机器学习习题(17)
这一期中,我们讲解了相关系数、PCA与SVD、误差偏差与方差、多元共线与线性回归、聚类与分类的相关问题。
1.给定三个变量 X,Y,Z。(X, Y)、(Y, Z) 和 (X, Z) 的 Pearson 相关性系数分别为 C1、C2 和 C3。现在 X 的所有值加 2(即 X+2),Y 的全部值减 2(即 Y-2),Z 保持不变。那么运算之后的 (X, Y)、(Y, Z) 和 (X, Z) 相关性系数分别为 D1、D2 和 D3。现在试问 D1、D2、D3 和 C1、C2、C3 之间的关系是什么?
A. D1= C1, D2 < C2, D3 > C3
B. D1 = C1, D2 > C2, D3 > C3
C. D1 = C1, D2 > C2, D3 < C3
D. D1 = C1, D2 < C2, D3 < C3
E. D1 = C1, D2 = C2, D3 = C3
参考答案:(E)
解析:特征之间的相关性系数不会因为特征加或减去一个数而改变。
这道题主要是考察相关系数的计算公式:
E(X)为期望,Var(X)为方差,可以知道期望随着变量增减而增减,分子上减数被减数同时变化,总值不变。而方差不随着变量增减而增减,因此总值不变,最终相关系数不变。
更多细节可以参考《相关系数百度百科》与《协方差百度百科》与《方差百度百科》和《数学期望百度百科》
2.为了得到和 SVD 一样的投射(projection),你需要在 PCA 中怎样做?
A. 将数据转换成零均值
B. 将数据转换成零中位数
C. 无法做到
参考答案:(A)
解析:当数据有一个 0 均值向量时,PCA 有与 SVD 一样的投射,否则在使用 SVD 之前,你必须将数据均值归 0。这样一张动图就可以解释PCA了:
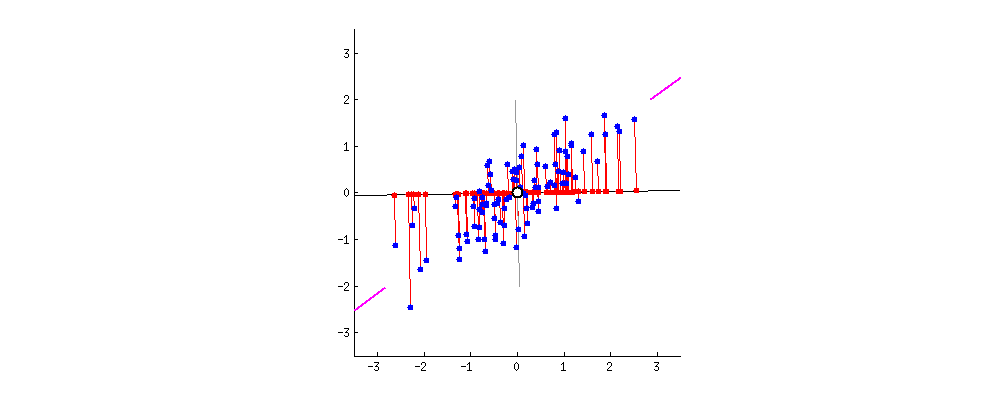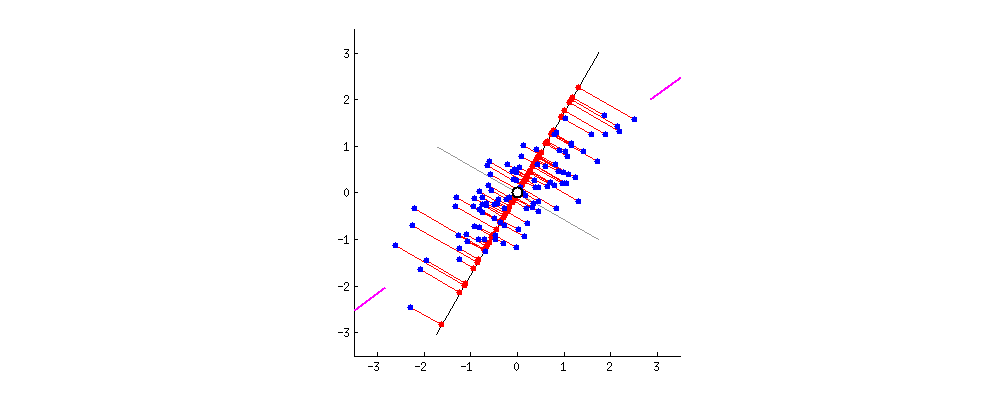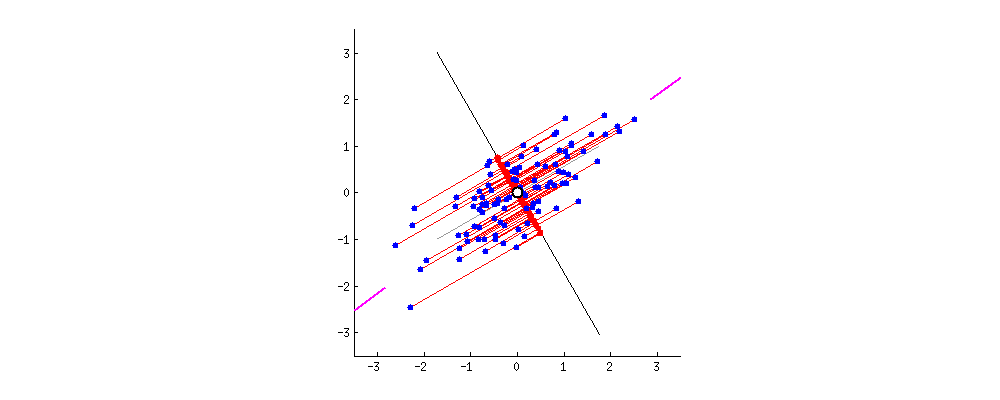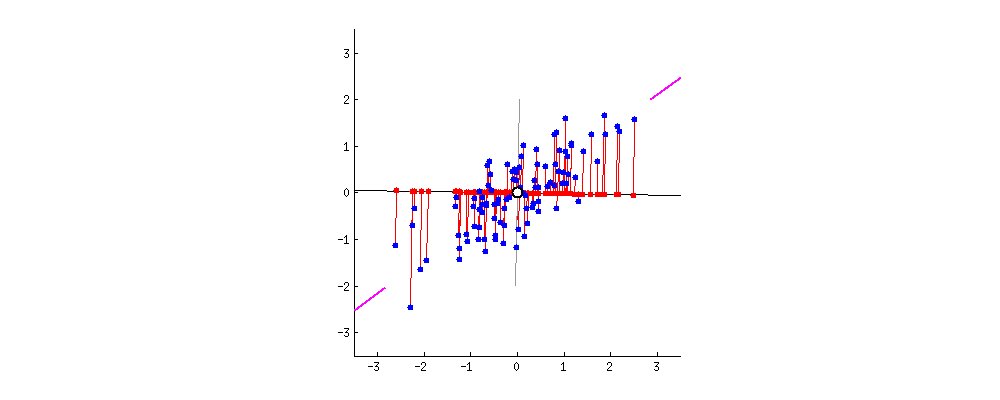
可以看到是在中心点进行处理。
更多详情可以参见《PCA和SVD的区别与联系》。
3.假设我们有一个数据集,在一个深度为 6 的决策树的帮助下,它可以使用 100% 的精确度被训练。现在考虑一下两点,并基于这两点选择正确的选项。
注意:所有其他超参数是相同的,所有其他因子不受影响。
1.深度为 4 时将有高偏差和低方差
2.深度为 4 时将有低偏差和低方差
A. 只有 1
B. 只有 2
C. 1 和 2
D. 没有一个
参考答案:(A)
解析:如果在这样的数据中你拟合深度为 4 的决策树,这意味着其更有可能与数据欠拟合。因此,在欠拟合的情况下,你将获得高偏差和低方差。过拟合的情况下则是低偏差,高方差。下面这张图能够解释:

可以看到Bias为偏差,Variance为方差。
4.在以下不同的场景中,使用的分析方法不正确的有
