Leader的提案,直接进入Accepted阶段,然后Acceptor响应Learner记录该提案响应客户端,并告诉Leader
2.角色优化
对于Multi Paxos算法,可以将Proposer和Acceptor角色给合并为一个角色Servers:
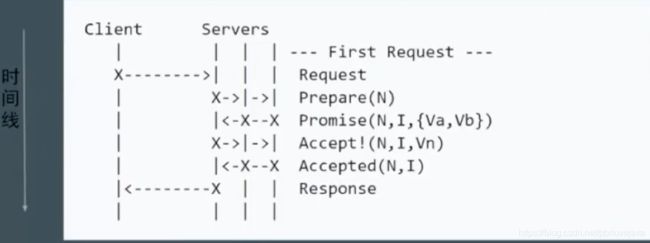
这样,Client向Servers中选举出来的Leader发送请求,然后Leader向其他Server节点重复Leader确认阶段和请求阶段即可。
3.Multi Paxos的优点
- 首次请求进行Proposer的Leader选举后,Client的所以请求都由该Leader发送,不会出现活锁现象
- 选举出Leader后,Leader发送的请求只需要一轮网络RPC即可(直接进入Accept和Accepted阶段)
三.Raft算法
由于Paxos算法实在太复杂,并且难于实现,所以产生了Raft算法。Raft算法可以视为Multi Paxos算法的精简版本,易于理解和实现。
关于Raft的动画演示可以参考该网站:
http://thesecretlivesofdata.com/raft/
1.角色定义
- Client:系统外部客户端
- Leader:负责接受Client的写请求,并将写请求同步到所有的Follower
- Follower:同步于Leader的数据
- Candidate:当一定时间内不存在Leader时,会有相应的Follower成为候选者进行Leader选举
2.核心流程
1.Leader Selection
Raft将Leader选举和Log复制过程分开成两个部分,分别进行。首先会进行Leader选举,选举出系统中的Leader。
1.1、初始化Leader
在系统刚启动时,所有的节点都将被视为Follower,这时需要初始化一个节点作为Leader。
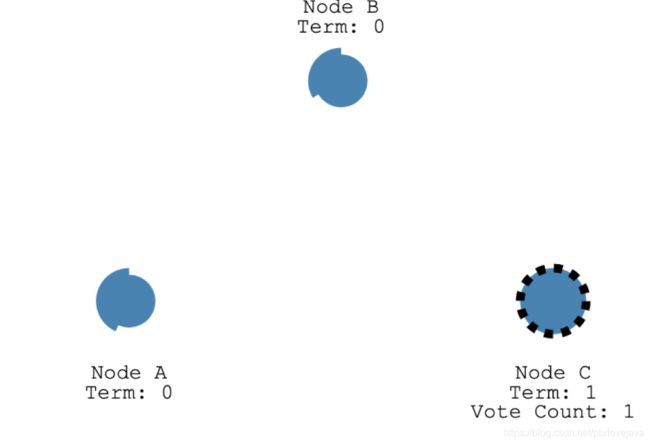
首先,每个节点都拥有两个超时时间,第一个超时时间为选举超时时间(选举超时时间会在150ms到300ms之间随机分配),这个时间是Follower成为Candidate之前所等待的时间,当Follower变成了Candidate,成为Candidate的节点将会向其他节点发送信号,建议自己成为Leader。当该Candidate获取到大多数的投票时,自身变为Leader。
选举超时时间在流逝,每个节点的超市时间都不相同
C节点的超时时间已到,成为候选人
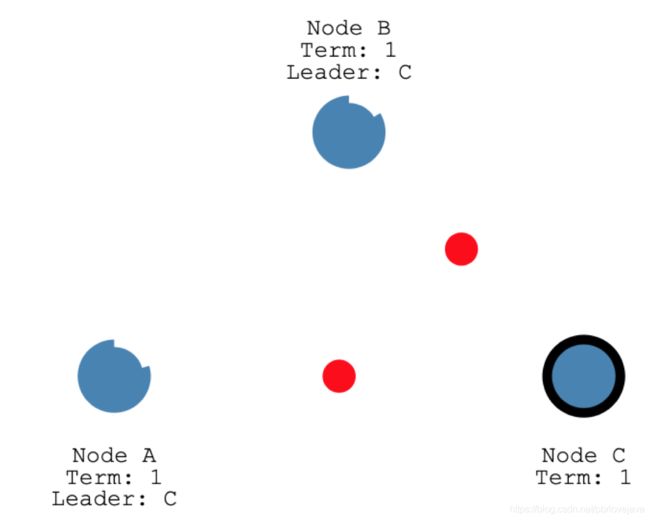
C节点向其他节点发送请求,建议投票自己成为Leader
在C节点作为Leader期间,C节点会不断地向其他节点发送心跳包,刷新其他节点的选举超时时间



