【计算机科学】【2014.09】多步超前时间序列预测的机器学习策略
本文为比利时布鲁塞尔自由大学(作者:Souhaib Ben Taieb)的博士论文,共201页。
接下来的24小时要用多少电?接下来三天的温度是多少?未来几个月某一产品的销售量是多少?回答这些问题通常需要根据给定的历史观测序列(称为时间序列)预测若干未来观测值。历史上,时间序列预测主要用于研究计量经济学和统计学。在过去的二十年里,机器学习作为一个研究自动从数据中学习的算法领域,已经成为预测建模研究中最活跃的领域之一。这种成功很大程度上归功于机器学习预测算法在自然语言处理、语音识别和垃圾邮件检测等许多不同应用中的卓越性能。然而,在时间序列预测和机器学习的交叉点上却鲜有研究。
本文的目标是从机器学习的角度解决多步提前时间序列预测问题,以缩小这一研究上的差距。为此,我们提出了一系列基于机器学习算法的预测策略。多步超前预报可以通过迭代单步超前模型递归生成,也可以直接使用每个时间段的特定模型生成。作为第一个贡献,我们进行了深入的研究,以比较递归和直接预测生成的不同学习算法、不同的数据生成过程。更准确地说,我们将多步均方预测误差分解为偏差和方差分量,并分析它们在不同时间序列长度下的预测范围内的行为。本文的研究和观察结果将指导我们制定新的预测策略。特别是,我们发现在递归预测和直接预测之间进行选择并不是一件容易的事情,因为它涉及到偏差和估计方差之间的权衡,这取决于许多相互作用的因素,包括学习模型、基础数据生成过程、时间序列长度和预测时间范围。
作为第二个贡献,我们开发了多阶段预测策略,这些策略不将递归和直接策略视为竞争对手,而是寻求组合它们的最佳特性。更准确地说,多阶段策略生成递归线性预测,然后通过在每个视角上用直接非线性模型(称为校正模型)建模多步预测残差来调整这些预测。我们提出了第一个多阶段策略,我们称之为校正策略,它使用最近邻模型估计校正模型。然而,由于递归线性预测通常需要对实际时间序列进行小的调整,我们还考虑了第二个多阶段策略,称为boost策略,该策略使用所谓弱学习者的梯度boosting算法来估计校正模型。在每个视角使用不同的模型生成多步预测提供了很大的建模灵活性。然而,单独选择这些模型可能会导致预测中的不规则现象,从而增加预测方差。由短时间序列估计的非线性机器学习模型加剧了这一问题。
为了解决这个问题,作为第三个贡献,我们引入并分析了多视角预测策略,在学习每个视角的模型时,利用其他视角中包含的信息。特别是,为了选择每个模型的滞后阶和超参数,多视角策略将多视角上的预测误差最小化,而不仅仅是关注单个视角。我们将所有提出的策略与递归策略和直接策略进行了比较。首先应用偏差和方差研究,然后使用来自过去两个预测比赛的真实时间序列来评估不同的策略。对于校正策略,除了避免了递归预测和直接预测之间的选择外,结果表明,在不同的情况下,它比递归预测和直接预测有更好的或至少接近的性能。对于多视角策略,研究结果强调了与单视角策略相比,特别是在线性或弱非线性数据生成过程中方差的减小。总的来说,我们发现,如果使用适当的预测策略来选择模型参数并生成预测,基于机器学习算法的多步超前预测的准确性可以显著提高。
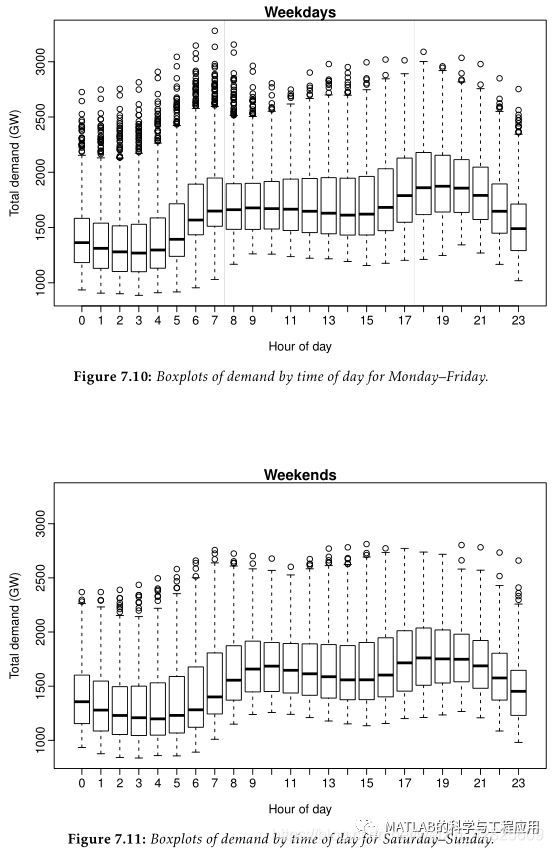
最后,作为第四个贡献,我们参加了2012年全球能源预测竞赛的负荷轨迹预测。这场竞赛涉及一个层次化的负荷预测问题,在这个问题上,我们需要对一家美国公用事业公司的20个地理区域的每小时负荷进行预测。我们团队TinTin在105个参赛团队中排名第五,获得了IEEE电力与能源协会奖。
How much electricity is going to beconsumed for the next 24 hours? What will be the temperature for the next threedays? What will be the number of sales of a certain product for the next fewmonths? Answering these questions often requires forecasting several futureobservations from a given sequence of historical observations, called a timeseries. Historically, time series forecasting has been mainly studied ineconometrics and statistics. In the last two decades, machine learning, a fieldthat is concerned with the development of algorithms that can automaticallylearn from data, has become one of the most active areas of predictive modelingresearch. This success is largely due to the superior performance of machinelearning prediction algorithms in many different applications as diverse asnatural language processing, speech recognition and spam detection. However,there has been very little research at the intersection of time seriesforecasting and machine learning. The goal of this dissertation is to narrowthis gap by addressing the problem of multi-step-ahead time series forecastingfrom the perspective of machine learning. To that end, we propose a series offorecasting strategies based on machine learning algorithms. Multi-step-aheadforecasts can be produced recursively by iterating a one-step-ahead model, ordirectly using a specific model for each horizon. As a first contribution, weconduct an in-depth study to compare recursive and direct forecasts generatedwith different learning algorithms for different data generating processes.More precisely, we decompose the multi-step mean squared forecast errors intothe bias and variance components, and analyze their behavior over the forecasthorizon for different time series lengths. The results and observations made inthis study then guide us for the development of new forecasting