不懂fork和fsync?你怕是学的假Redis持久化机制
熟悉 redis 都知道,redis 持久化有 RDB 和 AOF 两种,一种是记录数据,另一种是记录操作。
不过一方面,为了学习的纵向拓深、横向延展,提高思维开阔性和学习态度严谨性,以便足以在实际环境中对这些特性运用自如;
另一方面,为了能和面试官去喷。。
我们必须对持久化机制做深入地探讨。
RDB 的问题
我们先从 RDB 说起。
首先,我们都知道,RDB 是对数据的全量复制,我们一般都会在特定时间点对数据进行备份。
比如,每天 12 点准时备份;
或者,业务量更大的公司,每隔一个小时,就对数据进行一次备份。
不过,你觉得这有没有什么潜在的问题?
如果你不觉得,那你确实有必要好好探究一下了。
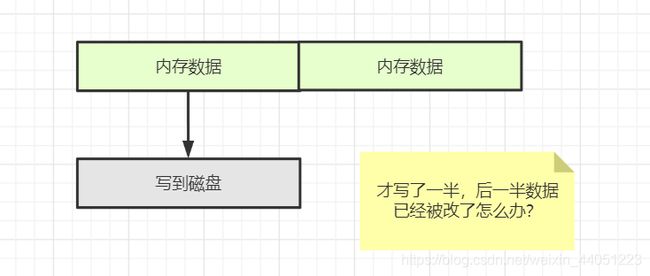
最明显的问题,就是时点性的问题:
比如,12 点的时候,准时 RDB 全量数据到磁盘。
但是
- 12 点开始,12 点就立即结束?
- 持久化涉及硬盘 I/O,那么速度绝对比内存要慢得多;
那么等你真正加载到硬盘,那时间绝对不止 12 点准时了; - 那算几点?
比如加载到了 13 点,你算 12 点的数据吗?
就算是 13 点的数据,可明明 12 点就开始存储了! - 再说,你持久化的时候,需要阻塞 redis 吗?也就是还可以继续写数据吗?
- 如果可以,那么数据就在动态变化,你存储的数据就不会是 12 点的真实数据,而是 12 点到 13 点整个时段内的数据
- 如果不可以,选择阻塞,那么 redis 服务直接不可用;
如果都不可用了,那对高并发系统的打击那是巨大的。
先不谈如何解决,但至少首先我们要保证的是,系统可用 !
这时毋庸置疑的。
对于我们的高并发系统而言,大多数互联网项目,第一要保证的就是可用性;
然后我们再去想,如何保证数据的时点性。
如何保证时点性
首先,我们都知道,RDB 有两种方式:
- 一种是 save:阻塞直到数据存储完毕;
- 另一种 bgsave:后台另起一线程去执行写磁盘操作。
首先,save 直接不管,没问题吧。
这年头,哪个互联网公司敢让 redis 直接阻塞,去 RDB 的。
我们只看 bgsave。
首先,假设,我们要另起一个线程,来复制我们的 redis,
根据之前提及的,由于 redis 并没有阻塞,此时还可以正常提供服务,所以就很可能有很多的写操作。
那么这时另一个线程写的数据就会被改变,因此时点性就会遭到破坏。
那么,为了保证数据的时点性,准确无误。(而且 redis 也确实是做到了)
于是,我们想到的方式,一般都是想到,创建后台线程的同时,将所有数据,拷贝给这一个线程,
这样,线程之间的数据,就会互不干扰,因此不会出现错误。
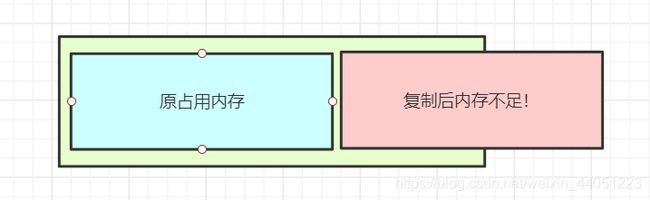
但是,假设一个 redis 有 6 个 G,一台机器一共只有 8 个 G,
那么,redis 该怎么办?
此时,要是拷贝数据,整个机器的内存就会直接不够用了!
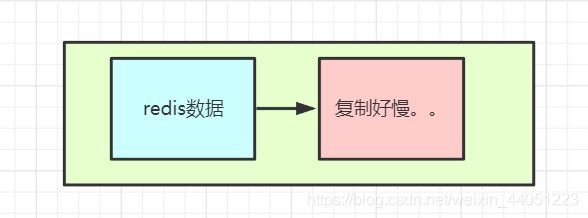
就算,内存足够用,但是,拷贝好几个 G 的数据,虽然在内存,但是需要花费多少的时间?
