K-means 聚类算法的理解与案例实战

打开微信扫一扫,关注微信公众号【数据与算法联盟】
转载请注明出处: http://blog.csdn.net/gamer_gyt
博主微博: http://weibo.com/234654758
Github: https://github.com/thinkgamer
前言
工作之后,发现对算法和技术的理解和上学时学习是不一样的,当时也整理了几篇关于k-means聚类的文章,但是现在看起来比较苍白和空洞,于是打算带着重新学习的态度对以往学习过或者见过的一些机器学习算法进行温习和总结,写的不足之处还望路过大神指点一二。
《机器学习实战》kMeans算法(K均值聚类算法)
《机器学习实战》二分-kMeans算法(二分K均值聚类)
scikit-learn学习之K-means聚类算法与 Mini Batch K-Means算法
聚类分析
聚类分析(Cluster Analysisi)也被成为集群分析,基于生活中物以类聚的思想,是对某个样本或者指标进行分类多元统计分析的方法,他需要一组单独的属性特征或特性的代表变量,称为聚类变量。根据个人的样品或松紧之间的联系进行分类,一般分类的变量由研究者指定。
聚类分析的方法要求:
1. 聚类分析要简单,便于人直观的理解
2. 聚类分析主要是对未知事务的类别相似性探索,可能会有多个分析结果
3. 聚类分析一般情况必须是收敛的,无论现实中是否存在都能够得出客观的解
4. 聚类分析中的聚类属性选择是客观的,可以选择一个属性,也可以选择几个属性
5. 聚类分析的解完全依赖于研究者所选择的聚类变量,增加或者删除一些变量对最终的解都可能产生实质性的影响
什么是kmeans
其基本思想是根据随机给取的k个初始簇类中心,按照“距离最近”的原则将每条数据划分到最近的簇类中心,第一次迭代之后更新各个簇类中心,进行第二次的迭代,依旧按照“距离最近”原则进行数据归类,直到簇类不再改变,停止迭代。
具体的执行步骤如下:
- 输入:用户需要输入分类簇的数目K以及包含n个数据对象的数据集合。
- 输出:k个聚类完成的簇
- 步骤1:在输入的数据对象集合中随机初始化k个点作为k-means算法样本;
- 步骤2:计算给定的数据集合分别到初始化聚类中心的几何距离
- 步骤3:按照距离最短原则将没一点数据分配到最邻近的簇中
- 步骤4:使用每个簇中的样本数据几何中心作为新分类的聚类中心;
- 步骤5:反复迭代算法中步骤2、步骤3和步骤4直到算法收敛为止
- 步骤6:算法结束,得到输出结果。
那么这里就会引现出几个问题,
- 1: 初始簇类中心的选择?
- 2: K值的选择
- 3: “距离最近”原则具体指什么?
- 4: 怎么更新簇类中心?
- 5: 判断簇类收敛到不再改变的条件是什么?
下面我们就来一一解释这些问题
K-means 聚类中初始簇心的选择
选择初始类簇中心点对于聚类效果的好坏有很大的影响,那么我们该如何去确定簇类中心呢?
随机选取
随机选取是最简单的方法,但是也是有技巧的,我们通过对数据的预估来进行观察,从而确定初始的K值,比如说二维平面上的点,我们可以通过将其可视化到二维平面进行肉眼的判断,从而确定k值;比如说对于一些利用特征值进行聚类的数据,我们依旧可以将其进行量化到二维或者三维空间中,当然对于高维数据,首先可以进行降维操作,继而进行可视化。
随机选择法,假设有M行数据,我们可以用使用python的random模块来随机选取K行作为初始的聚类中心。
初始聚类
选用层次聚类或者Canopy算法进行初始聚类,然后利用这些类簇的中心点作为KMeans算法初始类簇中心点。
常用的层次聚类算法有BIRCH,ROCK,Canopy算法。
层次聚类的思想是:
一层一层地进行聚类,可以从下而上地把小的cluster合并聚集,也可以从上而下地将大的cluster进行分割。似乎一般用得比较多的是从下而上地聚集,这里我们说下自下而上的聚类。
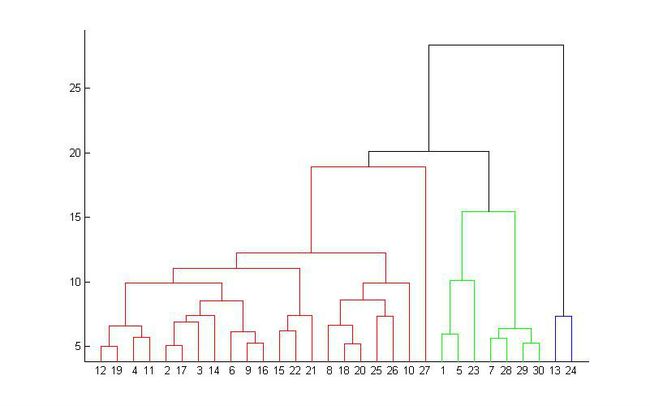
所谓从下而上地合并cluster,具体而言,就是每次找到距离最短的两个cluster,然后进
行合并成一个大的cluster,直到全部合并为一个cluster。整个过程就是建立一个树结构,类似于下图。
Canopy算法的主要思想:
首先定义两个距离T1和T2,T1>T2.从初始的点的集合S中随机移除一个点P,然后对于还在S中的每个点I,计算该点I与点P的距离,如果距离小于T1,则将点I加入到点P所代表的Canopy中,如果距离小于T2,则将点I从集合S中移除,并将点I加入到点P所代表的Canopy中。迭代完一次之后,重新从集合S中随机选择一个点作为新的点P,然后重复执行以上步骤。
Canopy算法执行完毕后会得到很多Canopy,可以认为每个Canopy都是一个Cluster,与KMeans等硬划分算法不同,Canopy的聚类结果中每个点有可能属于多个Canopy。我们可以选择距离每个Canopy的中心点最近的那个数据点,或者直接选择每个Canopy的中心点作为KMeans的初始K个类簇中心点。
平均质心距离的加权平均值
首先随机选出一个点,然后选取离这个点距离最大的点作为第二个点,再选出离这两个点距离最小值最大的点作为第三个点,以此类推选出K个点
K值的确定
这里我们需要调试K值对于结果进行评测,从而判断最优K值,并将其应用到实际的模型中。
给定一个合适的类簇指标,比如平均半径或直径,只要我们假设的类簇的数目等于或者高于真实的类簇的数目时,该指标上升会很缓慢,而一旦试图得到少于真实数目的类簇时,该指标会急剧上升。
类簇的直径是指类簇内任意两点之间的最大距离,类簇的半径是指类簇内所有点到类簇中心距离的最大值
“距离最近”原则具体指什么?
即两两数据之间的相似度,可参考我的这篇博客 点击阅读
怎么更新簇类中心?
求平均值,需要说明一点的是这里的平均值并不一定是实实在在存在的数据,很大程度上就是虚拟的一个数据,比如说我们对二维平面上的点进行聚类时,更新簇类中心就不是原数据中的某个点,同样对于用户对item进行评分时的数据聚类,更新簇类中心后的item也并不是一个真正的item,而是虚拟出的一个。
判断簇类收敛到不再改变的条件是什么?