strategies. Inparticular, we find that choosing between recursive and direct forecasts is notan easy task since it involves a trade-off between bias and estimation variancethat depends on many interacting factors, including the learning model, theunderlying data generating process, the time series length and the forecasthorizon. As a second contribution, we develop multi-stage forecastingstrategies that do not treat the recursive and direct strategies ascompetitors, but seek to combine their best properties. More precisely, themulti-stage strategies generate recursive linear forecasts, and then adjustthese forecasts by modeling the multi-step forecast residuals with directnonlinear models at each horizon, called rectification models. We propose afirst multi-stage strategy, that we called the rectify strategy, whichestimates the rectification models using the nearest neighbors model. However,because recursive linear forecasts often need small adjustments with real-worldtime series, we also consider a second multi-stage strategy, called the booststrategy, that estimates the rectification models using gradient boostingalgorithms that use so-called weak learners. Generating multi-step forecastsusing a different model at each horizon provides a large modeling flexibility.However, selecting these models independently can lead to irregularities in theforecasts that can contribute to increase the forecast variance. The problem isexacerbated with nonlinear machine learning models estimated from short timeseries. To address this issue, and as a third contribution, we introduce andanalyze multi-horizon forecasting strategies that exploit the informationcontained in other horizons when learning the model for each horizon. Inparticular, to select the lag order and the hyperparameters of each model, multi-horizonstrategies minimize forecast errors over multiple horizons rather than just thehorizon of interest. We compare all the proposed strategies with both therecursive and direct strategies. We first apply a bias and variance study, thenwe evaluate the different strategies using real-world time series from two pastforecasting competitions. For the rectify strategy, in addition to avoiding thechoice between recursive and direct forecasts, the results demonstrate that ithas better, or at least has close performance to, the best of the recursive anddirect forecasts in different settings. For the multi-horizon strategies, theresults emphasize the decrease in variance compared to single-horizonstrategies, especially with linear or weakly nonlinear data generatingprocesses. Overall, we found that the accuracy of multi-step-ahead forecastsbased on machine learning algorithms can be significantly improved if anappropriate forecasting strategy is used to select the model parameters and togenerate the forecasts. Lastly, as a fourth contribution, we have participatedin the Load Forecasting track of the Global Energy Forecasting Competition2012. The competition involved a hierarchical load forecasting problem where wewere required to backcast and forecast hourly loads for a US utility withtwenty geographical zones. Our team, TinTin, ranked fifth out of 105participating teams, and we have been awarded an IEEE Power & EnergySociety award.
- 引言
- 项目背景
- 多步超前时间序列预测策略综述
- 多步预测的偏差与方差分析
- 多级预测策略
- 多视角预测策略
- 2012年全球能源预测竞赛
- 结论与未来方向预测
附录A 真实实验
附录B 仿真的时间序列
更多精彩文章请关注公众号: