前端知识点总结——HTML
1.标准模式和怪异模式
浏览器对页面的渲染有两种模式:怪异模式(浏览器使用自己的模式解析渲染页面)和标准模式(浏览器使用W3C官方标准解析渲染页面)。不同的渲染模式会影响到浏览器对CSS代码甚至Javascript的解析。使用,浏览器将按标准模式渲染页面。
2.meta标签
meta标签定义文档元数据,使用“名称=值”的形式来表示。其用途有:(1)设置页面字符集;(2)设置关键字便于搜索引擎搜索;(3)设置网页描述信息
3. 在浏览器输入一个网址到网页内容完全被展示的这段时间内,都发生了什么事情?
(1)浏览器在接收到这个指令时,会开启一个单独的线程来处理这个指令,首先要判断用户输入的是否为合法或合理的 URL 地址,是否为 HTTP 协议请求,如果是那就进入下一步;
(2)浏览器的浏览器引擎将对此 URL 进行分析,如果存在缓存「cache-control」且未过期,则会从本地缓存提取文件(From Memory Cache,200返回码),如果缓存「cache-control」不存在或过期,浏览器将发起远程请求;
(3)通过 DNS 解析域名获取该网站地址对应的 IP 地址,连同浏览器的 Cookie、 userAgent 等信息向此 IP 发出 GET 请求;
(4)接下来就是经典的「三次握手」,HTTP 协议会话,浏览器客户端向 Web 服务器发送报文,进行通讯和数据传输;
(5)进入网站的后端服务,如 Tomcat、Apache 等,还有近几年流行的 Node.js 服务器,这些服务器上部署着应用代码,语言有很多,如 Java、 PHP、 C++、 C# 和 Javascript 等;
(6)服务器根据 URL 执行相应的后端应用逻辑,期间会使用到「服务器缓存」或「数据库」;
(7)服务器处理请求并返回响应报文,如果浏览器访问过该页面,缓存上有对应资源,与服务器最后修改记录对比,一致则返回 304,否则返回 200 和对应的内容;
(8)浏览器接收到返回信息并开始下载该 HTML文件(无缓存、200返回码)或从本地缓存提取文件(有缓存、304返回码);
(9)浏览器的渲染引擎在拿到 HTML 文件后,便开始解析构建 DOM 树,并根据 HTML 中的标记请求下载指定的 MIME 类型文件(如 CSS、 JavaScript 脚本等),同时使用并设置缓存等内容;
(10)渲染引擎根据 CSS 样式规则将 DOM 树扩充为渲染树,然后进行重排、重绘;
(11)如果含有 JS 文件将会执行,进行 DOM操作、缓存读存、事件绑定等操作。最终页面将被展示在浏览器上。
4.浏览器结构组成
浏览器一般由七个模块组成,User Interface(用户界面)、Browser engine(浏览器引擎)、Rendering engine(渲染引擎)、Networking(网络)、JavaScript Interpreter(js解释器)、UI Backend(UI 后端)、Date Persistence(数据持久化存储)
(2)浏览器引擎:可以在用户界面和渲染引擎之间传送指令或在客户端本地缓存中读写数据等,是浏览器中各个部分之间相互通信的核心
(3)渲染引擎:解析DOM文档和CSS规则并将内容排版到浏览器中显示有样式的界面,也有人称之为排版引擎,我们常说的浏览器内核主要指的就是渲染引擎
(4)网络:用来完成网络调用或资源下载的模块
(5)UI 后端:用来绘制基本的浏览器窗口内控件,如输入框、按钮、单选按钮等,根据浏览器不同绘制的视觉效果也不同,但功能都是一样的。
(6)JS解释器:用来解释执行JS脚本的模块,如 V8 引擎、JavaScriptCore
(7)数据存储:浏览器在硬盘中保存 cookie、localStorage等各种数据,可通过浏览器引擎提供的API进行调用
作为前端开发人员,我们需要重点理解渲染引擎的工作原理,灵活应用数据存储技术,在实际项目开发中会经常涉及到这两个部分,尤其是在做项目性能优化时,理解浏览器渲染引擎的工作原理尤为重要。而其他部分则是由浏览器自行管理的,开发者能控制的地方较少。
“浏览器内核”主要指渲染引擎(Rendering Engine),负责解析网页语法(如HTML、JavaScript)并渲染、展示网页。渲染引擎决定了浏览器如何显示网页的内容以及页面的格式信息。不同的浏览器内核对网页编写语法的解析也有所不同,因此同一网页在不同的内核浏览器里的渲染、展示效果也可能不同。目前主流的浏览器内核有Trident(IE)、Gecko(Mozilla Firefox)、WebKit(Safari、Chrome内核原型)以及Presto(Opera前内核)、Blink(Opera、Chrome)。
浏览器渲染引擎最重要的工作就是将 HTML 和 CSS 文档解析组合最终渲染到浏览器窗口上。渲染引擎在接受到 HTML 文件后主要进行了以下操作:解析 HTML 构建 DOM 树(Parsing HTML to construct the DOM) -> 构建渲染树(Construct render tree) -> 渲染树布局 (layout of the render tree)-> 渲染树绘制(painting the render tree)。
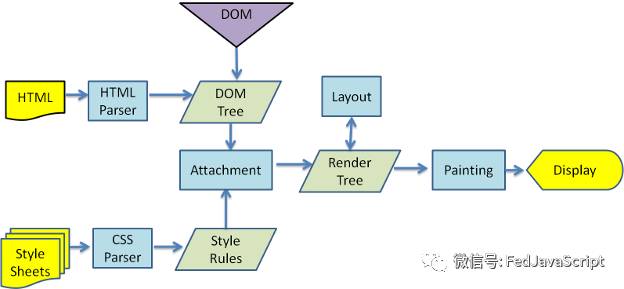
6.基于浏览器内核工作原理而进行的优化
(1)减少 JS 加载对 DOM渲染的影响:将 JS 文件放在 HTML 文档后加载,或者使用异步的方式加载 JS 代码;(2)避免重排(reflow),减少重绘(repaint):在做CSS动画的时候减少使用 width、 margin、 padding 等影响 CSS 布局的规则,可以使用 CSS3 的 transform 代替。另外值得注意的是,在加载大量的图片元素时,尽量预先限定图片的尺寸大小,否则在图片加载过程中会更新图片的排版信息,产生大量的重排;
(3)直接使用唯一的类名(而不是用tag)即可最大限度的提升渲染效率,尽量避免通配符选择器;
(4)减少 DOM 的层级:减少无意义的DOM层级可以减少渲染引擎 Attachment 过程中的匹配计算量。
7.HTML新特性
绘画canvas;媒体元素video和audio;本地离线存储localStorage长期存储数据、浏览器关闭后数据不丢失;会话存储sessionStorage的数据在浏览器关闭后自动删除;语义化更好地内容元素,如article、header、footer、nav、section;新的表单控件,如:date、time、email、url等;新的技术如WebSocket、Webworkers等;
8.HTML语义化
用合适的标签做合适的事情,HTML语义化让页面的内容结构化,结构更清晰,便于对浏览器、搜索引擎解析,即使在没有css的情况下也以一种文档格式显示,并且是容易阅读的。
9.css文件及js文件的引入位置及原因
css文件在head标签内引入:页面渲染时首先根据DOM结构生成一个DOM树然后加上CSS样式生成一个渲染树,如果CSS放在后面可能页面会出现闪跳的感觉,或者是白屏或者布局混乱直到CSS加载完成。
js文件在body标签尾部尾部引入:js是阻塞加载,当页面依次序载入到script的时候,DOM树的解析和渲染会暂停,在js载入执行完毕之前, 页面会保持后续内容不完整的状态。将script后置,可以避免这个情况,特别在脚本下载和执行耗时很长的时候会更明显。
这么做可以使得用户先看到样式,具体的操作逻辑可以等待整个网页都传输完成后再生效,有利于提高Web浏览体验.
10.浏览器页面加载机制
浏览器在拿到HTML文件后便开始进行加载:加载过程中遇到外部css文件,浏览器另外发出一个请求,来获取css文件;遇到图片资源,浏览器也会另外发出一个请求,来获取图片资源,这是异步请求,并不会影响html文档进行加载。但是当文档加载过程中遇到js文件,html文档会挂起渲染的线程,不仅要等待文档中js文件加载完毕,还要等待解析执行完毕,才可以恢复html文档的渲染线程(原因:js有可能会修改DOM,这意味在js执行完成前,后续所有资源的下载可能是没有必要的,这是js阻塞后续资源加载的根本原因)。