虽然内存的带宽,比起磁盘快了很多,可以达到 G/s,
但是,面对几个 G 的数据,仍然会有短暂的卡顿现象出现,
这对于高并发的互联网系统,是影响很大的。
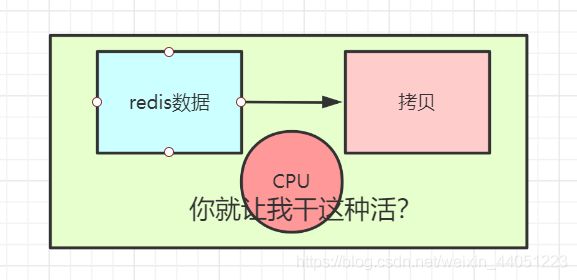
还有一点,就是在内存中拷贝大量的数据,也是需要消耗大量的 CPU 资源的。
而 redis 就是以快作为核心。
此时,CPU 资源大量消耗,redis 的性能也就会受到影响,
因此,这也是非常不乐观的。
那么?
redis 到底是怎么做的?
写时复制
其实,对于时点性问题,redis 并没有做什么复杂的操作。
这归功于 Linux 系统的 fork() 函数。
所以,如果你了解 Linux 的话,你就会发现,这确实非常简单。
首先,Linux 中的线程实际上就是一个进程,不过它们共享了一部分资源,
在 Linux 中创建进程,一般会用 fork() 这个系统调用,
这个系统调用,将会创建出一个进程,并且,这个进程和父进程共享数据。
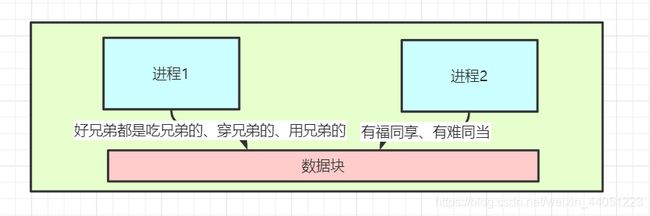
但是,Linux 用了一个很巧妙的办法,来防止数据冲突:
就是,在一开始,父子进程对这些数据都只是可读的,
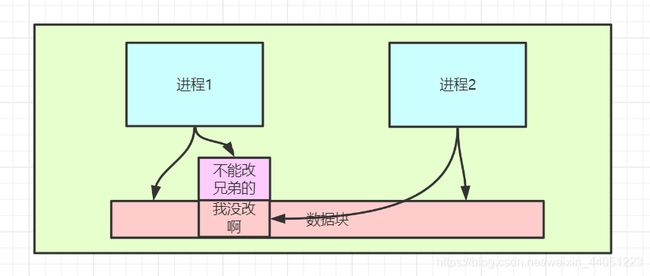
一旦,一个进程发生了写操作(不管是父进程、还是子进程),
这个数据就会被拷贝到另一个地址空间,然后被该线程引用。
也就是,只有写的那一些数据才会被拷贝,而其它大部分的数据,都不会发生拷贝,
因此,性能得以提高。
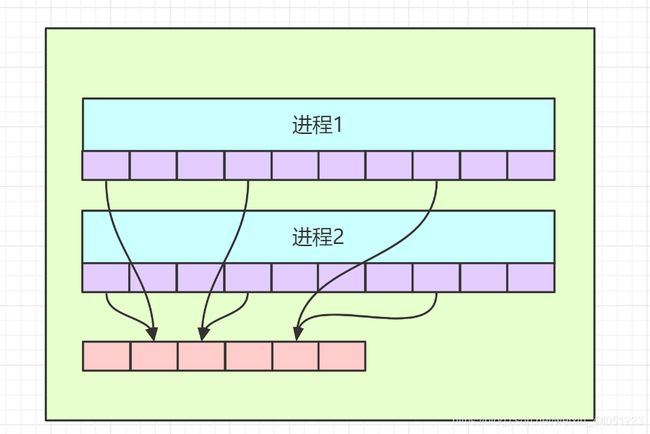
而这一点的实现,还归功于操作系统的内存映射机制。
其实,我们的用户进程,它们看到的内存地址,都不是真正的内存地址,而是操作系统给虚幻出来的一个地址。
这样,操作系统,就可以对进程的内存进行控制和管理;
而在编写程序时,也不用考虑实际的物理地址,从而可以更自由,甚至使用比实际更大的内存空间。

而在 fork() 进程时,子进程的虚拟地址空间,完全可以和父进程的虚拟地址空间一样,
而等到写操作产生时,虚拟地址空间还可以不用改变,而只是改变了实际的物理内存地址空间,
这对于进程来说,是透明的。
合理利用 RDB
既然 RDB 的原理,我们明白了,
但是,RDB 存在什么问题吗?或者说有什么缺点吗?
首先就是不支持拉链。
就是 RDB 文件永远只有一个,这样,一旦生成新版本,就版本就会丢弃,
所以这时候,就要我们人为地去把 RDB 文件拷贝出去。
不过,也正因为其简单,也不管历史版本,所以速度也就快。
第二,由于 RDB 是持久化,所以肯定会花费时间。
假设,一个 redis,我们整一台好机器,给它来个一百多两百多 G,
那么,光一个 RDB 持久化,就可能花掉很久很久的时间。
所以,我们一般给一个 redis 的内存,不会太大,几个 G 就差不多了,
这样,redis 就会更轻盈,做什么都会特别快。
这样,速度的特性就能更好地发挥出来。
第三,就是 RDB 特有的一个特点。
就是,因为只在时点存储数据,比如每隔两小时,
那么,假设 9 点做一次 RDB,10 点 redis 挂了,那么,就会丢失一小时的数据。
这是时点性间隔存储无法保证的,就是不解决丢数据的事。
不过,RDB 也是有很多优点的。
第一,就是 RDB 是 redis 数据的非常紧凑的单文件时间点表示。
因此 RDB 文件非常适合备份。
比如,你可能希望在最近的 24 小时内每小时存档一次 RDB 文件,并在 30 天之内每天保存一次 RDB 快照,
这样,就可以在灾难情况下轻松还原数据集的不同版本。
第二,RDB 对 redis 的性能影响较小,它做的仅仅只是创建出一个子进程,由子进程来进行持久化,
而 redis 工作进程,完全不用去关心任何持久化的事。
第三,也是 RDB 的最显著的优势,就是恢复速度快。
因为是存储的全二进制数据,因此,只需要读到内存,就可以直接使用了。
而不像 AOF,是记录的指令,因此恢复就要一条条指令进行恢复。
AOF
AOF 这个名字很好理解,就是 append only file,就是指向文件追加,
就是把 redis 的写操作记录到文件中。
这么一听就会感觉到有个好处,就是 redis 的每个写,都会进行追加,那么丢失数据就会相对少。
第二个常识就是,redis 当中,RDB 和 AOF 功能可以同时开启,但是!!
如果开启了 AOF,那么就只会用 AOF 恢复。
也就是说,服务器重启的时候,恢复的数据一定是从 AOF 来的,也就是 RDB 的数据不会被用来恢复。
好了,现在 AOF 你可以大概理解是什么了。
无限增长问题
现在,我提出一个问题:
假设,我现在有一个 redis,运行了 10 年,且持久化方案是开启了 AOF,
那么,请问,10 年之后,redis 挂了。
那么,AOF 有多大?
第二,恢复要多久?
首先,这个 10 年,redis 一直在进行增删改的操作,
那么,10 年之后,这个 AOF,就要包含记录着这 10 年,它所有做过的写操作。
那么,这个 AOF,是不是得非常大?
假设,有一个哥们,很无聊,每天就是不断地做着同一个操作:
创建 key
删除 key
那么,10 年过后,这个 AOF 就记录着大量的操作,虽然说都相同,但是记录都在,所以这个 AOF 就会非常大。
第二,那么恢复的时候,redis 会不会溢出?
假设,这个 AOF 记了 10 年,已经 10T 的大小了,那么恢复的时候,会不会溢出?
其实,这个应该很好理解,虽然 AOF 很大,但是,所有的操作,都是在 redis 内存空间足够的情况下写进去的;
也就是,只要之前 redis 内存足够,那么,恢复的时候,虽然看起来 AOF 很大,但是,实际上恢复出最终的数据,还是 redis 之前内存中存在的数据;
所以,只要之前的 redis 内存没问题,足够,那么现在也不可能溢出。
第三,就是一个很关键的问题,恢复要多久?
再回到刚才这个例子,10 年一共就一条数据,创建删除、创建、删除……
但是,虽然一条数据,但是,AOF 记录的是写的操作,它不知道最终结果是什么,
所以每一个命令,它都要去复现,操作一遍。
所以,就相当于把之前 10 年 redis 的所有写操作重新做一遍,这样就变成了最终的数据。
那么,所以,这样一定很慢对不对?
假设记了 10 年,要是一直是不停地在写,那么,恢复,重新写一遍所有的操作,那么,说不定也要个好几年对不对?
所以,这就凸显除了 AOF 的缺点:
- 体量无限增大
- 恢复速度慢
当然,其实体量大也是一个优点对不对,因为全,丢失数据少。
AOF重写
所以,很多软件,都会对日志下手,
因为,日志的优点保住,还是不错的,就是可以尽量不丢失数据,
并且,同时克服一下它的缺点,就是把体量变小,恢复变快。
所以,redis 的也采取了一定的做法:
在 4.0 以前,有一个机制叫做重写。
比如,回到之前的例子,不断创建 key,删除 key;
那么,你可以发现,这样的操作,都可以抵消,对不对。
再比如,假设有一个 list,你不断往里面 push 1W 个 v,
那么,是不是就可以只写一条 push 语句,然后让它执行 1W 次就 ok?
所以,总结一下,就是:
删除抵消的,合并重复的。
所以,现在也知道了,最终得到的也是一个纯指令的 AOF 文件,
虽然指令被削减了一部分,但是纯指令,还是得一条条去恢复,所以效率还是有些低的。
所以,后来,redis 偷偷地学习了 hdfs 的优点,
就是,从 4.0 版本开始,AOF 会包含 RDB 全量,然后追加新的写操作。
而包含一个 RDB 全量之后,就可以直接把数据给导入内存即可,不用一步一步的操作。
而追加的一部分写操作,又可以保证数据的全。
所以在重写的时候,会先把老的数据,以 RDB 的形式,存到 AOF 文件中,
然后,再把增量的,以指令的方式存入 AOF。
所以,AOF 就会包含二进制数据和增量的日志,于是就成了一个混合体。
于是,这么改进,AOF 就把两个优点都占有了:
- 既有 RDB 的快;
- 又有 AOF 的全。
fsync的间隔
这样,明白了 AOF 之后,我们继续回头。
redis 既然是一个内存级 kv 数据库,那么,这时写操作就会触发 I/O,
那这样的话,就会影响 redis 的写速度,就会变慢。
所以,redis 给了 3 个级别:
- NO
- ALWAYS
- everysec
首先,如果你还不知道 fsync 是什么,那我得先简单描述一下:
传统的 UNIX 实现在内核中设有缓冲区高速缓存或页面高速缓存,大多数磁盘 I/O 都通过缓冲进行。
当将数据写入文件时,内核通常先将该数据复制到其中一个缓冲区中,如果该缓冲区尚未写满,则并不将其排入输出队列,而是等待其写满或者当内核需要重用该缓冲区以便存放其他磁盘块数据时,再将该缓冲排入输出队列,然后待其到达队首时,才进行实际的 I/O 操作。
这种输出方式被称为延迟写(delayed write)
延迟写减少了磁盘读写次数,但是却降低了文件内容的更新速度,于是,就可能使得写到文件中的数据在一段时间内并没有写到磁盘上。
这样,当系统发生故障时,这种延迟可能造成文件更新内容的丢失。
所以,redis 给出的三个级别,就是让我们在数据可能丢失的数量、和性能之间,做出一个权衡。
假设,我们采用 NO,从不手动将数据刷入磁盘,
无疑,由于不用一直写磁盘,所以 redis 的性能,一定是最高的。
但是,这样,就只有在缓冲区满了的时候,才会刷数据到磁盘。
于是,在宕机的时候,会丢失的数据,则会有很多。
假设,我们采用 ALWAYS,每次写,都将指令追加到 AOF。
这样,我们最多最多,丢失一条数据(就是最后哪一条还没来得及写进磁盘的时候)。
但是,由于每笔操作都往磁盘刷写,那性能一定是会受到很大的影响。
所以,很多时候,会倾向于使用 everysec,每秒。
这样的话,由于不会次次写磁盘,所以对性能的影响还不至于那么大,
而且,时间间隔也只有一秒,即使丢失,影响也不会太大。
所以,这往往作为一个折中方案。
写在最后
其实,很多时候,我们在学习知识,不能够浮于表面,要理清其中的原理细节,才能把这些知识掌握好。
比如,光是 Redis 的持久化,RDB 涉及到 Linux 的 fork() 原理;
AOF 的三种 fsync 等级,也涉及到了缓冲区、延迟写。
如果你对这些知识点不明白,那么,你就会对持久化的命令一知半解,
于是,就难以去很好地发挥其特性和优势。
当然,不仅仅是 Redis 的持久化,很多时候,我们都会涉及到一些看似没有,但在底层又确确实实存在的问题。
比如线程的调度,系统调用,网络原理等等,这些都会或多或少影响到我们的程序。
因此,我们需要知其然,并知其所以然,这样,才能真正使用好我们的技术。