一般情况下判断聚类stop的条件是 聚类结果不再发生变化,但是对于始终无法停止的聚类的数据,就要额外的添加一些约束条件来迫使停止聚类,比如说更新簇类中心前后的新旧簇类中心相似度大于90%,距离小于10%等。
如何对用户评分数据集进行合理的分类
数据集说明
http://www.letiantian.me/2014-11-20-introduce-movielens-dataset/
算法说明
这里采用的是k-means进行聚类,初始聚类中心为7个,当然可以自己设定,选取k个初始簇类中心的原则是,评分最多的k个item,“距离最近”原则采用的计算方法是余弦值法。
代码如下
# coding: utf-8
from numpy import *
from math import *
import cPickle as pickle
import os
class Kmeans:
def __init__(self, filepath, n_clusters, user_num,item_num):
self.filepath = filepath # 评分数据的路径
self.n_clusters = n_clusters # 聚类中心的数目
self.user_num = user_num # 用户数目
self.item_num = item_num # item 数目
self.dataSet = self.loadData() # 评分矩阵
self.CC = self.randCent() # 初始化随机产生的聚类中心
self.CC_new = {}
self.C = {} # 簇类集 簇集item id
self.C_new = {} # 簇类集 打分
# 构建评分矩阵
def loadData(self):
dataSet = zeros((self.item_num,self.user_num))
with open(self.filepath, 'r') as fr:
for line in fr.readlines():
curLine = line.strip().split("\t")
dataSet[ int(curLine[1])-1, int(curLine[0])-1 ] = int(curLine[2])
return dataSet
# 选取初始聚类中心
# 以评分数量最多的k个item作为初始的聚类中心
def randCent(self):
CC_item_dic = {}
CC = {}
for i in range(self.item_num):
CC_item_dic[ i ] = len(nonzero(self.dataSet[i,:])[0])
CC_item_dic = sorted(CC_item_dic.iteritems(), key = lambda one:one[1], reverse=True)
for item in CC_item_dic[:self.n_clusters]:
CC[item[0]] = self.dataSet[item[0],:]
return CC
# 计算相似度
def distances(self,item_id,cc_id):
sum_fenzi = 0.0
sum_fenmu_1, sum_fenmu_2 = 0,0
for i in range(len(self.dataSet[item_id])):
sum_fenzi += self.dataSet[item_id][i]*self.CC[cc_id][i]
sum_fenmu_1 += self.dataSet[item_id][i]**2
sum_fenmu_2 += self.CC[cc_id][i]**2
return sum_fenzi/( sqrt(sum_fenmu_1) * sqrt(sum_fenmu_2) )
def kmeans(self):
clusterChanged = True # 标志变量,若为true,则继续迭代
while clusterChanged:
for item_id in range(self.item_num):
max_cos = -inf # inf 为无穷大
clusterIndex = -1 # 创建索引,用来记录归属到哪个簇集
for cc_id in self.CC.keys():
cos = self.distances(item_id,cc_id)
if cos > max_cos:
max_cos = cos
clusterIndex = cc_id
self.C.setdefault(clusterIndex,[]).append(item_id)
self.C_new.setdefault(clusterIndex,[]).append(self.dataSet[item_id])
# 更新簇类
for item_cid in self.C_new.keys():
for col in range(self.user_num):
self.CC_new.setdefault(item_cid,[]).append( sum( mat( self.C_new[item_cid] ).T[col] )/len( mat( self.C_new[item_cid] ).T[col] ) )
for item_cid_new in self.CC.keys():
if (self.CC[item_cid_new] - self.CC_new[item_cid_new]).all(): # false 相等
self.CC = self.CC_new
break
else:
clusterChanged = False
return 1
def save(self):
if os.path.exists("file/dataMatrix.dat"):
os.remove("file/dataMatrix.dat")
pickle.dump(self.dataSet,open("file/dataMatrix.dat","wb"),True) # pickle.load(open("file/dataMatrix.dat","rb"))
if os.path.exists("file/clusterResult.dat"):
os.remove("file/clusterResult.dat")
pickle.dump(self.C,open("file/clusterResult.dat","wb"),True) # pickle.load(open("file/clusterResult.dat","rb"))
if __name__ == '__main__':
k_means = Kmeans('file/u.data', n_clusters =7,user_num = 943, item_num = 1682)
k_means.kmeans()
k_means.save()
print 'cluster over!'聚类结果的评价
这篇文章总结的还算简单清楚:
http://blog.csdn.net/u012102306/article/details/52423074