1.2、重新选举Leader
当C节点宕机后,不会再向其他节点发送心跳包,这时A和B的选举超时时间会不断流逝
A节点的选举超时时间流逝完,变为候选者,向B节点发送请求,建议投票给自身,A成为Leader


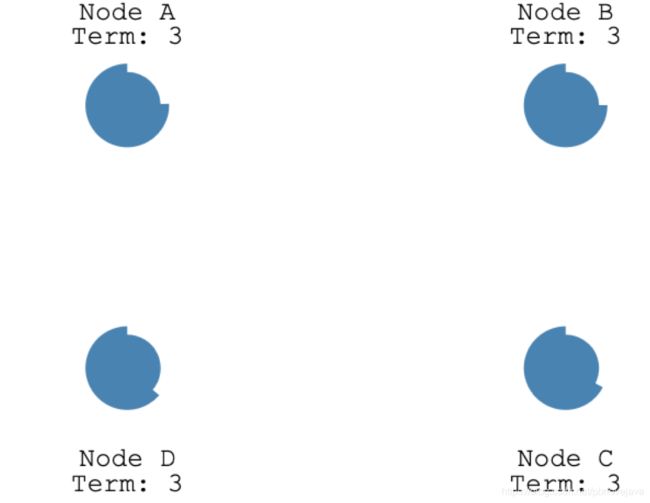
1.3、双候选人选举
加入现在有4个Follower节点的选举超时时间正在流逝
此时C、D节点同时成为候选者,然后向其他节点发送建议投票的请求
C、D此时接收到的响应应该是相同的,也就是得票数相等
此时C、D会同时刷新150ms~300ms的选举超时时间,重复选举的过程
此时D先结束了选举超时时间,所以向其他节点发送建议投票请求,D成为了Leader
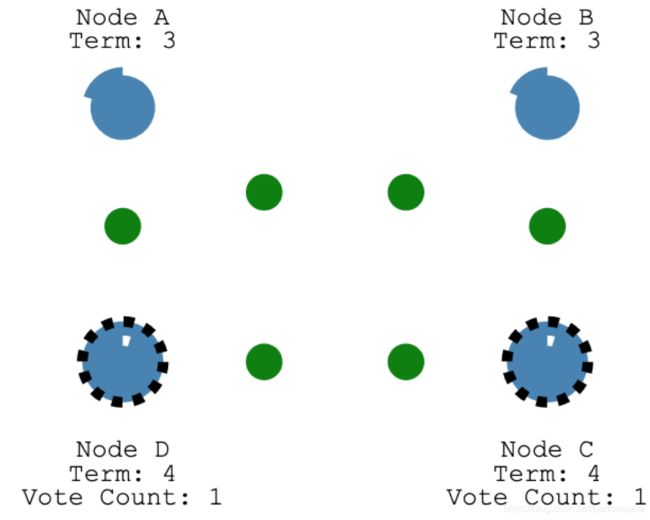



2.Log Replication

节点经过Leader选举过程之后会产生一个Leader,Client的写服务要经过Leader,Leader首先对其他Follower发送心跳包判断是否超过半数的Follower能够同步这次写操作,当半数以上的Follower能够同步到这次写操作,则表示写入成功,进行日志复制;若不能完成,则写入失败。
注意,Leader向其他Follower发送Log同步请求时,实质上也是一个心跳包,这里心跳包的作用一是携带请求,而是刷新Follower的选举超时时间。
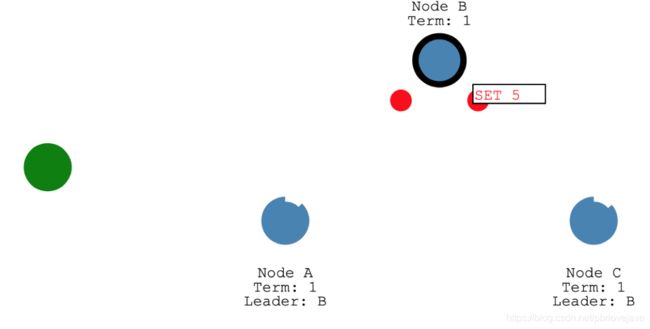
1.Log复制过程
Client向Leader B发送Set 5这个写请求
Leader B向其他Follower发送心跳包,确认是否可以同步
一旦大多数的Follower可同步,则执行Set操作
然后Leader B将写入成功的响应发送给客户端,然后其他的Follower会同步这个操作



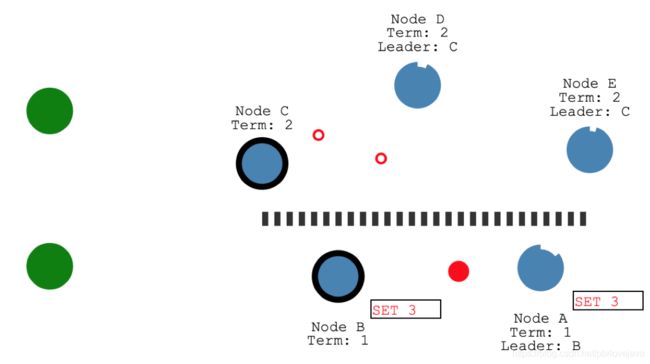
2.网络分区发生

注意,Leader选举需要半数以上的Follower同意才行,一般节点数量应该选择为奇数,因为这样才能在网络分区发生时能够正常地进行Leader选举。
假设现在系统发生了网络分区,此时A、B被划分到了一个分区中,C、D、E被划分到了另一个分区中
这时由于C、D、E的选举超时时间流逝,其中C成为候选人,向D、E节点发送投票请求,C成为所在分区的Leader
此时客户端1向Leader B发生Set 3的请求,Leader B会发送心跳包给A,确认其是否可以同步,但是却发现当前只有2个节点同意同步(包括Leader B自身),达不到节点总数的一半以上(不到3个),所以暂时不会进行数据的更新
此时客户端2向Leader C发送了一个Set 8的请求,Leader C把心跳包发送给D
和E,目前半数以上节点(3个节点)都可同步数据,所以提交日志,C、D、E节点被设置为8
当网络分区消除后,A节点发现自身的Leader年代比C的小(Term),所以把自身设置为Follower,接受C的同步,将数据同步到其他节点的状态




四.总结及推荐
看完了Basic Paxos、Multi Paxos和Raft算法的基本原理和过程,现在来做一个总结回顾和学习资源推荐哈。
Paxos算法是分布式共识领域一个十分重要的理论算法,它的实现复杂,要求苛刻,并且具备许多变种,譬如Basic Paxos和Multi Paxos。
Paxos算法需要定义的核心角色有:
- Proposer(提议者):接收Client的请求,并提出提案,提案信息包括提案编号和提议的值([n, v])
- Acceptor(接收者):接受提案并对提案投票
- Learner(告知者):被告知对提案的投票结果,不参与投票过程
Basic Paxos算法的实现过程需要两阶段RPC:
- 一阶段Prepare过程,Proposer将提案提交给Acceptor
- 一阶段Promise过程,Acceptor对提案进行投票
- 二阶段Accept过程,当大多数Acceptor对提案进行了同意投票,那么Proposer会对Acceptor发出Accept请求
- 二阶段Accepted过程,Acceptor接收到Proposer的Accept请求,判断这个过过程中没有其他的提案产生,允许该提案。Acceptor将提案发给Learner进行记录,并且响应给Proposer和客户端
Basic Paxos在多个Proposer提出多个提案的过程中,可能发生活锁。
Multi Paxos的算法相较于Basic Paxos更加简单并且易于实现,是Paxos的一种工程化变种。
Multi Paxos算法需要确认一个Proposer作为Leader,也只有这个Leader能够向Acceptor发送提案。在第一次建立对Leader的信赖后,后续的提案过程中都不需要进行一阶段Prepare、Promise过程,而是直接进行二阶段的Accept和Accepted过程,减少了一轮RPC调用,并且解决了活锁问题。
Raft算法是Multi Paxos算法的精简实现,由于其简单易实现,被广泛用于分布式系统之中,譬如Redis就是使用Raft算法来做哨兵集群的Leader选举的。
Raft算法的核心角色为:
- Leader:接受Client的写请求并将其同步给其他大部分Follower
- Follower:同步Leader的数据
- Candidate:当节点的选举超时时间流逝后,变为候选者,参与Leader选举
Raft算法分为两个核心的过程,分别是Leader选举过程和日志复制过程。
Leader选举过程:
- 初次选举
- 宕机选举
- 双候选者选举
Log复制过程:
- 大部分Follower可以同步才算写成功
- 网络分区时的同步,以大部分节点的那个分区Leader为真实Leader
推荐的学习资源
- 一致性算法(Paxos、Raft、ZAB):https://www.bilibili.com/video/BV1TW411M7Fx
- 分布式系统以及共识机制:https://www.jianshu.com/p/c49bbf8630df
- Raft算法在线调试:https://raft.github.io/
- Raft算法在线演示:http://thesecretlivesofdata.com/raft/