A. 根据商家最近一年的经营及服务数据,用聚类算法判断出天猫商家在各自主营类目下所属的商家层级
B. 根据商家近几年的成交数据,用聚类算法拟合出用户未来一个月可能的消费金额公式
C. 用关联规则算法分析出购买了汽车坐垫的买家,是否适合推荐汽车脚垫
D. 根据用户最近购买的商品信息,用决策树算法识别出淘宝买家可能是男还是女
参考答案:B
解析:预测消费公式首先应当是有监督学习,其实应当是回归模型。而聚类则是无监督的分类模型,不正确。
5.在下面的图像中,哪一个是多元共线(multi-collinear)特征?

A. 图 1 中的特征
B. 图 2 中的特征
C. 图 3 中的特征
D. 图 1、2 中的特征
E. 图 2、3 中的特征
F. 图 1、3 中的特征
参考答案:(D)
解析:在图 1 中,特征之间有高度正相关,图 2 中特征有高度负相关。所以这两个图的特征是多元共线特征。
多元共线,可以理解为多元变量呈线性关系,由此可知是图一与图二。
6.一元线性回归的基本假设不包括哪个:
A.随机误差项是一个期望值或平均值为0的随机变量;
B.对于解释变量的所有观测值,随机误差项有相同的方差;
C. 随机误差项彼此相关;
D.解释变量是确定性变量,不是随机变量,与随机误差项彼此之间相互独立;
E.解释变量之间不存在精确的(完全的)线性关系,即解释变量的样本观测值矩阵是满秩矩阵;
F.随机误差项服从正态分布
参考答案: C
解析:这道题是七月在线改编自我的一个题目中的解析,因此没有给出官方答案。随机误差项彼此不相关。
7.下面哪些对「类型 1(Type-1)」和「类型 2(Type-2)」错误的描述是错误的?
A. 类型 1 通常称之为假正类,类型 2 通常称之为假负类。
B. 类型 2 通常称之为假正类,类型 1 通常称之为假负类。
C. 类型 1 错误通常在其是正确的情况下拒绝假设而出现。
参考答案:(B)
解析:在统计学假设测试中,I 类错误即错误地拒绝了正确的假设即假正类错误,II 类错误通常指错误地接受了错误的假设即假负类错误。
首先是错杀了好人,其次才是漏掉坏人。想想就知道错杀好人比漏掉坏人更严重,因此I类是错杀好人,二类是漏掉坏人。
8.给线性回归模型添加一个不重要的特征可能会造成?
A. 增加 R-square
B. 减少 R-square
参考答案:(A)
解析:在给特征空间添加了一个特征后,不论特征是重要还是不重要,R-square 通常会增加。
在之前的题目中,我们讲到了R2系数,也叫可决系数。一般增加后,拟合的程度都会更好一些,因此R2会增加。
9.符号集a、b、c、d他们相互独立,相应概率为 12 1 2 、 14 1 4 、 18 1 8 、 116 1 16 ,其中包含信息量最小的符号是:
A、a
B、b
C、c
D、d
参考答案:A
解析:信息出现的概率越小,信息中包含的信息量就越大。
10.下列哪个不属于常用的文本分类的特征选择算法?(D)
A. 卡方检验值
B. 互信息
C. 信息增益
D. 主成分分析
参考答案:(D)
解析: 主成分分析是特征抽取,不是特征选择。